



DeepSieve 是一个开源的检索增强生成(RAG)框架,托管于 GitHub,专注于处理复杂查询和多源数据。它通过分解查询、路由子问题、反思失败检索并融合答案,提供高效的信息筛选能力。DeepSieve 由 MinghoKwok 开发,支持处理结构化数据(如 SQL 表格、JSON 日志)和非结构化数据(如维基百科),适用于需要多步推理的场景。它强调模块化设计,用户可根据需求调整功能,适合研究人员、开发者处理复杂数据分析任务。项目于2025年7月29日发布预印本于 arXiv,完整语料库已上传至 Arkiv。
功能列表
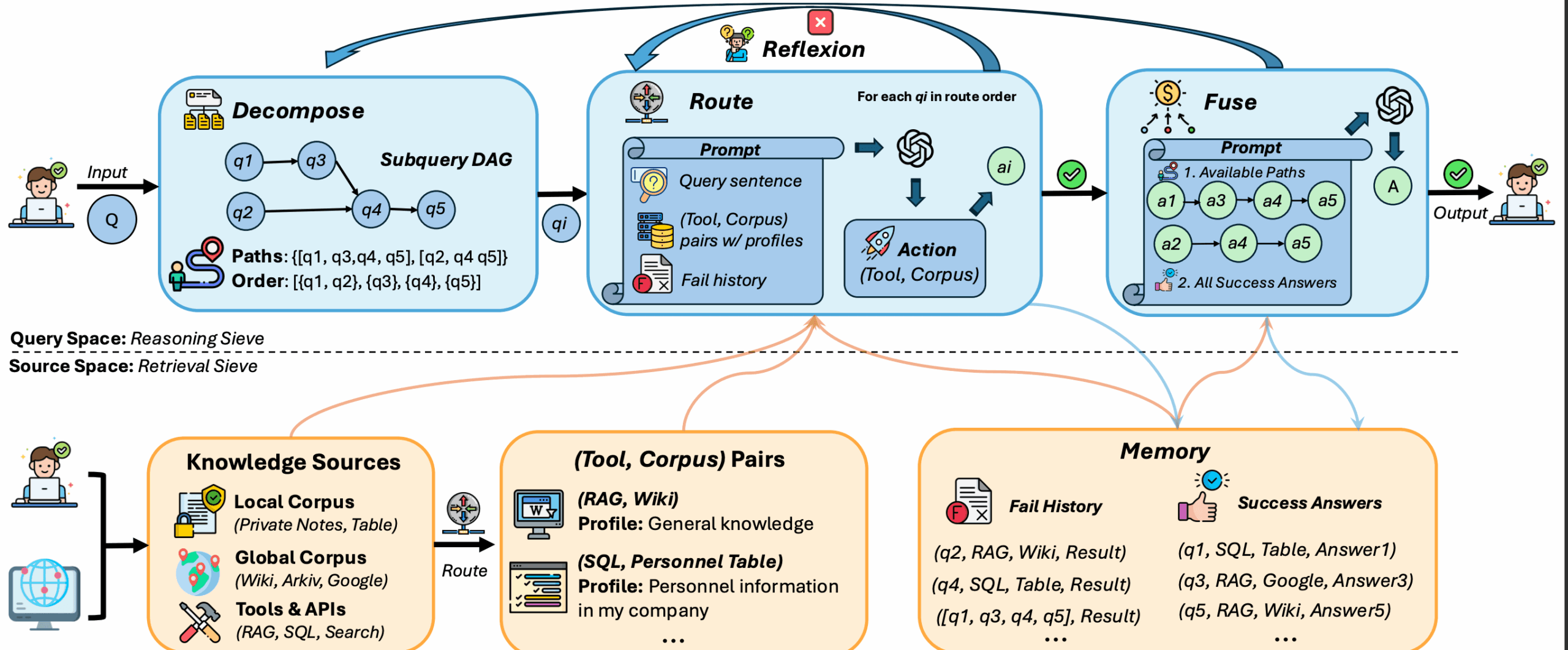
- 查询分解 :将复杂查询拆分为多个简单子问题,便于精准处理。
- 子问题路由 :将子问题智能分配到合适的工具或数据源(如本地数据库或全局知识库)。
- 反思机制 :自动检测失败的检索并重试,最多支持两次反思。
- 答案融合 :整合子问题答案,生成最终的完整响应。
- 支持多种数据源 :处理 SQL 表格、JSON 日志、维基百科等异构数据。
- 两种 RAG 模式 :提供简单(Naive)和图结构(Graph)两种检索模式,适应不同需求。
- 详细日志记录 :保存每次查询的中间结果、融合提示和性能指标,便于调试和优化。
- 模块化设计 :用户可通过命令行开关启用或禁用功能模块,灵活性高。
使用帮助
安装流程
DeepSieve 是一个基于 Python 的开源项目,需通过 GitHub 克隆仓库并配置环境。以下是详细步骤:
- 克隆仓库
在终端运行以下命令,将 DeepSieve 仓库克隆到本地:git clone https://github.com/MinghoKwok/DeepSieve.git进入项目目录:
cd DeepSieve - 安装依赖
项目依赖 Python 3.7+ 及相关机器学习和数据处理库。安装依赖:pip install -r requirements.txt如果
requirements.txt未提供,建议手动安装核心库:pip install numpy pandas scikit-learn openai推荐使用虚拟环境避免依赖冲突:
python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - 配置环境变量
DeepSieve 使用大语言模型(LLM)处理查询,需配置 API 密钥。例如,使用 DeepSeek 模型:export OPENAI_API_KEY=your_api_key export OPENAI_MODEL=deepseek-chat export OPENAI_API_BASE=https://api.deepseek.com/v1根据使用模式(Naive 或 Graph),设置 RAG 类型:
export RAG_TYPE=naive # 或 graph - 验证环境
确保所有依赖安装正确,API 密钥有效。若使用自定义数据源,检查数据文件路径是否正确配置。
运行 DeepSieve
DeepSieve 通过命令行运行,提供灵活的参数配置。以下是基本用法:
Naive RAG 模式
Naive 模式适合简单任务,运行以下命令:
export RAG_TYPE=naive
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
--dataset:指定数据集(如hotpot_qa)。--sample_size:设置处理样本数量。--decompose:启用查询分解。--use_routing:启用子问题路由。--use_reflection:启用反思机制。--max_reflexion_times:设置最大反思次数。
Graph RAG 模式
Graph 模式适合复杂查询,需图结构支持:
export RAG_TYPE=graph
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
禁用模块
用户可通过移除命令行参数禁用功能。例如:
- 不使用查询分解:移除
--decompose。 - 不使用路由:移除
--use_routing。 - 不使用反思:移除
--use_reflection。
输出结果
每次运行会生成以下文件:
- 每个查询的结果:
outputs/{rag_type}_{dataset}/query_{i}_results.jsonl - 融合提示:
outputs/{rag_type}_{dataset}/query_{i}_fusion_prompt.txt - 总体性能指标:
overall_results.txt和overall_results.json
主要功能操作
查询分解
DeepSieve 将复杂查询拆分为子问题。例如,查询“某公司2023年的收入和员工数量”会被拆分为:
- 子问题1:查找2023年公司收入。
- 子问题2:查找公司员工数量。
操作步骤:
- 输入查询到脚本或命令行。
- 运行脚本,DeepSieve 自动分解查询并显示子问题(可在日志查看)。
子问题路由
每个子问题被分配到合适的工具或数据源。例如:
- 结构化数据(如 SQL 表格)路由到数据库查询工具。
- 非结构化数据(如维基百科)路由到文本检索工具。
用户无需手动指定,DeepSieve 自动完成路由。检查日志文件query_{i}_results.jsonl可查看路由详情。
反思机制
如果某个子问题检索失败,DeepSieve 会自动重试,最多两次。反思过程记录在日志中,用户可查看失败原因和重试结果。
答案融合
DeepSieve 整合子问题答案,生成最终响应。例如,上述公司查询的答案会合并为:
- “2023年公司收入为X美元,员工数量为Y人。”
融合提示保存在query_{i}_fusion_prompt.txt,便于用户检查。
使用注意事项
- 数据准备 :确保输入数据格式正确(如 CSV、JSON),避免编码错误。
- API 密钥 :确认 LLM API 密钥有效,网络连接稳定。
- 日志检查 :运行后查看
outputs/目录,分析性能指标和错误日志。 - 社区支持 :如遇到问题,访问 GitHub Issues 页面或 arXiv 论文获取更多信息。
应用场景
- 学术研究
研究人员处理多源数据(如维基百科和实验数据库),通过 DeepSieve 快速回答复杂问题。例如,分析生物学数据集和文献中的基因关联。 - 商业数据分析
企业分析师使用 DeepSieve 处理销售数据和客户日志,回答多维度问题,如“哪些产品在2023年销量最高且客户满意度高?”。 - 隐私敏感场景
DeepSieve 支持隐私数据源(如内部数据库),无需合并数据即可处理查询,适合金融或医疗行业。 - 开源开发
开发者利用 DeepSieve 的模块化设计,扩展功能或集成到现有系统,用于定制化数据处理。
QA
- DeepSieve 支持哪些数据源?
支持 SQL 表格、JSON 日志、维基百科等,具体支持范围需参考项目文档或配置文件。 - 如何调试运行错误?
检查outputs/目录中的日志文件,查看错误详情。确保依赖库版本正确,API 密钥有效。 - Graph 模式和 Naive 模式的区别?
Naive 模式适合简单查询,速度快;Graph 模式适合复杂多步推理,精度更高但计算成本增加。 - 如何贡献代码?
Fork 仓库,修改代码后提交 Pull Request。参考CONTRIBUTING.md文件,遵循代码规范。


























