

从大型语言模型(LLM)的 API 调用,到自主化、目标驱动的智能体工作流(Agentic Workflows),人工智能的应用范式正在发生根本性转变。开源社区在这一浪潮中扮演了关键角色,催生了大量专注于特定研究任务的 AI 工具。这些工具不再是单一的模型,而是集成了规划、协作、信息检索与工具调用能力的复杂系统。本文将深入剖析十款代表性的开源研究助手,分析其技术路径、设计哲学以及在 AI 生态中的战略定位。
多智能体系统 (MAS):结构化协作与动态适应
多智能体系统(Multi-Agent Systems, MAS)通过让多个独立的智能体协同工作来解决单一智能体难以应对的复杂问题。DeerFlow 和 OWL 展示了该领域的两种主流实现路径:层级化与去中心化。
DeerFlow 代表了层级化、结构化的协作模式。它将系统解构为协调器(Coordinator)、规划器(Planner)和专家团队(Expert Teams),这种设计酷似一个组织严密的 企业结构。其工作流程是确定性的:规划器进行任务分解,协调器进行任务分配,专家智能体执行。这种模式的优势在于处理边界清晰、可被有效分解的任务时,效率极高、结果可预测。例如,在进行大规模代码库的安全审计时,DeerFlow 可以稳定地将任务分配给代码分析、漏洞检测等不同角色的智能体,并汇总报告。

项目地址:https://github.com/bytedance/deer-flow
OWL 则体现了去中心化、动态适应的协作哲学。它基于 CAMEL-AI 框架,其核心是智能体之间的“角色扮演”和“沟通协商”。与 DeerFlow 的预设分工不同,OWL 中的智能体可以根据任务的实时进展动态协商并承担不同角色。这种涌现式的协作模式,在处理开放性、非结构化问题(如跨学科的科学探索)时更具优势,因为它允许系统在没有明确解决方案路径的情况下,通过智能体间的交互自行探索出最佳协作方式。OWL 的灵活性是以牺牲部分可预测性为代价的,这代表了多智能体系统设计中的一个核心权衡。

项目地址:https://github.com/camel-ai/owl
高级检索增强生成(Advanced RAG):从信息检索到知识探索
检索增强生成(Retrieval-Augmented Generation, RAG)已成为缓解模型幻觉、引入实时信息的标准技术。WebThinker 与 Search-R1 则将其从简单的“检索-生成”模式,推向了更高级的“代理式探索”(Agentic Exploration)。
WebThinker 的核心突破在于赋予了 LLM 自主浏览(Autonomous Browsing)的能力。它超越了传统 RAG 仅从搜索引擎结果页面(SERP)或向量数据库中提取文本片段的范畴,能够模拟人类用户点击链接、深入挖掘网页内容的行为。其“思考-搜索-撰写”的闭环流程,本质上是在生成一个详尽的推理轨迹(Reasoning Trace),并通过强化学习进行优化。这使其在需要深度和广度信息的舆情分析或行业追踪任务中,能够构建更全面的知识图景。

项目地址:https://github.com/RUC-NLPIR/WebThinker
Search-R1 则将关注点放在了“搜索策略的元认知”(Meta-cognition for Search)上。它本身不是一个固定的搜索代理,而是一个用于构建和评估搜索代理的模块化框架。用户可以像配置服务器一样,自由组合 LLaMA3、Qwen2.5 等不同的大语言模型,搭配 PPO、GRPO 等强化学习算法。这种元级别(Meta-level)的抽象,使其成为一个强大的研究工具,允许开发者探索“AI 如何学习去搜索”这一根本性问题,而不是仅仅满足于搜索结果本身。

项目地址:https://github.com/PeterGriffinJin/Search-R1
边缘智能与数据主权:本地化 AI 的兴起
随着对数据隐私和响应速度的要求日益提高,将 AI 计算从云端推向边缘设备成为必然趋势。Alita 和 AgenticSeek 是这一趋势下的代表性解决方案。
Alita 的核心理念是通过标准化接口来简化工具的集成与复用。它提出的模型上下文协议(Model Context Protocol, MCP)可以被理解为一种“AI 工具的应用程序二进制接口(ABI)”。通过为不同工具定义统一的交互格式,Alita 无需为每个新工具进行复杂的适配,即可实现快速接入和功能扩展。这种“即插即用”的特性,使其单模块推理架构能够保持轻量,同时具备强大的自我进化潜力,极大地降低了个人和小型团队构建复杂 AI 应用的门槛。
项目地址:https://github.com/CharlesQ9/Alita
AgenticSeek 将数据主权(Data Sovereignty)推向了极致。它是一个完全在本地设备运行的 AI 代理,不依赖任何云端 API 调用,确保了数据绝对不出本地。其内部的任务-智能体匹配机制,可以被看作是一种轻量级的设备端“专家混合(Mixture of Experts, MoE)”模型,根据任务类型(浏览、编码、规划)智能调度最合适的本地资源。这使其在处理金融、医疗等高度敏感数据,或在离线环境中工作时,具有不可替代的优势。
项目地址:https://github.com/Fosowl/agenticSeek
模型能力解锁:监督微调与强化学习的路径之辩
如何高效地教会模型掌握新技能,是 AI 领域的核心议题。SimpleDeepSearcher 和 ReCall 分别代表了两种主流技术路径的创新应用。
SimpleDeepSearcher 的实践证明,高质量的监督微调(Supervised Fine-Tuning, SFT)同样能实现过去被认为只有强化学习(RL)才能达到的复杂研究能力。其成功的关键在于训练数据的构建方式。它并非采用简单的(输入,最终输出)数据对,而是通过模拟真实网页交互,生成包含中间步骤和决策过程的“推理轨迹”数据。这种对“思考过程”的模仿学习,比从零开始的强化学习探索成本更低、训练过程更稳定,为在有限资源下训练高性能专用模型提供了一条极具价值的捷径。

项目地址:https://github.com/RUCAIBox/SimpleDeepSearcher
ReCall 则专注于纯粹的强化学习路径,致力于解决 LLM “学会使用工具”的泛化能力问题。其最引人注目的特点是无需人工标注的工具调用数据。模型通过与环境(如 API 端点)的直接交互,从返回结果(成功、失败、错误信息)中获得反馈,并以此作为学习信号,不断优化其工具调用策略。这类似于从 AI 反馈中进行强化学习(RLAIF),使模型能够自主学会在复杂的任务流中调用 OpenAI 风格的工具。这种能力是实现通用人工智能(AGI)道路上的关键一步。
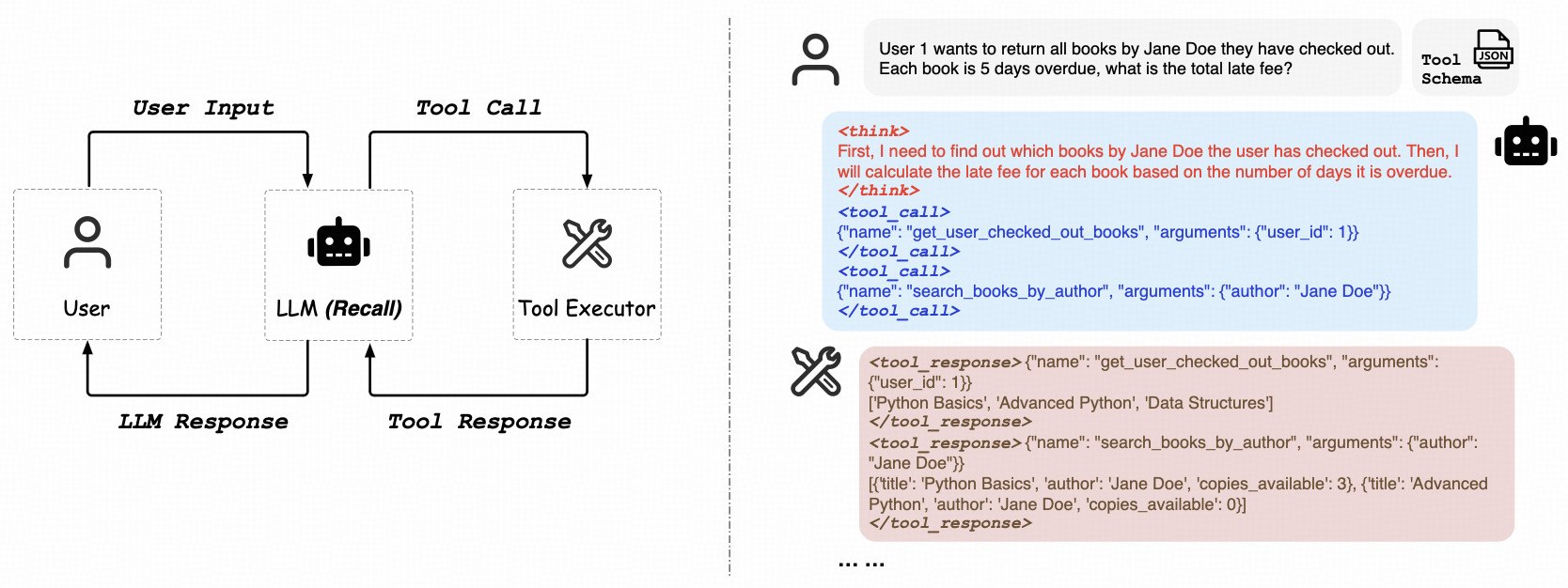
项目地址:https://github.com/Agent-RL/ReCall
端到端平台与研究严谨性
当基础能力成熟后,将多种功能整合为端到端平台,并确保输出结果的可靠性,成为更高层次的追求。
Suna 的定位是一个“AI 原生的工作流 IDE”。它并不专注于某项底层 AI 技术的创新,而是着眼于提升开发者的工作体验(Developer Experience, DX)。通过将网页浏览、文件处理、命令行执行乃至网站部署等功能无缝集成,Suna 旨在消除技术工作流中不同工具间的切换成本。它更像是一个面向开发者的 Zapier 或 Make,将 AI 能力深度整合到项目管理和执行的全流程中。

项目地址:https://github.com/kortix-ai/suna
DeepResearcher 则直接应对了 AI 在严肃研究领域最大的挑战:可靠性。它通过端到端的强化学习,训练模型建立一套严谨的研究策略。其核心的“自我反思”机制,代表了一种“认知校准”(Epistemic Humility)。当模型在验证多源信息后,依然无法得出高置信度的结论时,它会主动选择“承认不知道”,而不是像许多模型那样自信地产生幻觉。这种对不确定性的认知和坦白,是 AI 从一个“信息生成器”转变为一个值得信赖的“研究伙伴”所必需的品质。

项目地址:https://github.com/GAIR-NLP/DeepResearcher







































