


SongGeneration 是由腾讯 AI Lab 开发并开源的音乐生成模型,专注于生成高品质的歌曲,包括歌词、伴奏和人声。它基于 LeVo 框架,结合语言模型 LeLM 和音乐编解码器,支持中英文歌曲生成。模型在百万歌曲数据集上训练,能生成音质优异、结构完整的音乐作品,适用于音乐创作、视频配乐等场景。用户可通过文本描述或参考音频控制音乐风格、情感和节奏,生成个性化歌曲。SongGeneration 的开源特性使其对开发者、音乐爱好者和内容创作者开放,支持在低内存设备上运行,降低了使用门槛。
功能列表
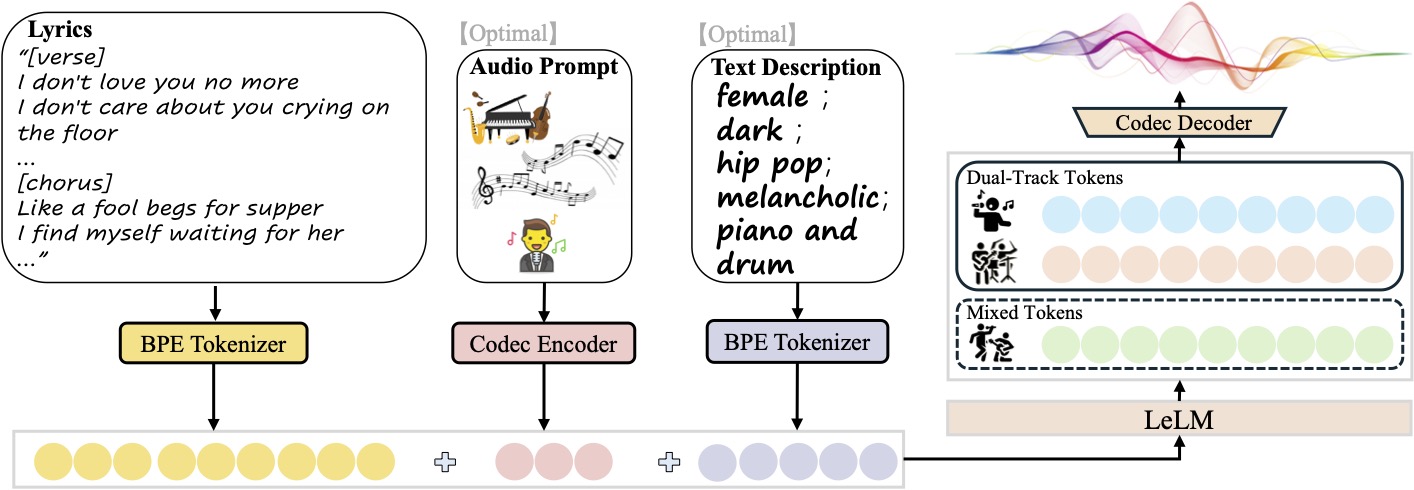
- 歌曲生成:根据输入的歌词和文本描述生成完整歌曲,包含人声和伴奏。
- 多轨输出:支持单独生成纯音乐、纯人声或分离的人声与伴奏轨道,便于后期编辑。
- 风格控制:通过文本描述(如性别、音色、流派、情感、乐器、节拍)自定义音乐风格。
- 参考音频:上传 10 秒音频片段,模型可模仿其风格生成新曲。
- 低内存优化:支持最低 10GB GPU 内存运行,适合多种设备。
- 开源支持:提供模型权重、推理脚本和配置文件,开发者可自由修改和优化。
使用帮助
安装流程
要使用 SongGeneration,需先完成环境配置和模型安装。以下是详细步骤,基于官方 GitHub 仓库的说明,适用于 Linux 系统(Windows 用户可参考 ComfyUI 版本):
- 创建 Python 环境
使用 Python 3.8.12 或更高版本,建议通过 conda 创建虚拟环境:conda create -n songgeneration python=3.8.12 conda activate songgeneration - 安装依赖
安装必要的依赖项,包括 PyTorch 和 FFmpeg:yum install ffmpeg pip install -r requirements.txt --no-deps --extra-index-url https://download.pytorch.org/whl/cu118 - 安装 Flash Attention(可选)
为加速推理,安装 Flash Attention(需要 CUDA 11.8 或以上):wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -P /home/ pip install /home/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl如果 GPU 不支持 Flash Attention,可在推理时添加
--not_use_flash_attn参数。 - 下载模型权重
从 Hugging Face 下载模型权重和配置文件,确保ckpt和third_party文件夹完整保存至项目根目录:git clone https://github.com/tencent-ailab/SongGeneration cd SongGeneration访问 Hugging Face 仓库(
https://huggingface.co/tencent/SongGeneration)下载songgeneration_base_zh或其他版本的模型权重。 - Docker 安装(可选)
为简化配置,可使用官方 Docker 镜像:docker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
使用方法
SongGeneration 支持通过命令行或脚本生成音乐,核心操作是准备输入文件并运行推理脚本。以下是详细操作流程:
- 准备输入文件
输入文件需为 JSON Lines(.jsonl)格式,每行代表一个生成请求,包含以下字段:idx:生成音频的文件名(唯一标识符)。gt_lyric:歌词,格式为[结构] 歌词文本,如[Verse] 这是第一段歌词。。支持的结构包括[intro-short]、[verse]、[chorus]等,具体参考conf/vocab.yaml。descriptions(可选):描述音乐属性,如female, pop, sad, piano, the bpm is 125。prompt_audio_path(可选):10 秒参考音频路径,用于模仿风格。
示例
lyrics.jsonl:{"idx": "song1", "gt_lyric": "[intro-short]\n[verse] 这些逝去的回忆。我们无法抹去泪水。\n[chorus] 像傻瓜乞求晚餐。我在等待她的归来。", "descriptions": "female, pop, sad, piano, the bpm is 125"} - 运行推理脚本
使用默认脚本生成歌曲:sh generate.sh <ckpt_path> <lyrics.jsonl> <output_path><ckpt_path>:模型权重路径。<lyrics.jsonl>:输入文件路径。<output_path>:输出音频保存路径。
如果 GPU 内存不足(<30GB),使用低内存模式:
sh generate_lowmem.sh <ckpt_path> <lyrics.jsonl> <output_path> - 自定义生成选项
- 生成纯音乐:添加
--pure_music标志。 - 生成纯人声:添加
--pure_vocal标志。 - 分离人声和伴奏:添加
--separate_tracks标志,生成独立的人声和伴奏轨道。 - 禁用 Flash Attention:添加
--not_use_flash_attn。
- 生成纯音乐:添加
- Windows 用户(ComfyUI 版本)
Windows 用户可使用 ComfyUI 界面简化操作:- 克隆 ComfyUI 插件仓库:
cd ComfyUI/custom_nodes git clone https://github.com/smthemex/ComfyUI_SongGeneration.git - 安装
fairseq库(Windows 下推荐使用预编译 wheel 文件):pip install liyaodev/fairseq - 将模型权重放入
ComfyUI/models/SongGeneration/目录。 - 通过 ComfyUI 界面加载模型,输入歌词和描述,点击生成按钮。
- 克隆 ComfyUI 插件仓库:
操作注意事项
- 输入提示:避免同时提供
prompt_audio_path和descriptions,否则可能因冲突导致生成质量下降。 - 歌词格式:歌词需按结构分段(如
[verse]、[chorus]),非歌词段(如[intro-short])不应包含歌词。 - 参考音频:建议使用歌曲副歌部分(10 秒以内),以获得最佳音乐性。
- 硬件要求:基础模型需要 10GB GPU 内存,带参考音频需 16GB。
应用场景
- 音乐创作
音乐人可输入歌词和风格描述,快速生成歌曲 demo,节省创作时间。例如,输入“男声,爵士,钢琴,110 BPM”生成爵士风格歌曲。 - 视频配乐
视频创作者可上传 10 秒参考音频,生成风格一致的背景音乐,适用于短视频、广告或电影配乐。 - 游戏开发
游戏开发者可生成多轨音乐,分别调整人声和伴奏,适配不同游戏场景,如战斗或剧情。 - 教育与实验
学生和研究者可利用开源代码研究音乐生成算法,或在课堂上测试 AI 音乐创作效果。
QA
- SongGeneration 支持哪些语言的歌曲生成?
目前支持中文和英文歌曲生成,模型在百万歌曲数据集(含中英文歌曲)上训练,未来可能支持更多语言。 - 如何确保生成音乐的音质?
使用官方提供的模型权重和音乐编解码器,确保音频采样率为 48kHz。避免使用过短的歌词,模型会自动补全以保证结构完整。 - 需要多大内存运行模型?
基础模型需要 10GB GPU 内存,带参考音频需要 16GB。低内存模式(generate_lowmem.sh)可优化内存使用。 - 能否商用生成的音乐?
需检查模型许可(CC BY-NC 4.0),生成内容可能受版权限制,商用前建议咨询法律专家。


























