



AI Sheets 是 Hugging Face 推出的开源工具。用户无需编写代码,就能用 AI 模型构建、丰富和转换数据集。它支持本地部署或在 Hugging Face Hub 上运行。工具连接 Hugging Face Hub 的数千个开源模型,通过 Inference Providers 访问这些模型。用户也可以用本地模型,包括 OpenAI 的 gpt-oss。界面像电子表格一样简单。用户通过编写提示创建新列,能快速实验小数据集,再扩展到大管道。工具强调迭代,用户编辑单元格或验证结果来教导模型。核心是使用 AI 处理数据,从分类到生成合成数据。适合测试模型、改进提示和分析数据集。导出结果到 Hub,还生成配置用于扩展数据生成。
功能列表
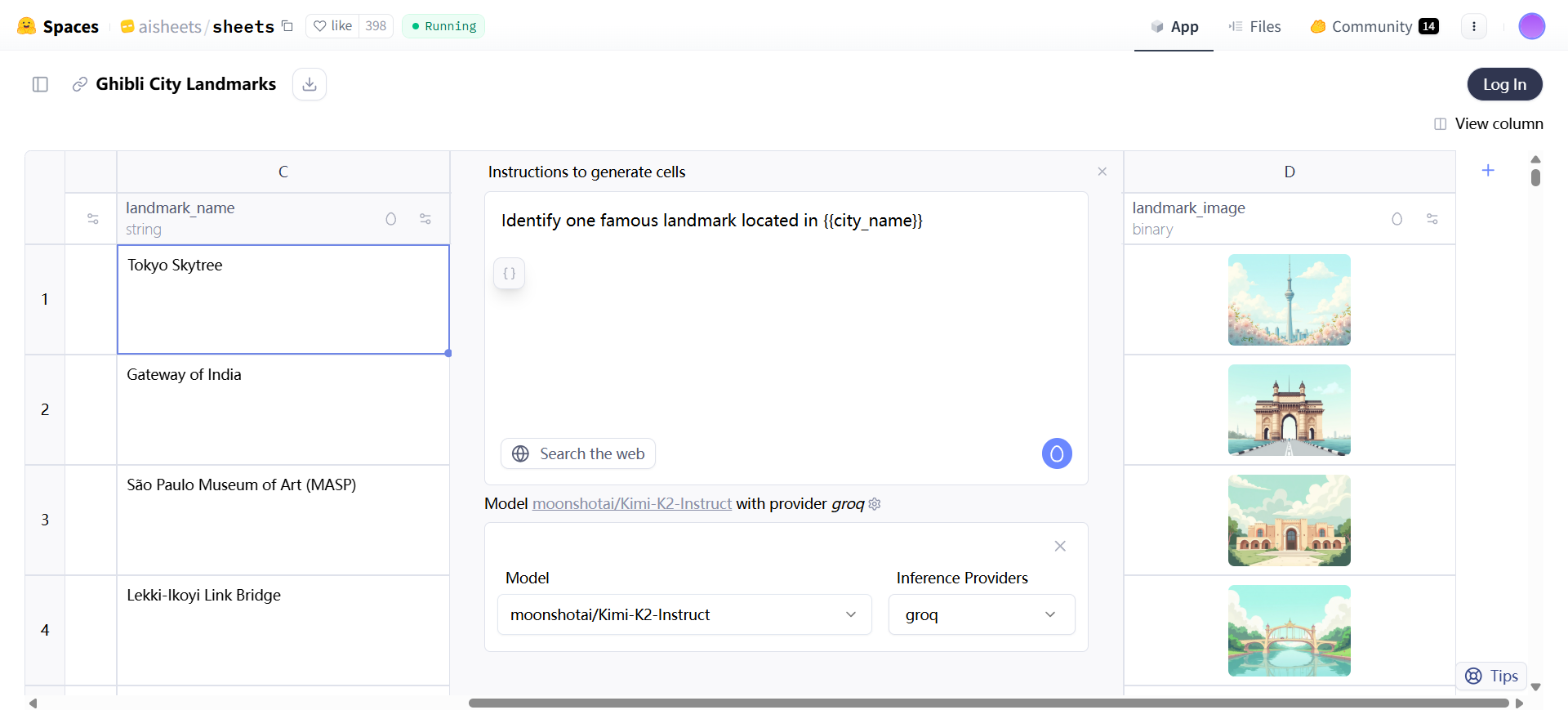
- 数据集从零生成:输入自然语言描述,AI 自动创建结构和样本行,如生成城市列表包括国家、地标图像。
- 数据导入和处理:上传 XLS、TSV、CSV 或 Parquet 文件,支持最多 1000 行,无限列,能编辑和扩展数据。
- 添加 AI 列:用提示创建新列,如提取信息、总结文本、翻译内容或自定义操作,引用现有列如 {{column}}。
- 模型选择和切换:从 Hugging Face Hub 选模型和提供商,如 meta-llama/Llama-3.3-70B-Instruct 或 openai/gpt-oss-120b,测试不同性能。
- 反馈机制:手动编辑单元格或点赞好结果,这些作为 few-shot 示例,重新生成时改善输出。
- 网络搜索开关:启用时模型从 web 获取最新信息,如查找地址的邮编;禁用时只用模型知识。
- 数据扩展:拖拽列生成更多行,无需再生;用于修复错误或添加数据。
- 导出到 Hub:保存数据集和配置 YAML 文件,用于复用提示或通过脚本生成更大数据集。
- 模型比较和评估:创建多列测试不同模型,用 LLM 作为评判列比较输出质量。
- 合成数据生成:创建虚拟数据集,如专业电子邮件基于人物传记。
- 数据转换和清理:用提示移除标点或标准化文本。
- 数据分类和分析:分类内容或提取主要想法。
- 数据丰富:补充缺失信息,如添加邮编或生成描述。
- 图像生成:用模型如 black-forest-labs/FLUX.1-dev 创建图像列,支持特定风格。
使用帮助
AI Sheets 的使用从启动开始。用户有两种方式进入:在线试用或本地安装。在线试用无需安装。访问 https://huggingface.co/spaces/aisheets/sheets。登录 Hugging Face 账户。获取 HF_TOKEN 从 https://huggingface.co/settings/tokens。界面出现后,选择生成新数据集或导入现有数据。
生成数据集从零开始适合初次熟悉工具、脑暴或快速实验。点击生成选项。在提示区输入描述,如“世界城市列表,包括所属国家和每个地标的 Ghibli 风格图像”。AI Sheets 会创建 schema 和 5 行样本。结果有列如城市、国家、图像。拖拽列底部生成更多行,最多 1000 行。修改提示重新生成结构。手动输入单元格,再拖拽完成其他列。
导入数据集推荐用于大多数情况。上传文件格式为 XLS、TSV、CSV 或 Parquet。文件需有至少一列名和一行数据。上传后数据显示在表格中。手动添加条目到空单元格。界面像 spreadsheet,可编辑导入单元格,但 AI 不能改动它们。AI 生成单元格可再生。
添加新列是核心操作。点击 + 按钮。选推荐动作如提取信息、总结文本、翻译,或自定义提示如“从 {{text}} 中移除多余标点”。{{text}} 引用现有列。配置模型,如选 meta-llama/Llama-3.3-70B-Instruct,提供商如 groq。开关搜索:启用拉取 web 数据,如“查找 {{address}} 的邮编”。生成列后,查看结果。
精炼数据集通过反馈和配置。手动编辑 AI 单元格,提供首选输出示例。点赞好结果用 thumbs-up。这些作为 few-shot 示例。点击再生应用到全列。调整提示,如改“分类 {{text}}”为更具体版本。切换模型测试性能,如从 groq 换 cerebras。不同模型适合不同任务,如创意或结构化输出。提供商影响速度和上下文长度。
扩展数据用拖拽。从列最后单元格向下拉,即时生成新行。无需再生。修复错误单元格也用此法。
导出到 Hub 保存工作。点击导出。生成数据集和 config.yml 文件。文件包含列配置、提示、模型细节。示例 config 有 columns 键,列出每个列的 modelName、userPrompt 等。上传后可在 Hub 查看,如 https://huggingface.co/datasets/dvilasuero/nemotron-personas-kimi-questions。
生成更大数据集用 HF Jobs。需 config 和脚本。命令如:hf jobs uv run -s HF_TOKEN=$HF_TOKEN https://huggingface.co/datasets/aisheets/uv-scripts/raw/main/extend_dataset/script.py –config https://huggingface.co/datasets/dvilasuero/nemotron-personas-kimi-questions/raw/main/config.yml –num-rows 100 nvidia/Nemotron-Personas dvilasuero/nemotron-kimi-qa-distilled。指定行数或留空生成全部。
本地安装从 GitHub。克隆 https://github.com/huggingface/aisheets。设置 HF_TOKEN。用 Docker:export HF_TOKEN=your_token_here; docker run -p 3000:3000 -e HF_TOKEN=$HF_TOKEN huggingface/sheets。访问 http://localhost:3000。用 pnpm:安装 pnpm,克隆仓库,export HF_TOKEN,pnpm install,pnpm dev。访问 http://localhost:5173。生产构建:pnpm build,pnpm serve。
用自定义 LLM 如 Ollama。启动 Ollama server:export OLLAMA_NOHISTORY=1; ollama serve; ollama run llama3。设置 MODEL_ENDPOINT_URL=http://localhost:11434,MODEL_ENDPOINT_NAME=llama3。运行 app。自定义需符合 OpenAI API。图像生成固定用 Hugging Face API。
高级配置用环境变量。OAUTH_CLIENT_ID 为认证。DEFAULT_MODEL 改默认模型。NUM_CONCURRENT_REQUESTS 控制并发,默认 5。SERPER_API_KEY 启用搜索。DATA_DIR 设数据目录。
操作流程示例:测试模型。导入含提示的数据集。加列用“回答:{{prompt}}”,选不同模型。加评判列如“评估 {{prompt}} 的响应1:{{model1}},响应2:{{model2}}”。手动检查或用 LLM 判优。
分类数据集:上传文本数据集。加列“分类 {{text}} 的主要主题”。编辑坏结果,点赞好,再生。
合成数据:生成人物 bio 列“写制药公司专业人士简短描述”。加邮件列“写 {{person_bio}} 的真实专业邮件”。
分析:加列“从 {{text}} 提取关键想法”。
丰富:加列“查找 {{address}} 的邮编”,启用搜索。
这些步骤让用户直接上手。工具强调实验和迭代,确保数据质量。
应用场景
- 模型测试和比较
用户想在自家数据上试最新模型。导入含问题的数据集。创建多列,每列用不同模型回答。加评判列用 LLM 比较质量。适合开发者选最佳模型。 - 提示优化
构建客户请求自动回答应用。加载样本请求数据集。迭代不同提示和模型生成响应。编辑单元格提供反馈,自动加 few-shot 示例。适合构建高效提示。 - 数据清理和转换
数据集列有杂乱文本。加新列用提示移除标点或标准化。快速处理大批量数据。适合数据科学家预处理。 - 数据分类
分类内容如问题主题。加列用提示分类。手动验证并再生改善准确。适合分析 Hub 数据集。 - 数据分析和提取
提取文本主要想法。加列用提示总结或提取。启用搜索拉实时信息。适合研究项目。 - 数据丰富
补充缺失如地址邮编。加列用提示查找,启用 web 搜索。确保准确补充。适合完整数据集。 - 合成数据生成
需隐私保护的虚拟数据如邮件。生成 bio 列,再基于它生成内容。适合测试或原型。
QA
- AI Sheets 支持哪些模型?
支持 Hugging Face Hub 的开源模型,通过 Inference Providers。也可本地模型如 gpt-oss 或符合 OpenAI API 的自定义 LLM。 - 如何生成图像列?
用提示如“生成 {{object_name}} 的等距图标”,选图像模型如 black-forest-labs/FLUX.1-dev。固定用 Hugging Face API。 - 反馈如何工作?
编辑 AI 单元格或点赞。这些成 few-shot 示例。再生时应用到列。 - 导出后如何扩展?
用 config.yml 和脚本运行 HF Jobs。指定行数生成更大数据集。 - 是否需订阅?
在线免费试用。本地或更多推理用 PRO 订阅获 20x 用量。 - 数据上限是多少?
上传或生成最多 1000 行。无限列。用 Jobs 扩展更大。 - 如何启用 web 搜索?
在列配置开关 toggle search。模型拉最新信息。
























