


对于任何希望在本地运行开源大语言模型的开发者来说,Ollama 已经成为一个不可或缺的工具。它极大地简化了模型的下载、部署和管理流程。然而,随着模型参数规模的爆炸式增长,即使是专业的个人电脑也难以承受动辄数百GB的显存和内存需求,这使得许多尖端模型对于大多数开发者而言遥不可及。
为了解决这一核心痛点,Ollama 近日正式推出了云模型(Cloud Models)预览版。这项新服务旨在通过一个巧妙的方案,让开发者能够在数据中心级的硬件上运行那些巨型模型,而交互体验却与在本地运行别无二致。
核心特性:突破硬件限制,保持本地体验
Ollama Cloud 的设计理念并非简单地提供一个云端 API 接口,而是将云端算力无缝集成到开发者熟悉的本地工作流中。
- 突破硬件限制:用户现在可以直接从本地终端运行像
deepseek-v3.1:671b(6710亿参数)或qwen3-coder:480b(4800亿参数)这类巨型模型。前者是一个强大的混合思维模型,而后者则是由阿里巴巴开发、专精于代码生成和代理任务的模型。这些模型所需的计算资源远超个人设备范畴,而Ollama Cloud则将这一障碍彻底清除。 - 无缝的本地化体验:这是
Ollama Cloud最具吸引力的一点。用户无需改变现有的工具链,所有操作依然通过本地的Ollama客户端完成。无论是使用ollama run进行交互式对话,还是通过ollama ls查看模型列表,其体验和管理本地模型完全一致。云端模型在本地仅表现为一个轻量级的引用或“快捷方式”,不占用任何磁盘空间。 - 隐私与安全优先:在 AI 应用中,数据隐私是关键考量。
Ollama官方明确承诺,云端服务器不会保留用户的任何查询数据,确保对话和代码片段的私密性。 - 兼容 OpenAI API:
Ollama的本地服务因其对OpenAIAPI 格式的兼容性而广受欢迎。Ollama Cloud继承了这一特性,意味着所有现存的支持OpenAIAPI 的应用程序和工作流,都可以 без缝隙地切换到使用这些云端大模型。
当前可用的云模型
目前,Ollama Cloud 预览版提供了以下几款超大参数模型,模型名称均带有 -cloud 后缀以作区分:
- qwen3-coder:480b-cloud: 阿里巴巴旗下专注于代码生成和代理任务的旗舰模型。
- deepseek-v3.1:671b-cloud: 一款支持混合思维模式的超大规模通用模型,在推理和编码方面表现出色。
- gpt-oss:120b-cloud
- gpt-oss:20b-cloud
快速上手指南
体验 Ollama Cloud 的过程非常简单,只需几个步骤即可完成。
第一步:更新 Ollama
确保本地安装的 Ollama 版本升级至 v0.12 或更高。可以通过官方网站下载最新版本或使用系统包管理器更新。
第二步:登录 Ollama 账户
由于云模型需要调用 ollama.com 的计算资源,用户必须登录自己的 Ollama 账户以完成身份验证。在终端中执行以下命令:
ollama signin
该命令会引导用户在浏览器中完成登录授权。
第三步:运行云模型
登录成功后,便可以像运行本地模型一样直接运行云模型。例如,要启动 4800 亿参数的 Qwen3-Coder 模型,只需执行:
ollama run qwen3-coder:480b-cloud
Ollama 客户端会自动处理所有到云端的请求路由,用户只需等待模型响应即可。
第四步:管理云模型
使用 ollama ls 命令可以查看已拉取到本地的模型列表。你会发现,云模型的 SIZE 一栏显示为 -,这直观地表明了它只是一个不占用本地存储空间的引用。
% ollama ls
NAME ID SIZE MODIFIED
gpt-oss:120b-cloud 569662207105 - 5 seconds ago
qwen3-coder:480b-cloud 11483b8f8765 - 2 days ago
API 集成与调用
对于开发者而言,API 调用是集成的核心。Ollama Cloud 支持两种主要的 API 调用方式:通过本地代理和直接访问云端端点。
方式一:通过本地 Ollama 服务代理
这是最简单也是最推荐的方式,它能与现有工作流完美兼容。
首先,使用 pull 命令将模型引用拉取到本地:
ollama pull gpt-oss:120b-cloud
然后,像调用任何本地模型一样,向本地 Ollama 服务 (http://localhost:11434) 发送请求。
Python 示例
import ollama
response = ollama.chat(
model='gpt-oss:120b-cloud',
messages=[{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
JavaScript (Node.js) 示例
import ollama from "ollama";
const response = await ollama.chat({
model: "gpt-oss:120b-cloud",
messages: [{ role: "user", content: "Why is the sky blue?" }],
});
console.log(response.message.content);
cURL 示例
curl http://localhost:11434/api/chat -d '{
"model": "gpt-oss:120b-cloud",
"messages": [{
"role": "user",
"content": "Why is the sky blue?"
}],
"stream": false
}'
方式二:直接访问云端 API
在某些场景下,如在服务器或云函数中,直接调用云端 API 会更加方便。
- API 端点:
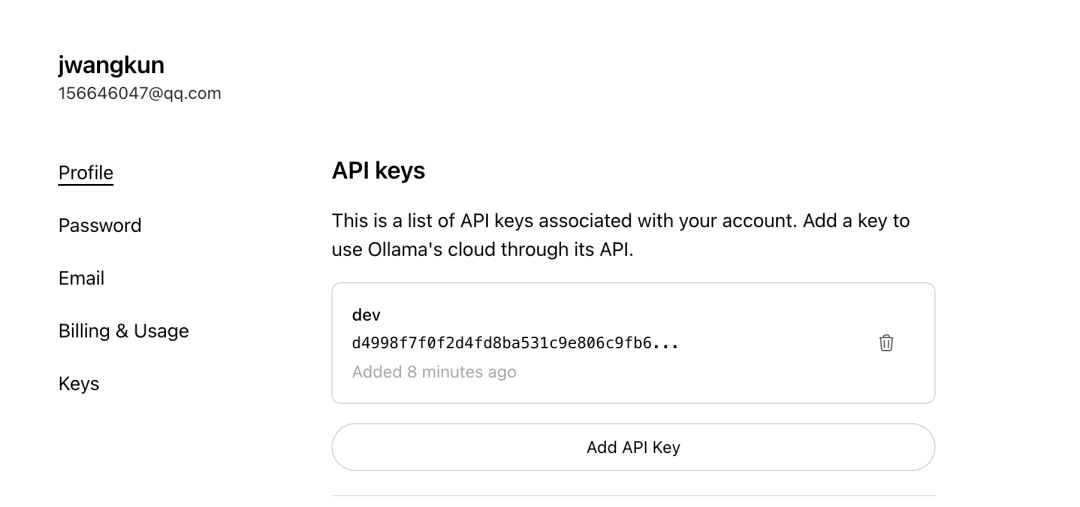
https://ollama.com/v1/chat/completions - API Key 申请: 直接访问该端点需要专用的 API Key。用户可以在
Ollama官网登录后,前往 Keys 页面生成自己的密钥。
直接调用云端 API 遵循标准的 OpenAI 格式,只需在请求头中携带相应的 Authorization 凭证即可。
与第三方工具的整合
Ollama Cloud 的设计优势在于其对生态的无缝兼容。所有支持通过 Ollama 本地 API 端点进行连接的第三方客户端,如 Open WebUI、LobeChat 或 Cherry Studio,都无需任何修改即可直接使用云模型。
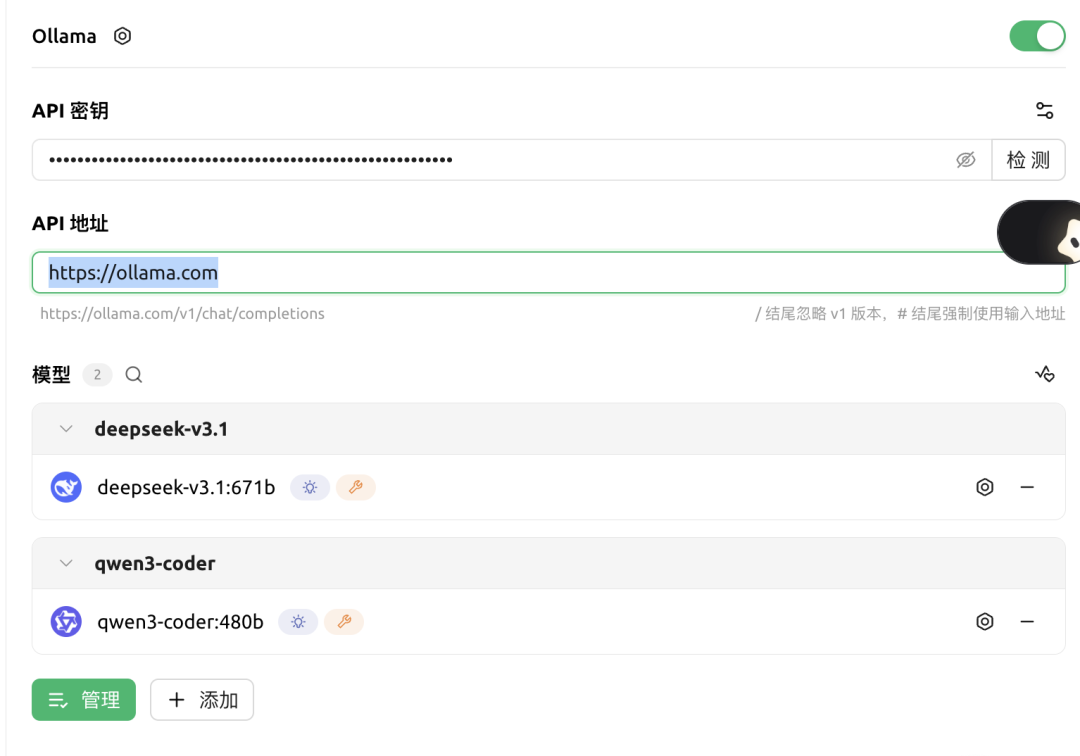
以 Cherry Studio 的配置为例:
- 确保
API端点指向本地Ollama实例:http://localhost:11434。 - 在模型名称列表中,直接填入你已拉取过的云模型名称,例如
gpt-oss:120b-cloud。 API Key字段通常留空,因为认证已经通过ollama signin在本地客户端完成。
配置完成后,你在这些工具中对云模型的调用将被本地 Ollama 客户端自动代理到云端进行处理,整个过程对上层应用完全透明。
战略意义与展望
Ollama Cloud 的推出,标志着开源 AI 模型在可用性上迈出了重要一步。它不仅为个人开发者和爱好者打开了通往顶级大模型的大门,更重要的是,它通过保持本地化的交互体验,降低了开发者的学习和迁移成本。
目前该服务处于预览阶段,官方提到设有临时的速率限制以保证服务稳定,并计划在未来推出基于用量的计费模式。 这一举措将 Ollama 定位为连接本地开发环境与云端强大算力的桥梁,使其在与 Groq、Replicate 等纯云端推理服务的竞争中,拥有了独特的开发者体验优势。



































