



Kitten-TTS-Server 是一个开源项目,它为轻量级的 KittenTTS 模型提供了一个功能增强的服务器。用户可以通过这个项目自己搭建一个文本转语音(TTS)服务。这个项目的核心优势在于它在原始模型的基础上,增加了一个直观的网页用户界面(Web UI)、用于制作有声读物的长文本处理功能,以及显著提升性能的 GPU 加速能力。该服务器的底层模型非常小,只有不到25MB,但能生成听起来很真实自然的人声。项目通过提供一个功能齐全的服务器,简化了模型的安装和运行过程,让不具备专业知识背景的用户也能轻松使用。服务器内置了8种预设的语音(4种男性,4种女性),并且支持通过 Docker 进行部署,大大降低了配置和维护的复杂性。
功能列表
- 轻量级模型:核心采用 KittenTTS ONNX 模型,体积小于 25MB,资源占用少。
- GPU 加速:通过优化的
onnxruntime-gpu管道和 I/O 绑定技术,全面支持 NVIDIA (CUDA) 加速,显著提升语音生成速度。 - 长文本与有声书生成:能够自动处理长篇文本,通过智能断句、分块处理再无缝拼接音频的方式,非常适合用来生成完整的有声读物。
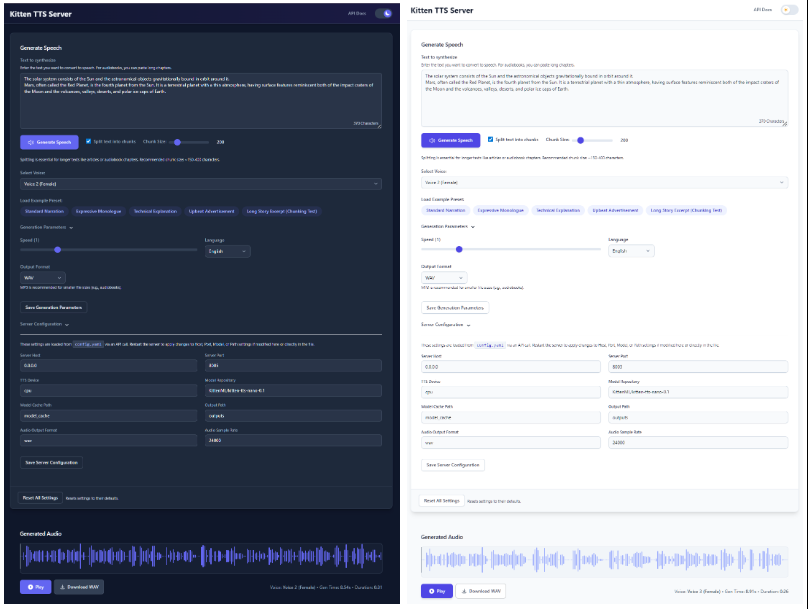
- 现代化网页界面:提供一个直观的 Web UI,用户可以直接在浏览器中输入文本、选择语音、调整语速,并能实时看到生成音频的波形图。
- 内置多种语音:集成了 KittenTTS 模型自带的8种语音(4男4女),可以直接在界面上选择。
- 双 API 接口:提供一个功能完整的
/tts接口和一个兼容 OpenAI TTS API 结构的/v1/audio/speech接口,方便集成到现有工作流中。 - 配置简单:所有设置都通过一个单一的
config.yaml文件进行管理。 - 状态记忆:网页界面能够记住上次使用的文本、语音和相关设置,简化操作流程。
- Docker 支持:提供为 CPU 和 GPU 环境预设好的 Docker Compose 文件,实现一键式容器化部署。
使用帮助
Kitten-TTS-Server 项目提供了清晰的安装和使用流程,确保用户可以顺利地在自己的硬件上把它运行起来。
系统环境准备
在安装之前,你需要准备好以下环境:
- 操作系统: Windows 10/11 (64位) 或 Linux (推荐 Debian/Ubuntu)。
- Python: 3.10 或更高版本。
- Git: 用于从 GitHub 克隆项目代码。
- eSpeak NG: 这是一个必需的依赖项,用于文本音素化。
- Windows: 从 eSpeak NG 的发布页面下载并安装
espeak-ng-X.XX-x64.msi。安装后需要重启命令行终端。 - Linux: 在终端运行命令
sudo apt install espeak-ng。
- Windows: 从 eSpeak NG 的发布页面下载并安装
- (GPU 加速可选):
- 一块支持 CUDA 的 NVIDIA 显卡。
- (仅 Linux): 需要安装
libsndfile1和ffmpeg。可以通过命令sudo apt install libsndfile1 ffmpeg来安装。
安装步骤
整个安装过程被设计为“一键式”,根据你的硬件选择不同的安装路径。
第一步:克隆代码仓库
打开你的终端(在 Windows 上是 PowerShell,在 Linux 上是 Bash),然后运行以下命令:
git clone https://github.com/devnen/Kitten-TTS-Server.git
cd Kitten-TTS-Server
第二步:创建并激活 Python 虚拟环境
为了避免与其他项目的依赖库产生冲突,强烈建议创建一个独立的虚拟环境。
- Windows (PowerShell):
python -m venv venv .\venv\Scripts\activate - Linux (Bash):
python3 -m venv venv source venv/bin/activate
激活成功后,你的命令行提示符前面会出现 (venv) 字样。
第三步:安装 Python 依赖库
根据你的电脑是否配有 NVIDIA 显卡,选择下面其中一种方式进行安装。
- 选项一:仅使用 CPU 安装(最简单)
这种方式适用于所有电脑。pip install --upgrade pip pip install -r requirements.txt - 选项二:使用 NVIDIA GPU 安装(性能更强)
这种方式会安装所有必要的 CUDA 库,让程序在显卡上运行。pip install --upgrade pip # 安装支持GPU的ONNX Runtime pip install onnxruntime-gpu # 安装支持CUDA的PyTorch,它会一并安装onnxruntime-gpu所需的驱动文件 pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # 安装其余的依赖 pip install -r requirements-nvidia.txt安装完成后,可以运行以下命令验证 PyTorch 是否能正确识别到你的显卡:
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"如果输出结果为
CUDA available: True,说明 GPU 环境配置成功。
运行服务器
注意:第一次启动服务器时,它会自动从 Hugging Face 下载约 25MB 大小的 KittenTTS 模型文件。这个过程只需要一次,后续启动会非常快。
- 确保你已经激活了虚拟环境(命令行前面有
(venv))。 - 在终端里运行服务器:
python server.py - 服务器启动后,会自动在你的默认浏览器中打开网页操作界面。
- 网页界面地址:
http://localhost:8005 - API 文档地址:
http://localhost:8005/docs
- 网页界面地址:
要停止服务器,只需在运行服务器的终端窗口中按下 CTRL+C。
Docker 安装方式
如果你熟悉 Docker,可以使用 Docker Compose 来进行部署,这种方式更简单,并且可以更好地管理应用。
- 环境准备:
- 安装 Docker 和 Docker Compose。
- (GPU 用户) 安装 NVIDIA Container Toolkit。
- 克隆代码仓库 (如果之前没做过):
git clone https://github.com/devnen/Kitten-TTS-Server.git cd Kitten-TTS-Server - 启动容器 (根据你的硬件选择命令):
- NVIDIA GPU 用户:
docker compose up -d --build - 仅 CPU 用户:
docker compose -f docker-compose-cpu.yml up -d --build
- NVIDIA GPU 用户:
- 访问和管理:
- 网页界面:
http://localhost:8005 - 查看日志:
docker compose logs -f - 停止容器:
docker compose down
- 网页界面:
功能操作
- 生成普通语音:
- 启动服务器并打开
http://localhost:8005。 - 在文本框中输入你想要转换的文字。
- 从下拉菜单中选择一个喜欢的声音。
- 可以拖动滑块调整语速。
- 点击“Generate Speech”按钮,音频会自动播放,并提供下载链接。
- 启动服务器并打开
- 生成有声书:
- 将整本书或一个章节的纯文本内容复制出来。
- 粘贴到网页的文本框中。
- 确保“Split text into chunks”(将文本拆分为块)选项是勾选状态。
- 为了让停顿更自然,建议设置一个 300 到 500 字符之间的分块大小(Chunk Size)。
- 点击“Generate Speech”按钮,服务器会自动把长文本切片、生成语音,最后拼接成一个完整的音频文件供你下载。
应用场景
- 制作有声书
对于喜欢听书的用户或者内容创作者,可以利用这个工具将电子书、长篇文章或网络小说转换成有声读物。其长文本处理功能可以自动完成切分和拼接,生成完整的音频文件。 - 个人语音助手
开发者可以将其 API 集成到自己的应用程序中,为应用添加语音播报功能,例如朗读新闻、天气预报或通知信息。 - 视频内容配音
自媒体创作者在制作视频时,可以用它来生成旁白或解说。相比真人录音,它的效率更高,成本更低,而且可以随时修改文案并重新生成配音。 - 学习辅助工具
语言学习者可以输入单词或句子,生成标准发音用于跟读模仿。也可以将学习资料转换成音频,在通勤或运动时收听。
QA
- 这个项目和直接使用 KittenTTS 模型有什么不同?
这个项目是基于 KittenTTS 模型的一个“服务化”封装。它解决了直接使用模型时环境配置复杂、缺少用户界面、无法处理长文本以及不支持 GPU 加速等问题。Kitten-TTS-Server 提供了一个开箱即用的网页界面和 API 服务,让普通用户也能轻松使用。 - 安装时遇到 eSpeak 相关的错误怎么办?
这是最常见的问题。请确保你已经为你的操作系统正确安装了 eSpeak NG,并且在安装后重启了命令行终端。如果问题依旧,请检查 eSpeak NG 是否被安装到了系统的标准路径下。 - 如何确认 GPU 加速是否生效?
首先,确保你按照 NVIDIA GPU 的方式安装了所有依赖。然后,可以运行python -c "import torch; print(torch.cuda.is_available())"命令,如果返回True,说明环境配置正确。当服务器运行时,你也可以通过任务管理器或nvidia-smi命令查看 GPU 的使用情况。 - 服务器启动时提示“端口已被占用”怎么办?
这说明你电脑上已经有其他程序占用了 8005 端口。你可以修改项目根目录下的config.yaml文件,将server.port的值改成另一个未被占用的端口号(例如8006),然后重启服务器。



























