



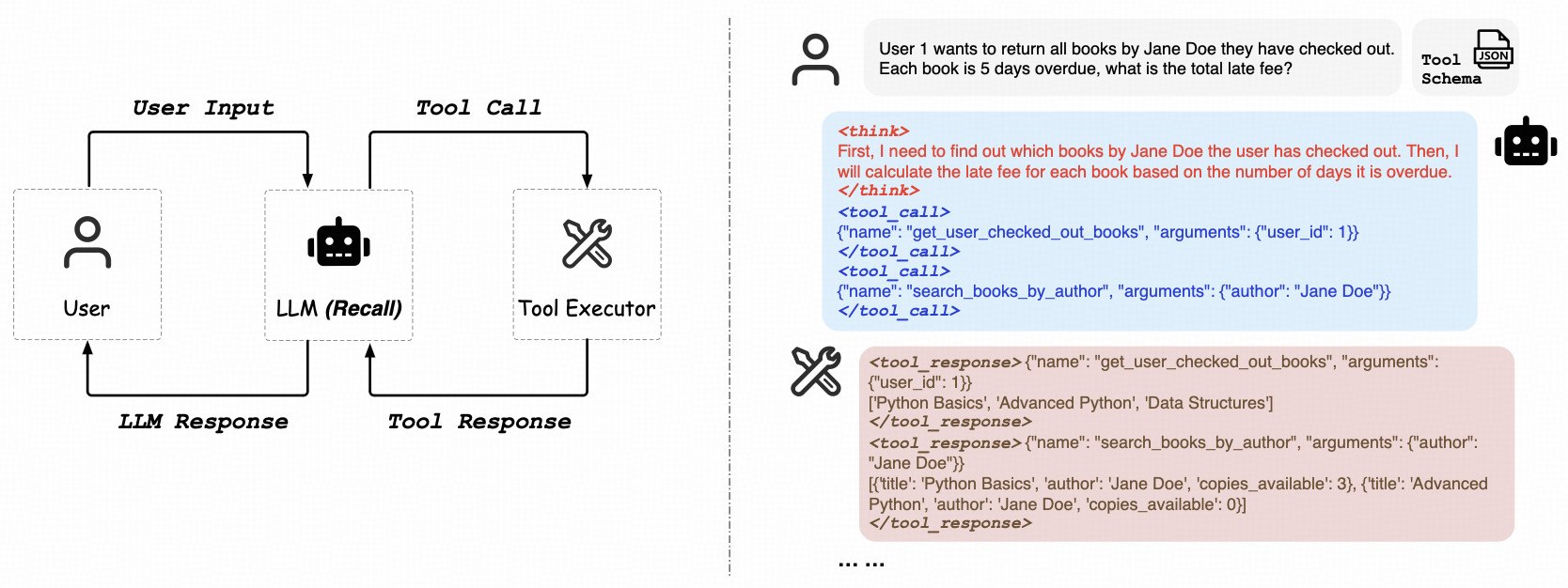
ReCall 是一个开源框架,旨在通过强化学习训练大语言模型(LLM)进行工具调用和推理,无需依赖监督数据。它让模型能够自主使用和组合外部工具,如搜索、计算器等,解决复杂任务。ReCall 支持用户自定义工具,适合开发通用智能体。项目基于 Qwen2.5 模型,提供合成数据集 SynTool 和 MuSiQue 数据集,支持多步任务推理。用户可通过 GitHub 获取代码、数据和文档,快速上手。ReCall 是 ReSearch 的升级版,功能更全面,适用于多场景工具推理开发。
功能列表
- 通过强化学习训练大模型,无需监督数据,支持自主工具调用。
- 支持用户定义任意工具,灵活适配多种任务场景。
- 提供 SynTool 合成数据集,包含多样化环境和复杂多步任务。
- 集成 FlashRAG 评估环境,用于多跳问答任务验证。
- 基于 FastAPI 和 SGLang,提供高效的沙盒和模型服务。
- 支持 MuSiQue 数据集,结合 Wikipedia 搜索工具进行数据预处理。
- 提供详细脚本和文档,方便用户自定义数据和模型训练。
使用帮助
ReCall 是一个面向开发者的开源项目,托管在 GitHub 上,用户可以通过克隆代码、安装依赖和运行示例脚本快速上手。以下是详细的使用指南,涵盖安装、主要功能操作和开发流程,帮助用户从零开始使用 ReCall。
安装流程
- 克隆代码库
打开终端,运行以下命令克隆 ReCall 仓库:git clone https://github.com/Agent-RL/ReCall.git cd ReCall - 安装依赖
ReCall 依赖 Python 环境,推荐使用 Python 3.8 或以上版本。安装核心依赖:pip3 install -e . pip3 install flash-attn --no-build-isolation如果需要运行基于 FlashRAG 的 Wikipedia RAG 系统,需额外安装
faiss-gpu:conda install -c pytorch -c nvidia faiss-gpu=1.8.0依赖包括
transformers、vllm==0.8.4、sglang等,完整列表见setup.py。 - 下载预处理数据
ReCall 提供预处理的 SynTool 和 MuSiQue 数据集,用于训练和评估。用户可直接下载:# 访问提供的下载链接(见 GitHub README)或者,用户可运行
data/prepare_musique_recall.py脚本,自定义生成 MuSiQue 数据,结合 Wikipedia 搜索工具。 - 启动模型服务
ReCall 使用 SGLang 进行模型服务。启动服务示例:python3 -m sglang.launch_server \ --served-model-name {trained/model/name} \ --model-path {trained/model/path} \ --tp 2 \ --context-length 8192 \ --enable-metrics \ --dtype bfloat16 \ --host 0.0.0.0 \ --port 80 \ --trust-remote-code \ --disable-overlap \ --disable-radix-cache用户可替换
{trained/model/name}和{trained/model/path}为自己的模型名称和路径。
主要功能操作
ReCall 的核心功能是通过强化学习训练大模型进行工具调用推理。以下是主要功能和操作流程:
- 工具调用推理
ReCall 允许模型自主选择和使用工具,例如搜索、计算器或自定义工具。核心类ReCall负责模型生成和工具执行的协调。用户可参考scripts/inference/re_call_use_case.py示例脚本,了解如何调用工具完成任务。例如:- 输入一个复杂问题(如多跳问答)。
- 模型通过强化学习选择合适的工具(如 Wikipedia 搜索)。
- 返回结构化的推理结果。
用户只需加载训练好的模型,调用ReCall类接口,传入问题和工具配置即可。
- 合成数据集生成
ReCall 提供 SynTool 数据集,支持生成多样化环境和多步任务数据。用户可运行data/prepare_musique_recall.py脚本,生成自定义数据集。例如:python data/prepare_musique_recall.py脚本会根据用户定义的工具(如 Wikipedia 搜索)生成训练数据,适用于复杂推理任务。生成的训练数据可直接用于模型训练。
- 多跳问答评估
ReCall 使用 FlashRAG 作为多跳问答的评估环境。用户可下载评估数据集并运行测试:# 下载 FlashRAG 评估数据(见 GitHub 说明)评估结果可验证模型在多步推理任务中的表现,适用于测试工具调用能力。
- 自定义工具开发
用户可定义任意工具,扩展 ReCall 的功能。例如,添加一个计算器工具:- 在代码中定义工具接口,指定输入输出格式。
- 将工具配置集成到
ReCall类中。 - 运行训练或推理脚本,测试新工具效果。
具体实现可参考 GitHub 提供的文档和示例代码。
特色功能操作
ReCall 的特色在于无需监督数据,通过强化学习实现工具调用推理。以下是特色功能的使用方法:
- 强化学习训练:ReCall 使用
verl框架进行强化学习训练。用户可配置训练参数,运行训练脚本:# 示例训练命令(具体参数见 GitHub 文档) python train.py --config {config_file}训练过程利用 SynTool 和 MuSiQue 数据集,优化模型的工具选择和推理能力。
- 灵活工具组合:用户可通过配置文件定义多个工具(如搜索、数据库查询等),模型会根据任务自动选择和组合工具。操作步骤:
- 编辑工具配置文件(如 YAML 格式)。
- 加载到
ReCall类。 - 运行推理脚本,观察模型如何动态调用工具。
- 高效模型服务:基于 SGLang 的模型服务支持高并发推理,适合生产环境。用户可通过 API 调用模型,处理实时任务。
注意事项
- 确保硬件支持(如 GPU 用于
faiss-gpu和flash-attn)。 - 定期检查 GitHub 仓库更新,获取最新功能和修复。
- 训练和推理需要较大内存和存储空间,建议提前准备。
应用场景
- 多跳问答系统开发
ReCall 可用于开发需要多步推理的问答系统。例如,回答“某历史人物的出生地所属国家在 19 世纪的首都是哪里?”时,模型可通过 Wikipedia 搜索工具分步推理,获取准确答案。适合教育、知识问答平台开发。 - 自动化任务处理
ReCall 能结合多种工具(如计算器、数据库查询)自动化处理复杂任务。例如,企业可使用 ReCall 开发智能体,自动分析销售数据并生成报告。 - AI 研究与实验
研究人员可利用 ReCall 的合成数据集和强化学习框架,探索大模型在工具调用和复杂推理任务中的表现,适合学术研究和算法开发。
QA
- ReCall 支持哪些工具?
ReCall 支持用户自定义任意工具,如搜索、计算器、数据库查询等。用户可通过配置文件添加新工具,具体参考 GitHub 示例。 - 如何开始使用 ReCall?
克隆 GitHub 仓库,安装依赖,下载预处理数据或生成自定义数据,然后运行示例脚本即可。详细步骤见“使用帮助”。 - ReCall 与 ReSearch 有什么区别?
ReCall 是 ReSearch 的升级版,支持更多工具和更复杂的推理任务,可作为 ReSearch 的直接替代。 - 需要多大存储空间?
训练和评估需要较大存储空间,例如 FlashRAG 评估数据可能占用数十 GB,建议提前检查硬件容量。
































