



GBC MedAI 是一个开源的智能医疗助手系统。它使用 FastAPI 作为后端框架,Vue 3 作为前端技术栈。这个系统的核心能力在于能够同时集成多种AI大语言模型,例如 DeepSeek、本地部署的 Ollama 以及其他兼容 OpenAI 接口的模型。它还整合了多种搜索引擎服务,为用户提供融合了实时信息的智能对话和搜索功能。该项目采用模块化架构,技术栈先进且完整,旨在为医疗领域或其他专业场景提供一个可以快速部署和二次开发的 AI 助手解决方案。
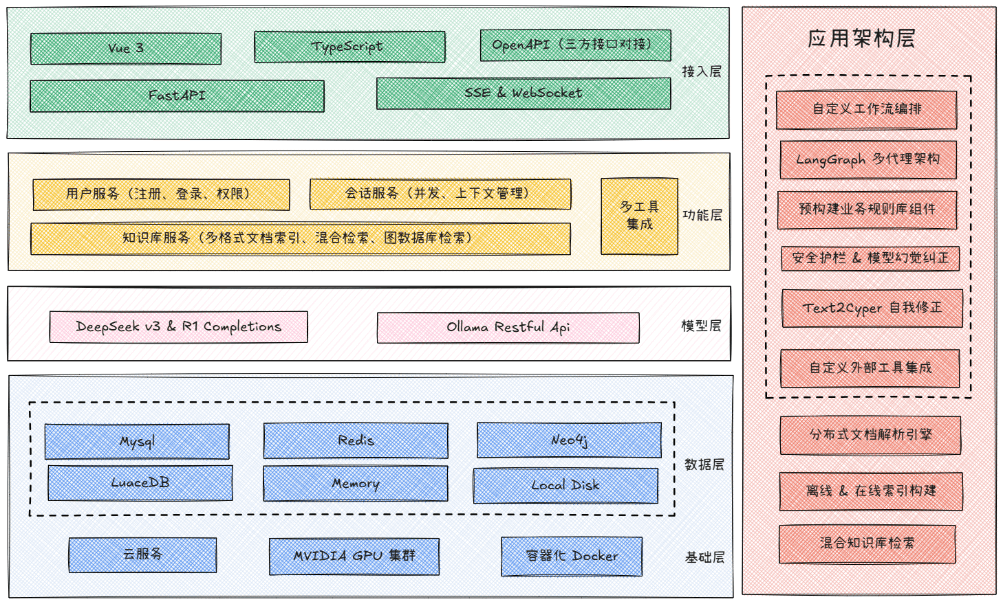
功能列表
- AI 能力: 支持接入 DeepSeek、Ollama 本地模型及兼容 OpenAI 的多种 AI 模型。系统具备处理复杂推理任务和视觉理解的能力,可以分析上传的图片。
- 智能搜索: 集成博查 AI、百度 AI 搜索和 SerpAPI,能够根据问题自动选择最合适的搜索引擎,获取最新的医疗资讯和研究进展。
- 对话系统: 提供流畅的流式响应和上下文记忆功能。系统内置了完整的用户认证和多会v话管理机制,可以保存历史记录。
- 现代化前端: 采用 Vue 3 和 TypeScript 构建,提供响应式布局,同时支持桌面和移动设备。界面设计为精美的二次元动漫风格,并包含丰富的交互动画。
- 高性能后端: 基于 FastAPI 异步框架开发,可以确保高效率的请求处理能力。
- 数据与缓存: 使用 Redis 作为语义缓存,可以有效提升重复查询的响应性能,降低AI模型调用成本。
- 高级AI框架: 应用了 LangGraph 和 GraphRag 等技术,用于构建更复杂的AI流程和知识图谱应用。
使用帮助
本部分将详细介绍如何安装、配置并成功运行 GBC MedAI 系统。请按照以下步骤操作,即可完成部署。
环境要求
在开始之前,请确保您的系统环境满足以下条件:
- Python: 3.8 或更高版本
- Node.js: 16 或更高版本 (仅在需要进行前端开发时需要)
- 数据库: MySQL 8.0 或更高版本,Redis 6.0 或更高版本
- 知识图谱 (可选): Neo4j 4.0 或更高版本
前置文件下载
项目运行依赖一些预置文件,请先从以下地址下载并解压到指定目录:
- 前端文件: 从百度网盘链接
https://pan.baidu.com/s/1KTROmn78XhhcuYBOfk0iUQ?pwd=wi8k(提取码: wi8k) 下载前端打包文件,并将其解压到llm_backend/static/目录下。 - GraphRag 文件: 从百度网盘链接
https://pan.baidu.com/s/1dg6YxN_a4wZCXrmHBPGj_Q?pwd=hppu(提取码: hppu) 下载 GraphRag 相关文件,并将其放置到项目根目录。
安装与配置步骤
1. 克隆项目代码
首先,使用 git 命令将项目代码从 GitHub 克隆到您的本地计算机。
git clone https://github.com/zhanlangerba/gbc-madai.git
cd gbc-madai
2. 后端服务设置
进入后端代码目录,并使用 pip 安装所有 Python 依赖库。
cd llm_backend
pip install -r requirements.txt
3. 配置环境变量
配置文件是系统运行的关键。您需要复制模板文件并填入您的个人配置信息。
# 复制环境变量模板文件
cp .env.example .env
# 使用文本编辑器(如 nano 或 vim)打开并编辑 .env 文件
nano .env
在 .env 文件中,您需要填入以下信息:
DEEPSEEK_API_KEY: 您的 DeepSeek API 密钥。BOCHA_AI_API_KEY/BAIDU_AI_SEARCH_API_KEY/SERPAPI_KEY: 根据您选择的搜索引擎,填入对应的 API 密钥。DB_HOST,DB_USER,DB_PASSWORD,DB_NAME: 您的 MySQL 数据库连接信息。REDIS_HOST,REDIS_PORT: 您的 Redis 服务连接信息。NEO4J_URL,NEO4J_USERNAME,NEO4J_PASSWORD: 您的 Neo4j 数据库连接信息(如果使用)。
4. 初始化数据库
在启动服务前,需要先在 MySQL 中创建项目所需的数据库。
# 使用您的 MySQL root 用户登录并执行以下命令
mysql -u root -p -e "CREATE DATABASE assist_gen CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;"
5. 启动系统服务
完成以上所有步骤后,运行 run.py 脚本来启动整个系统。
# 启动后端服务
python run.py
服务成功启动后,您可以通过浏览器访问以下地址:
- 前端访问地址:
http://localhost:8000/ - API 文档地址 (Swagger UI):
http://localhost:8000/docs
部署方式
除了直接运行源代码,项目还支持更稳定和便捷的 Docker 部署方式。
使用 Docker 部署 (推荐)
确保您已经安装了 Docker。在项目根目录下执行以下命令:
# 1. 构建 Docker 镜像,将其命名为 gbc-madai
docker build -t gbc-madai .
# 2. 以后台模式运行容器,并将本地的 .env 文件作为环境变量传入
docker run -d -p 8000:8000 --env-file .env gbc-madai
前端独立开发
如果您需要对前端界面进行修改和开发,可以进入 gbc_madai_web 目录,独立运行前端开发服务。“`shell
进入前端代码目录
cd ../gbc_madai_web
安装前端依赖
npm install
启动前端开发服务器
npm run dev
前端开发服务将在 http://localhost:3000 启动,并会自动将 API 请求代理到 http://localhost:8000。
应用场景
- 智能医疗咨询
作为一个虚拟医生助手,可以7×24小时在线回答患者关于常见疾病、用药建议和健康生活的提问,提供初步的医疗指引。 - 临床辅助决策
辅助医生快速检索和分析最新的医学文献、临床试验报告和治疗指南,为制定更精准的诊疗方案提供信息支持。 - 医疗信息检索平台
可作为医院或研究机构内部的智能知识库,帮助员工快速查找内部规章制度、操作流程、病例档案和科研资料。 - 其他专业领域应用
系统的模块化设计使其可以轻松扩展到电商、金融、法律等其他专业领域,作为智能客服或专家助手使用。
QA
- 这个项目是免费开源的吗?
是的,该项目基于 MIT 许可证完全开源,您可以免费地在个人或商业项目中使用、修改和分发。 - 部署这个系统需要具备哪些技术背景?
您需要对 Python 语言和 FastAPI 框架有基本了解,同时需要掌握 MySQL 和 Redis 数据库的安装和基本操作。如果选择 Docker 部署,还需要熟悉 Docker 的常用命令。 - 我可以接入自己的AI模型吗?
可以。系统架构支持接入任何兼容 OpenAI API 标准的模型。您只需要在.env配置文件中修改模型的 API 地址(OLLAMA_BASE_URL或类似变量)和密钥即可。系统本身已原生支持 DeepSeek 和 Ollama。 - 前端界面可以被替换吗?
可以。系统后端提供了一套完整的 REST API。您可以完全不使用项目自带的前端,而是根据 API 文档(http://localhost:8000/docs)开发自己的客户端应用,例如桌面程序、移动 App 或小程序。



























