



RAGLight 是一个轻量级、模块化的 Python 库,专为实现检索增强生成(RAG)设计。它通过结合文档检索和自然语言生成,提升大语言模型(LLM)的上下文理解能力。RAGLight 支持多种语言模型、嵌入模型和向量存储,适合开发者快速构建上下文感知的 AI 应用。它的设计注重简单性和灵活性,用户可以轻松集成本地文件夹或 GitHub 仓库中的数据,生成准确的回答。RAGLight 完全开源,运行时需配合 Ollama 或 LMStudio,支持本地化部署,适合对隐私和成本敏感的项目。
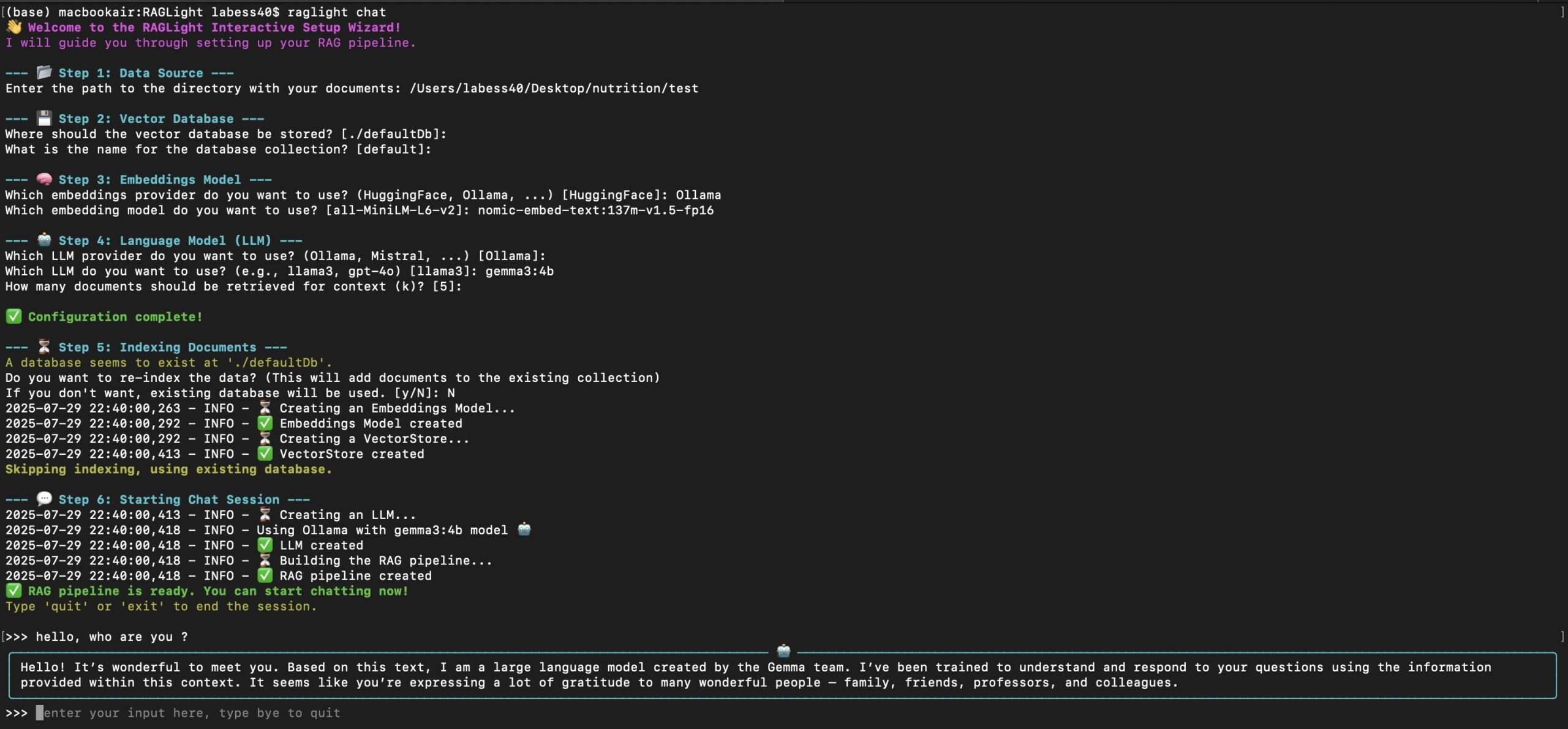
功能列表
- 支持多种数据源:可从本地文件夹(如 PDF、文本文件)或 GitHub 仓库导入知识库。
- 模块化 RAG 管道:结合文档检索和语言生成,支持标准 RAG、Agentic RAG 和 RAT(检索增强思考)模式。
- 灵活的模型集成:支持 Ollama 和 LMStudio 的多种大语言模型,如
llama3。 - 高效向量存储:使用 Chroma 或 HuggingFace 嵌入模型生成文档向量,支持快速相似性搜索。
- 自定义配置:允许用户调整嵌入模型、向量存储路径和检索参数(如
k值)。 - 文档处理自动化:自动从指定源提取和索引文档内容,简化知识库构建。
使用帮助
安装流程
RAGLight 的安装和使用需要 Python 环境和运行中的 Ollama 或 LMStudio。以下是详细步骤:
- 安装 Python 和依赖项
确保系统已安装 Python 3.8 或更高版本。使用以下命令安装 RAGLight:pip install raglight如果使用 HuggingFace 嵌入模型,需额外安装相关依赖:
pip install sentence-transformers - 安装并运行 Ollama 或 LMStudio
- 下载并安装 Ollama(https://ollama.ai)或 LMStudio。
- 在 Ollama 中拉取模型,例如:
ollama pull llama3 - 确保模型在 Ollama 或 LMStudio 中加载并运行。
- 配置环境
创建项目文件夹,准备知识库数据(如 PDF 文件夹或 GitHub 仓库 URL)。确保网络连接正常以访问 GitHub 或 HuggingFace。
使用 RAGLight 创建简单 RAG 管道
RAGLight 提供简洁的 API 来构建 RAG 管道。以下是一个基础示例,用于从本地文件夹和 GitHub 仓库构建知识库并生成回答:
from raglight.rag.simple_rag_api import RAGPipeline
from raglight.models.data_source_model import FolderSource, GitHubSource
from raglight.config.settings import Settings
Settings.setup_logging()
# 定义知识库来源
knowledge_base = [
FolderSource(path="/path/to/your/folder/knowledge_base"),
GitHubSource(url="https://github.com/Bessouat40/RAGLight")
]
# 初始化 RAG 管道
pipeline = RAGPipeline(
knowledge_base=knowledge_base,
model_name="llama3",
provider=Settings.OLLAMA,
k=5
)
# 构建管道(处理文档并创建向量存储)
pipeline.build()
# 生成回答
response = pipeline.generate("如何使用 RAGLight 创建一个简单的 RAG 管道?")
print(response)
特色功能操作
- 支持多种数据源
RAGLight 允许用户从本地文件夹或 GitHub 仓库导入数据。- 本地文件夹:将 PDF 或文本文件放入指定文件夹,例如
/path/to/knowledge_base。 - GitHub 仓库:提供仓库 URL(如
https://github.com/Bessouat40/RAGLight),RAGLight 会自动提取仓库中的文档。
示例配置:
knowledge_base = [ FolderSource(path="/data/knowledge_base"), GitHubSource(url="https://github.com/Bessouat40/RAGLight") ] - 本地文件夹:将 PDF 或文本文件放入指定文件夹,例如
- 标准 RAG 管道
标准 RAG 管道结合文档检索和生成。用户输入查询后,RAGLight 将查询转换为向量,通过相似性搜索检索相关文档片段,并将这些片段作为上下文输入 LLM 生成回答。
操作步骤:- 初始化
RAGPipeline并指定知识库、模型和k值(检索文档数量)。 - 调用
pipeline.build()处理文档并生成向量存储。 - 使用
pipeline.generate("查询")获取回答。
- 初始化
- Agentic RAG 和 RAT 模式
- Agentic RAG:通过
AgenticRAGPipeline实现,增加智能体功能,支持多步推理和动态调整检索策略。
示例:from raglight.rag.simple_agentic_rag_api import AgenticRAGPipeline from raglight.config.agentic_rag_config import SimpleAgenticRAGConfig config = SimpleAgenticRAGConfig(k=5, max_steps=4) pipeline = AgenticRAGPipeline(knowledge_base=knowledge_base, config=config) pipeline.build() response = pipeline.generate("如何优化 RAGLight 的检索效率?") print(response) - RAT(检索增强思考):通过
RATPipeline实现,增加反思步骤(reflection参数),提升回答的逻辑性和准确性。
示例:from raglight.rat.simple_rat_api import RATPipeline pipeline = RATPipeline( knowledge_base=knowledge_base, model_name="llama3", reasoning_model_name="deepseek-r1:1.5b", reflection=2, provider=Settings.OLLAMA ) pipeline.build() response = pipeline.generate("如何简化 RAGLight 的配置?") print(response)
- Agentic RAG:通过
- 自定义向量存储
RAGLight 使用 Chroma 作为默认向量存储,支持 HuggingFace 嵌入模型(如all-MiniLM-L6-v2)。用户可自定义存储路径和集合名称:from raglight.config.vector_store_config import VectorStoreConfig vector_store_config = VectorStoreConfig( embedding_model="all-MiniLM-L6-v2", provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory="./defaultDb", collection_name="my_collection" )
操作注意事项
- 确保 Ollama 或 LMStudio 运行时模型已加载,否则会报错。
- 本地文件夹路径需包含有效文档(如 PDF、TXT),GitHub 仓库需公开访问。
- 调整
k值以控制检索文档数量,k=5通常是平衡效率和准确性的选择。 - 如果使用 HuggingFace 嵌入模型,需确保网络可访问 HuggingFace API。
应用场景
- 学术研究
研究人员可将论文 PDF 导入本地文件夹,使用 RAGLight 快速检索文献内容并生成总结或回答问题。例如,输入“某领域最新进展”可获取相关论文的上下文回答。 - 企业知识库
企业可将内部文档(如技术手册、FAQ)导入 RAGLight,构建智能问答系统。员工输入问题后,系统从文档中检索并生成准确回答。 - 开发者工具
开发者可将 GitHub 仓库的代码文档作为知识库,快速查询 API 使用方法或代码片段。例如,输入“如何调用某函数”可获取相关文档说明。 - 教育辅助
教师或学生可将教材或课程笔记导入 RAGLight,生成针对性解答或学习总结。例如,输入“解释某概念”可获取教材中的相关内容。
QA
- RAGLight 支持哪些语言模型?
RAGLight 支持 Ollama 和 LMStudio 提供的模型,如llama3、deepseek-r1:1.5b等。用户需在 Ollama 或 LMStudio 中预先加载模型。 - 如何添加自定义数据源?
使用FolderSource指定本地文件夹路径,或GitHubSource指定公开 GitHub 仓库 URL。确保路径有效且文件格式支持(如 PDF、TXT)。 - 如何优化检索准确性?
增加k值以检索更多文档,或使用 RAT 模式启用反思功能。选择高质量嵌入模型(如all-MiniLM-L6-v2)也能提升准确性。 - 是否支持云端部署?
RAGLight 主要为本地部署设计,需配合 Ollama 或 LMStudio 运行。不直接支持云端,但可通过容器化(如 Docker)部署。


























