

随着大语言模型范式与工程实践的演进,一系列旨在模仿人类研究过程的智能体应用应运而生。这些智能体不仅仅是简单的问答工具,而是能够自主规划、执行、反思并综合信息的复杂系统。本文将解构不同研究型智能体框架的架构设计与功能实现,从 OpenAI 官方发布的 DeepResearch 指南这一思想源头出发,深入剖析多个主流开源框架的内在差异与设计哲学,为开发者和使用者在选择工具时提供一份系统化的战略参考。
开源深度研究智能体框架
核心理念对比
当前市场上有众多通用智能体框架(如 Auto-GPT、AutoGen 等)能够执行研究任务,但本文聚焦于六个为深度研究场景进行过特定架构优化的开源项目。
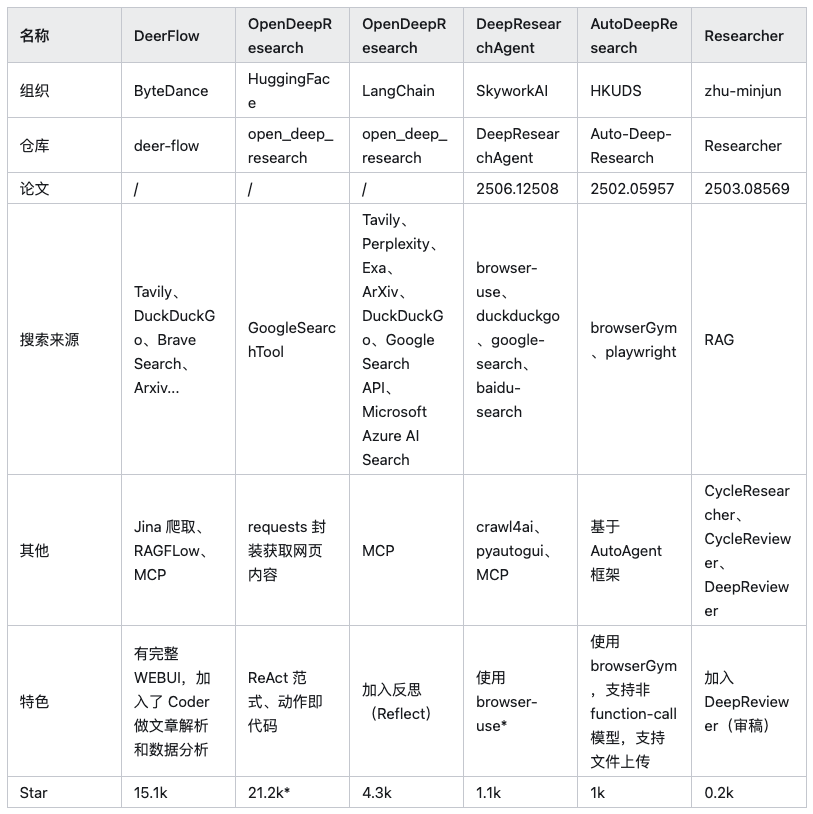
注:上表中 HuggingFace/OpenDeepResearch 的 Star 数来自其核心依赖的 SmolAgents 项目。
在深入分析每个框架前,需要明确一点:深度研究的本质是信息获取与整合。因此,类似 browser-use 这样由 AI 驱动的浏览器自动化工具是所有此类框架的重要辅助。它们负责执行动态网页的加载、与页面元素交互、提取数据等任务,解决了传统网络爬虫难以处理 JavaScript 渲染内容的痛点,但并非本文讨论的核心——框架本身。
OpenAI 指南:奠定三步范式
OpenAI 的官方文档中有一篇名为 Deep Research 的指南,它提出的架构是后续几乎所有研究型智能体的思想源头。其核心理念是放弃用单一、庞大的提示词(Prompt)一步到位解决问题的幻想,因为这种方式极其脆弱且难以调试。指南提倡将复杂研究任务拆解为三个独立的模块化流程:规划 (Plan) -> 执行 (Execute) -> 合成 (Synthesize)。这是一种典型的“分而治之”策略,旨在克服大语言模型在长程推理、事实一致性和上下文长度限制等方面的固有挑战。

- 规划 (Plan): 使用一个具备高度抽象和逻辑推理能力的高阶模型(如
GPT-4o),将用户的主问题分解为一系列具体的、可独立研究的、详尽的子问题。这一步的质量决定了研究的广度和深度。 - 执行 (Execute): 并行处理每个子问题。对每个子问题,调用外部搜索 API 获取信息,并让模型对单一信息源进行初步总结和事实提取。这是一个高度并行的信息收集阶段。
- 合成 (Synthesize): 将所有子问题的答案汇总,再次交由高阶模型进行最终的整合、分析和润色,撰写成一篇逻辑连贯、结构清晰的最终报告。
实施策略与最佳实践
基于这一核心架构,以下是几项关键的实践策略:
1. 为正确的任务选择正确的模型
这是成本与性能优化的核心。不同阶段需要不同类型的“智能”。“规划”和“合成”阶段要求强大的全局推理、逻辑组织和创造性生成能力,必须使用 GPT-4o 或 GPT-4 Turbo 这类顶级模型,因为它们的表现决定了最终报告的质量上限。而在“执行”阶段,对单个网页进行总结的任务更侧重于信息提取和事实浓缩,使用 GPT-3.5-Turbo 或其他更快的模型即可在保证质量的同时,大幅降低成本和延迟。一个深度研究请求可能触发数十次 API 调用,若不进行模型分级,成本会迅速攀升。
2. 并行处理以最大化效率
研究的子问题通常相互独立,串行处理极为耗时。在“执行”阶段,一旦生成子问题列表,就应通过异步编程(如 Python 的 asyncio)并行发起研究请求。这能将数分钟的流程缩短至一分钟以内。但开发者必须关注 API 供应商的速率限制(Rate Limits),尤其是 TPM (每分钟处理的令牌数)。并行调用会瞬间产生大量请求,超出 TPM 限制将导致请求失败,因此需要设计合理的请求队列和重试机制。
3. 使用函数调用或 JSON 模式保证结构化输出
为了保证工作流的稳定可靠,应始终让模型返回机器可读的结构化数据,而不是让代码去解析不稳定的自然语言文本。OpenAI 的“函数调用”(Function Calling)或“JSON 模式”功能是实现这一点的最佳方式。它相当于在代码和 LLM 之间建立了一个稳固的 API 契约。在“规划”阶段,可以强制模型输出包含所有子问题字符串的 JSON 列表;在“执行”阶段,同样可以要求模型以固定的 JSON 格式返回结果,例如 {"summary": "...", "key_points": [...]}。
4. 集成高质量的外部搜索工具
语言模型本身不具备实时联网能力,其知识也存在滞后性。因此,必须集成一个或多个高质量的搜索 API(如 Google Search API、Brave Search API、Serper 等)来获取实时、广泛的信息。在提示词中明确告知模型它可以使用这些工具,并通过函数调用等方式将工具的输出结果返回给模型,是赋予其研究能力的基础。
5. 精心设计各阶段的提示词 (Prompt Engineering)
提示词是决定各环节质量的关键。每个阶段的提示词都应精心设计,以引导模型扮演正确的角色并产出期望的结果。以下是官方指南中提供的输入样例,极具参考价值。
初始问题 (Initial Question):
Research the economic impact of semaglutide on global healthcare systems.
Do:
- Include specific figures, trends, statistics, and measurable outcomes.
- Prioritize reliable, up-to-date sources: peer-reviewed research, health
organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical
earnings reports.
- Include inline citations and return all source metadata.
Be analytical, avoid generalities, and ensure that each section supports
data-backed reasoning that could inform healthcare policy or financial modeling.
研究索马鲁肽对全球医疗保健系统的经济影响。
应做的:
- 包含具体的数字、趋势、统计数据和可衡量的成果。
- 优先考虑可靠、最新的来源:同行评审的研究、卫生组织(例如世界卫生组织、美国疾病控制与预防中心)、监管机构或制药公司
的盈利报告。
- 包含内联引用并返回所有来源元数据。
进行分析,避免泛泛而谈,并确保每个部分都支持
数据支持的推理,这些推理可以为医疗保健政策或财务模型提供参考。
问题澄清 (Question Clarification):
这一步的目的是让智能体像一个真正的顾问一样,在开始昂贵的研究前,确保完全理解了用户的意图。
You are talking to a user who is asking for a research task to be conducted. Your job is to gather more information from the user to successfully complete the task.
GUIDELINES:
- Be concise while gathering all necessary information
- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.
- Use bullet points or numbered lists if appropriate for clarity.
- Don't ask for unnecessary information, or information that the user has already provided.
IMPORTANT: Do NOT conduct any research yourself, just gather information that will be given to a researcher to conduct the research task.
您正在与一位请求开展研究任务的用户交谈。您的工作是从用户那里收集更多信息,以成功完成任务。
指导原则:
- 收集所有必要信息时务必简洁
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 为清晰起见,请根据需要使用项目符号或编号列表。
- 请勿询问不必要的信息或用户已提供的信息。
重要提示:请勿自行进行任何研究,只需收集将提供给研究人员进行研究任务的信息即可。
用户 Prompt 改写 (User Prompt Rewriting):
这一步是将用户的口语化请求,转化为一份给“研究员智能体”的、详尽且无歧义的书面指令。
You will be given a research task by a user. Your job is to produce a set of
instructions for a researcher that will complete the task. Do NOT complete the
task yourself, just provide instructions on how to complete it.
GUIDELINES:
1. **Maximize Specificity and Detail**
- Include all known user preferences and explicitly list key attributes or
dimensions to consider.
- It is of utmost importance that all details from the user are included in
the instructions.
2. **Fill in Unstated But Necessary Dimensions as Open-Ended**
- If certain attributes are essential for a meaningful output but the user
has not provided them, explicitly state that they are open-ended or default
to no specific constraint.
3. **Avoid Unwarranted Assumptions**
- If the user has not provided a particular detail, do not invent one.
- Instead, state the lack of specification and guide the researcher to treat
it as flexible or accept all possible options.
4. **Use the First Person**
- Phrase the request from the perspective of the user.
5. **Tables**
- If you determine that including a table will help illustrate, organize, or
enhance the information in the research output, you must explicitly request
that the researcher provide them.
6. **Headers and Formatting**
- You should include the expected output format in the prompt.
- If the user is asking for content that would be best returned in a
structured format (e.g. a report, plan, etc.), ask the researcher to format
as a report with the appropriate headers and formatting that ensures clarity
and structure.
7. **Language**
- If the user input is in a language other than English, tell the researcher
to respond in this language, unless the user query explicitly asks for the
response in a different language.
8. **Sources**
- If specific sources should be prioritized, specify them in the prompt.
- For product and travel research, prefer linking directly to official or
primary websites...
- For academic or scientific queries, prefer linking directly to the original
paper or official journal publication...
- If the query is in a specific language, prioritize sources published in that
language.
6. 在关键节点引入人工审核 (Human-in-the-Loop)
对于严肃或高风险的研究任务,完全自动化的流程是不可靠的。引入“人在回路”不仅是一个功能,更是一种关于人机协作的哲学。一个有效的实践是在“规划”阶段后加入人工审核环节,由用户审查、修改并确认模型生成的子问题列表,确保研究方向无误后,再启动成本高昂的“执行”阶段。这既能避免“垃圾进,垃圾出”,也确保了最终结果的问责性。
开源架构分析
下面我们依次剖析每个框架的架构特点。
ByteDance/DeerFlow:基于图的分层多智能体系统
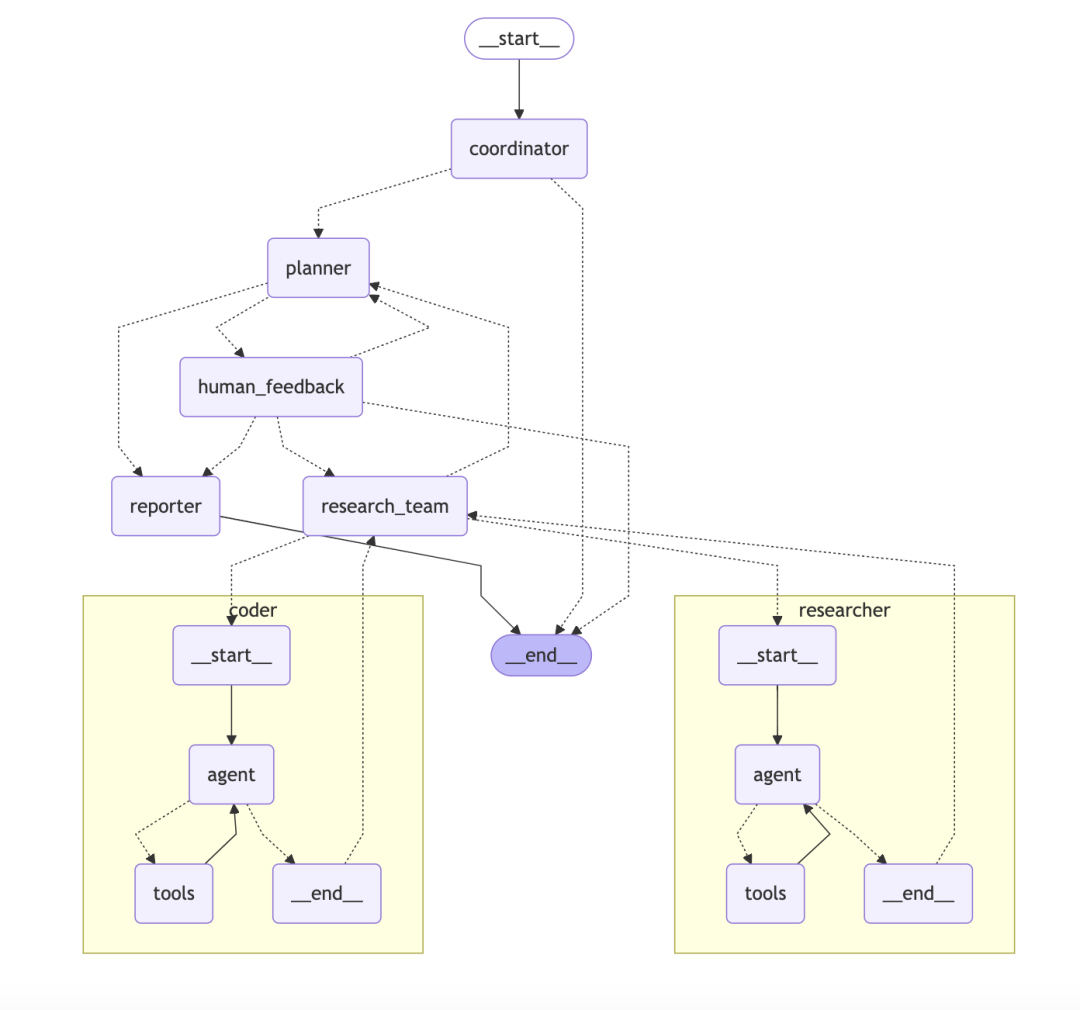
DeerFlow 的架构是一个模块化的分层多智能体系统,如同一个目标明确、分工清晰的自动化研究团队。
- 核心架构: 系统由多个角色协同工作:
- 协调器 (Coordinator): 作为项目经理,接收用户请求,启动并管理整个流程。
- 规划器 (Planner): 作为策略师,将复杂问题分解为结构化步骤。
- 研究团队 (Research Team): 作为执行者,内部包含负责网络搜索的“研究员”和负责执行代码的“程序员”。
- 报告员 (Reporter): 作为最终产出者,将所有信息整合成报告、播客甚至 PPT。
- 技术特点:
DeerFlow的技术亮点在于其构建于LangChain和LangGraph之上。LangGraph是一个关键组件,它允许开发者将多智能体工作流构建为状态图 (Stateful Graphs)。每个智能体或工具可以被视为图中的一个节点,而工作流程的走向则由边 (Edges) 来定义。这种方式天然支持包含循环的复杂流程,例如“反思-修正”循环,使得整个研究过程不仅是线性的,而且是可追溯、可调试的。
专栏作家评论: DeerFlow 的设计思路清晰,分工明确,适合需要稳定、可扩展且支持复杂工作流的团队或企业级应用。它通过引入 LangGraph,将智能体协作从简单的链式调用提升到了可管理的、可循环的图状网络,更像一个“研究流程管理平台”,而非一个简单的工具。
HuggingFace/OpenDeepResearch:代码即动作的极简哲学
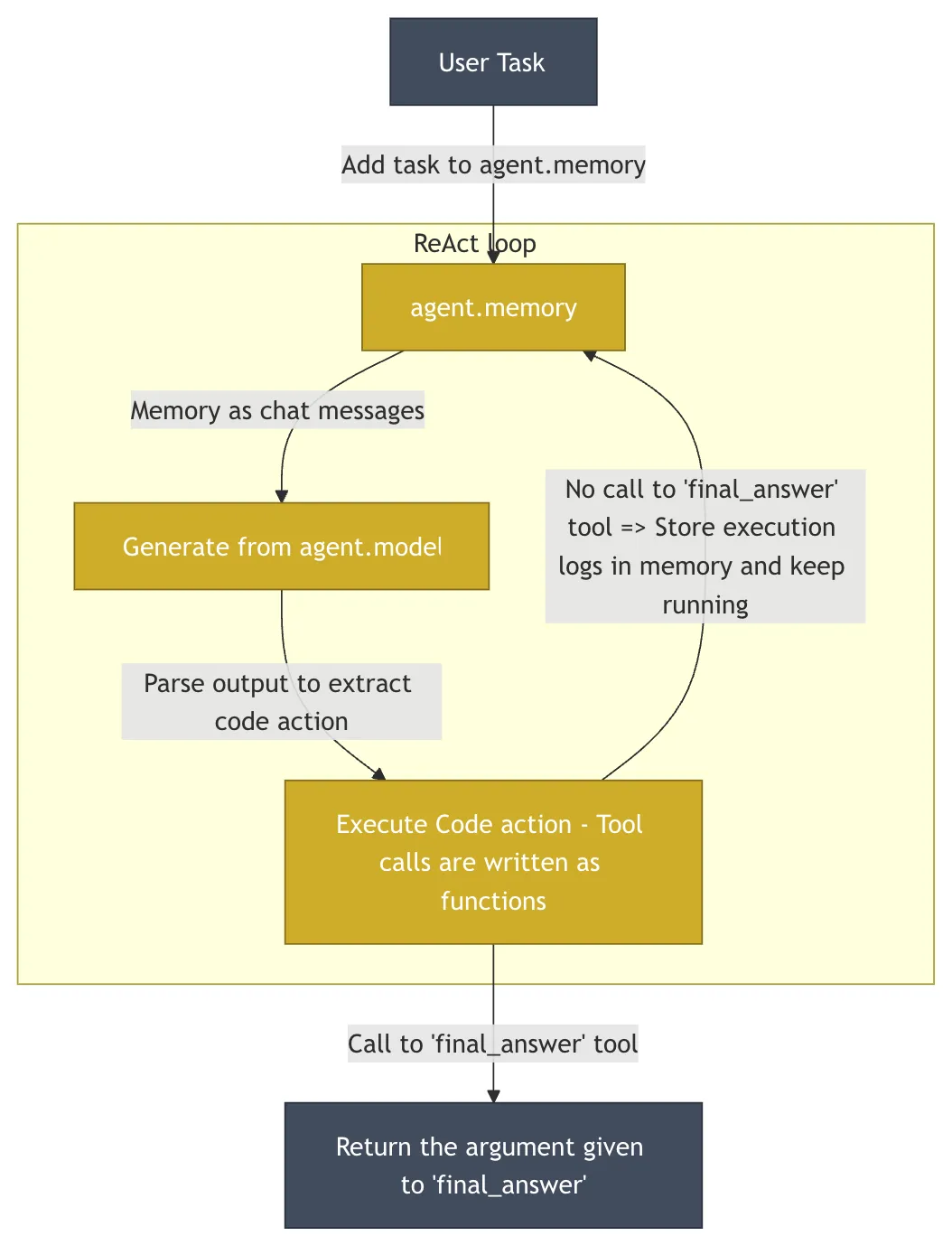
HuggingFace 的 OpenDeepResearch 项目,其核心由 smolagents 驱动,采取了与 DeerFlow 截然不同的设计哲学。该项目在 GAIA (General AI-Assisted Agent)——一个旨在通过真实世界的任务来衡量通用 AI 智能体能力的权威基准——的验证集上实现了 55% 的 pass@1 分数。这一成绩虽然低于 ChatGPT 的 67%,但作为一个开源实现,已经展示了其强大的能力。
- 核心思想: 简洁与最少抽象。
smolagents的代码库被刻意控制在极小的规模(约1000行),避免了许多框架中常见的过度抽象,为开发者提供了极高的透明度和控制权。 - 核心架构: 其核心是“代码智能体” (
CodeAgent)。智能体的动作直接表现为Python代码片段,而不是JSON对象。LLM生成一小段Python代码来执行下一步操作。这种方法的表现力远超JSON,因为代码天然支持循环、条件、函数定义等复杂逻辑。然而,执行 AI 生成的任意代码存在巨大安全风险。为此,smolagents支持在如E2B这样的沙盒环境 (Sandbox) 中运行代码。E2B提供一个隔离的云端Linux环境,AI 生成的代码在其中执行,可以访问文件系统和网络,但无法影响宿主系统,从而在赋予智能体强大能力的同时确保了安全性。
专栏作家评论: smolagents 的“代码即动作”理念极具吸引力,它回归了编程的本质,赋予了智能体前所未有的灵活性。对于希望深度定制、完全掌控智能体行为的开发者而言,这是一个绝佳的选择。它的哲学是:给予开发者最大的权力,并提供保障安全的护栏。
LangChainAI/OpenDeepResearch:图状工作流与元认知反思
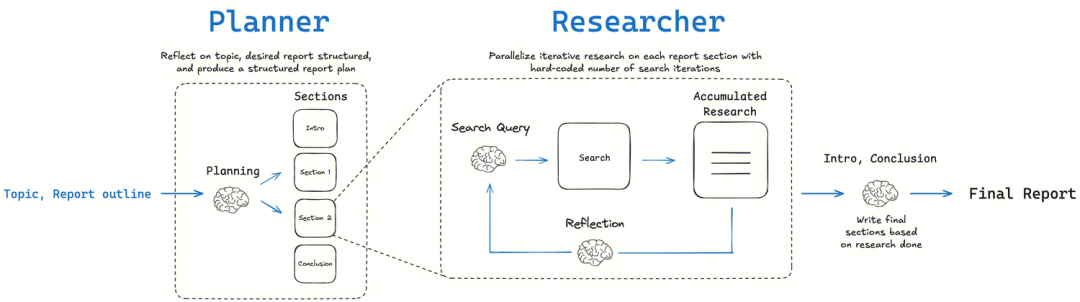
LangChain 社区的 open_deep_research 项目核心是一个多阶段、迭代和自反思的工作流,旨在模拟人类专家的研究过程。
- 核心理念: 规划-搜索-反思-撰写 (Plan-Search-Reflect-Write)。该架构的关键在于“反思”环节。这不仅仅是检查错误,更是一种元认知 (Metacognition) 的体现,即“思考自己的思考过程”。在收集初步信息后,智能体会评估当前信息的完备性、是否存在矛盾或知识空白。如果发现不足,它会生成新的、更精确的搜索查询,进入下一轮迭代。
- 实现方式:
- 图状工作流 (Graph-based Workflow): 如同
DeerFlow,它主要使用LangGraph构建。研究的每一步都被建模为图中的一个节点,使得整个流程高度可视化、可追溯且易于调试。这种方式非常适合需要人工干预和高精度控制的场景。 - 多智能体迭代循环 (Multi-agent Iterative Loop): 通过递归的研究循环,智能体在每次循环中评估已有信息,生成新问题,并进一步搜索。此方式分为两种模式:
简单模式 (Simple)直接进入单一迭代循环,速度快,适合具体问题;深度模式 (Deep)包含初始规划并为每个子主题部署并行研究器,更深入全面,适合复杂主题。
- 图状工作流 (Graph-based Workflow): 如同
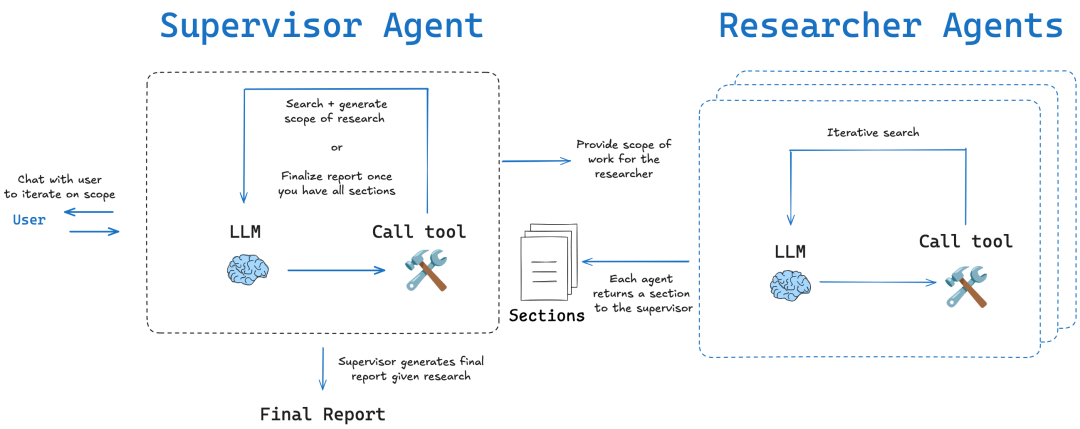
专栏作家评论: LangChain 的版本是模块化和灵活性的典范。它将“自我反思”这一认知科学概念成功地工程化,通过 LangGraph 为复杂、非线性的研究任务提供了强大的建模能力,是需要将研究流程产品化的团队的理想选择。
SkyworkAI/DeepResearchAgent:经典分层与关注点分离
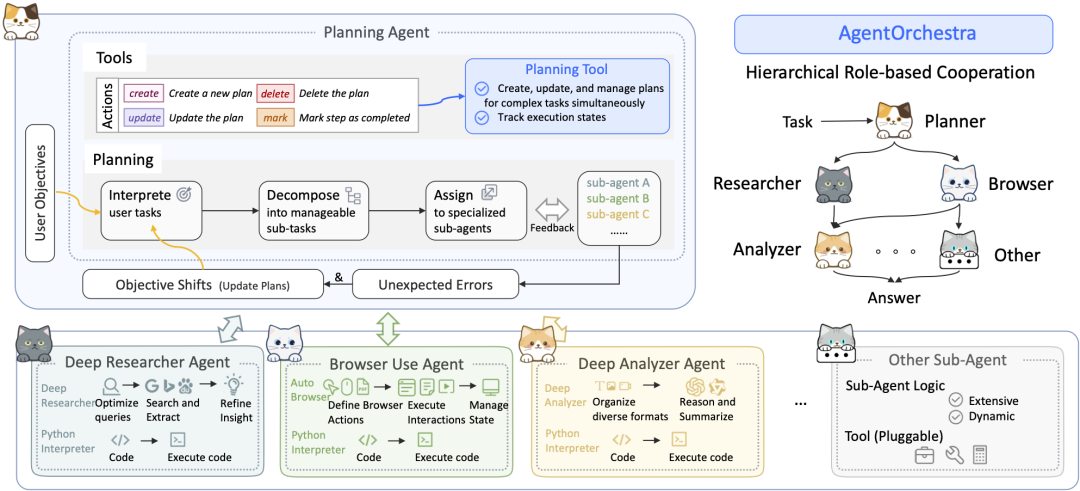
SkyworkAI 的 DeepResearchAgent 采用了明确的两层(Two-Layer)架构,这是一个在软件工程中非常经典的设计模式,其核心是关注点分离 (Separation of Concerns)。
- 核心架构:
- 第一层:顶层规划智能体 (Top-Level Planning Agent): 扮演“策略层”或“业务逻辑层”。它不执行具体的研究任务,而是负责理解用户意图,将宏大目标分解成一系列可管理的子任务,并制定工作流计划。
- 第二层:底层专业智能体 (Specialized Lower-Level Agents): 扮演“执行层”或“服务层”。由多个具备不同专业技能的智能体组成,如负责信息分析的“深度分析器”、执行网络搜索的“深度研究员”和操作浏览器的“浏览器使用者”,它们忠实地执行上层分配的任务。
- 架构启发: 该项目在其
README中明确提到其架构受到了smolagents的启发,并在其基础上进行了模块化和异步化改进。这体现了它试图结合smolagents的简洁理念与更结构化的多智能体协作模式。
专栏作家评论: DeepResearchAgent 的两层架构在“规划”与“执行”之间实现了漂亮的解耦。这种设计条理清晰,扩展性强,未来可以方便地在第二层加入更多专业智能体(如数据可视化、代码执行等),而无需改动顶层的核心规划逻辑。这是一种务实且工程化的实现。
zhu-minjun/Researcher:对抗性的自我批判机制
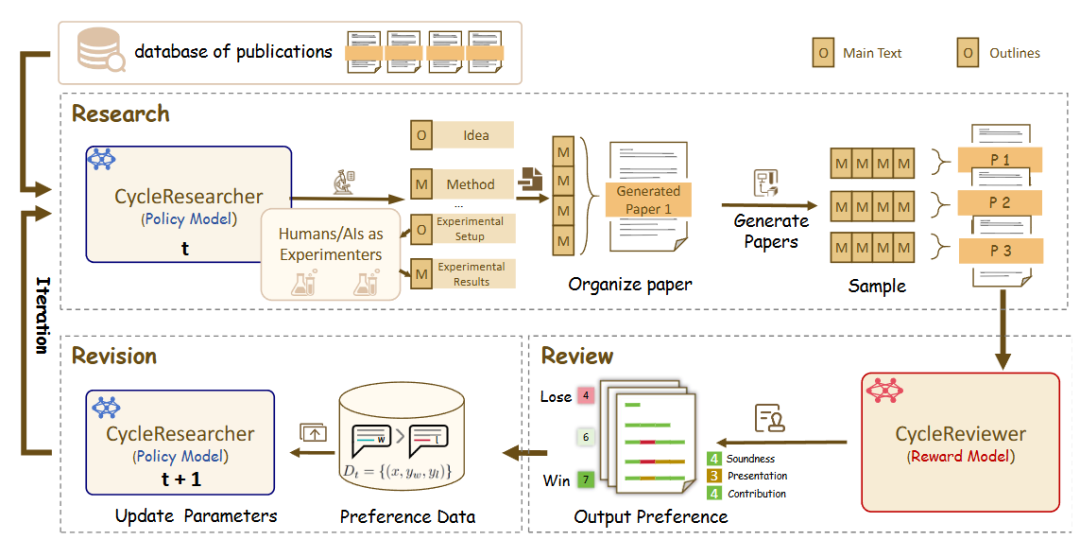
zhu-minjun/Researcher 的架构同样是分阶段的多智能体协作,但其最显著的特点是引入了独立的、甚至可称为对抗性的“自我批判”环节。
- 核心架构:
- 规划智能体: 制定研究计划和大纲。
- 并行执行智能体: 为每个子主题启动独立的执行智能体,并行收集信息。
- 整合与初稿生成: 汇总所有结果,形成初稿。
- 批判与修正智能体: 这是架构的亮点。它将“反思”具象化为一个独立的“批判智能体”。这个智能体像一个严谨的、持怀疑态度的审稿人,专门负责挑战初稿的质量,根据预设规则(如事实准确性、观点客观性、逻辑链完整性、是否存在偏见)提出具体的、有建设性的修改意见。系统随后根据这些反馈进行修正,形成一个迭代优化的闭环。
- DeepReviewer: 在其
Best模式下,项目通过名为DeepReviewer的模块实现这种全面的审核体验,它甚至可以模拟多位持有不同观点的审核者 (multi-auditor simulation),对报告进行压力测试,这类似于学术界的同行评审(Peer Review)过程。
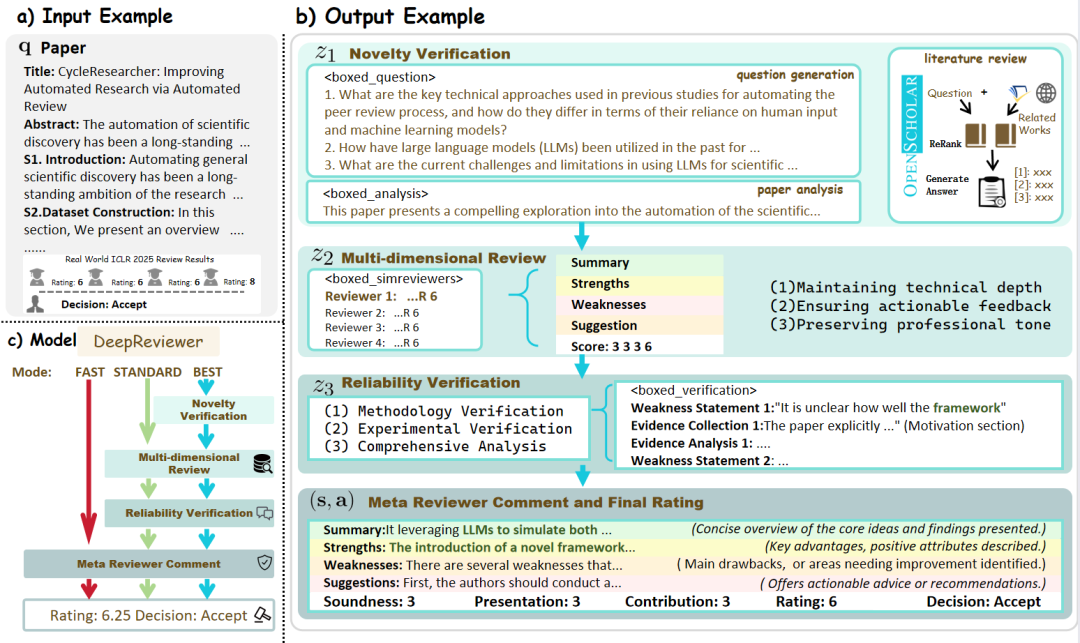
专栏作家评论: 该项目将“反思”从一种内在状态,升级为一种外在的、结构化的对抗过程。这种“左右互搏”式的设计,使其不仅仅是一个信息的聚合器,更是一个不断通过自我挑战来提升内容质量、力求客观与全面的“研究员”。
商业化深度研究智能体观察
分析完面向开发者的开源框架后,面向终端用户的商业化应用则提供了更无缝、更产品化的体验。
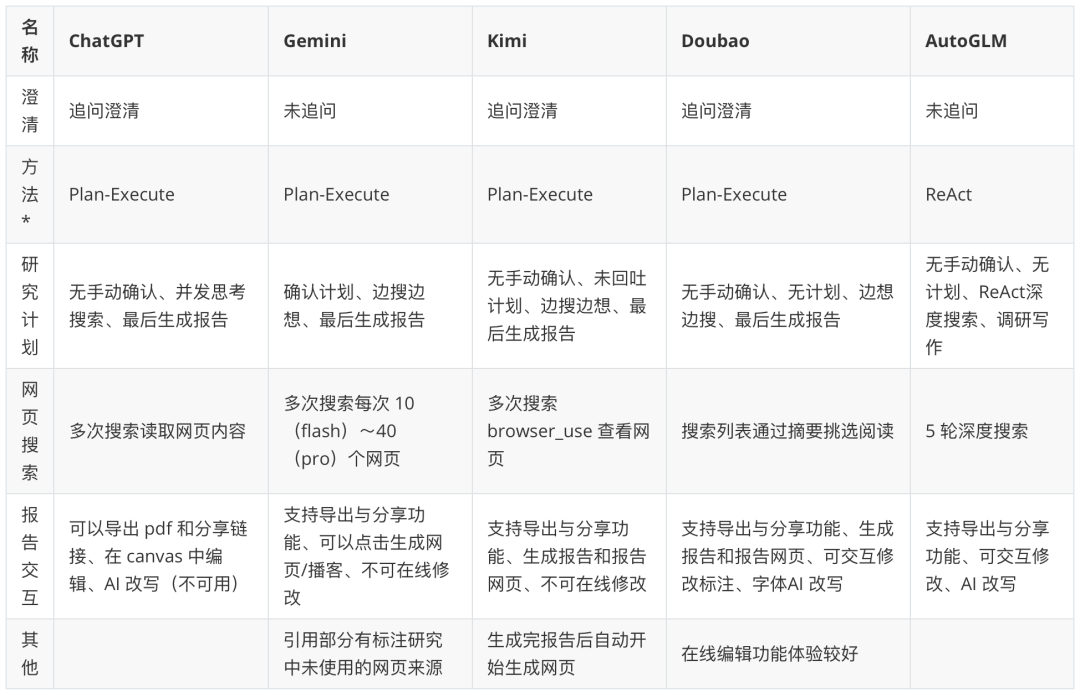
注:表中“智能体范式”为基于产品行为的推测。关注更多优秀的深度研究智能体:https://www.kdjingpai.com/ai-learning/research-assistant/
开源框架暴露的是“引擎”,而商业产品则将“引擎”优雅地隐藏在精美的“驾驶舱”之下。以 Kimi 为例,其在处理深度研究问题时,用户无需关心背后的规划、执行、合成步骤。用户提出一个复杂问题,Kimi 会自动执行内部的研究流程:规划搜索关键词,并发访问多个网络来源,利用其长达数百万字的上下文窗口实时消化和整合信息,最后以流畅的对话形式呈现一份附带引用来源的综合性回答。
其他产品如 ChatGPT、Gemini 等,也都在通过 CoT (Chain of Thought)、Tree of Thoughts 或内部集成的多智能体流程,不断提升其完成复杂研究任务的能力。商业产品的竞争焦点在于:搜索结果的准确性和实时性、信息整合的深度与洞察力、以及最终报告的交互性(如可点击的引用、图表生成、追问建议等)。它们将开源世界中复杂的架构,包装成了普通用户触手可及的强大功能。

























