


LMCache 是一个开源的键值(KV)缓存优化工具,专为提升大语言模型(LLM)推理效率设计。它通过缓存和复用模型的中间计算结果(键值缓存),显著降低推理时间和GPU资源消耗,特别适合长上下文场景。LMCache 与 vLLM 等推理引擎无缝集成,支持 GPU、CPU 和磁盘存储,适用于多轮问答、检索增强生成(RAG)等场景。项目由社区驱动,采用 Apache 2.0 许可证,广泛应用于企业级 AI 推理优化。
功能列表
- 键值缓存复用:缓存 LLM 的键值对,支持非前缀文本复用,减少重复计算。
- 多存储后端支持:支持 GPU、CPU DRAM、磁盘和 Redis 等存储,灵活应对内存限制。
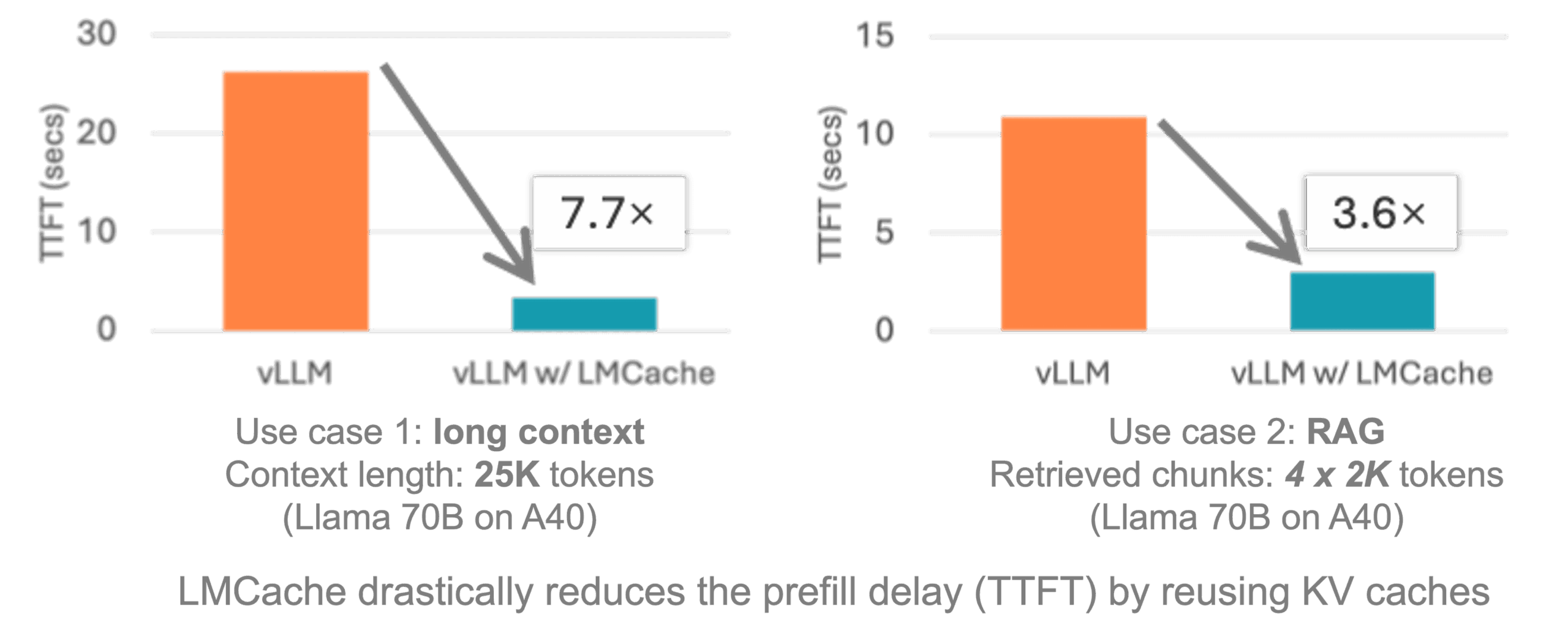
- 与 vLLM 集成:无缝接入 vLLM,提供 3-10 倍的推理延迟优化。
- 分布式缓存:支持跨多 GPU 或容器化环境共享缓存,适合大规模部署。
- 多模态支持:缓存图像和文本的键值对,优化多模态模型推理。
- 工作负载生成:提供测试工具生成多轮问答、RAG 等工作负载,验证性能。
- 开源社区支持:提供文档、示例和社区会议,便于用户贡献和交流。
使用帮助
安装流程
LMCache 的安装简单,支持 Linux 平台和 NVIDIA GPU 环境。以下是详细的安装步骤,基于官方文档和社区推荐的方式。
- 准备环境:
- 确保系统为 Linux,Python 版本为 3.10 或更高,CUDA 版本为 12.1 或以上。
- 安装 Conda(推荐使用 Miniconda)以创建虚拟环境:
conda create -n lmcache python=3.10 conda activate lmcache
- 克隆仓库:
- 使用 Git 克隆 LMCache 仓库到本地:
git clone https://github.com/LMCache/LMCache.git cd LMCache
- 使用 Git 克隆 LMCache 仓库到本地:
- 安装 LMCache:
- 通过 PyPI 安装最新稳定版:
pip install lmcache - 或者安装最新预发布版(可能包含实验性功能):
pip install --index-url https://pypi.org/simple --extra-index-url https://test.pypi.org/simple lmcache==0.2.2.dev57 - 若需从源码安装:
pip install -e .
- 通过 PyPI 安装最新稳定版:
- 安装 vLLM:
- LMCache 需与 vLLM 配合使用,安装最新版 vLLM:
pip install vllm
- LMCache 需与 vLLM 配合使用,安装最新版 vLLM:
- 验证安装:
- 检查 LMCache 是否正确安装:
python import lmcache from importlib.metadata import version print(version("lmcache"))输出应为安装的版本号,如
0.2.2.dev57。
- 检查 LMCache 是否正确安装:
- 可选:Docker 部署:
- LMCache 提供预构建的 Docker 镜像,集成 vLLM:
docker pull lmcache/lmcache:latest - 运行 Docker 容器并根据文档配置 vLLM 和 LMCache。
- LMCache 提供预构建的 Docker 镜像,集成 vLLM:
使用主要功能
LMCache 的核心功能是优化键值缓存,以加速 LLM 推理。以下是主要功能的详细操作指南。
1. 键值缓存复用
LMCache 通过存储模型的键值缓存(KV Cache),避免重复计算相同的文本或上下文。用户可以在 vLLM 中启用 LMCache:
- 配置环境变量:
export LMCACHE_USE_EXPERIMENTAL=True export LMCACHE_CHUNK_SIZE=256 export LMCACHE_LOCAL_CPU=True export LMCACHE_MAX_LOCAL_CPU_SIZE=5.0这些变量设置 LMCache 使用实验功能、每块 256 个 token、启用 CPU 后端,并限制 CPU 内存为 5GB。
- 运行 vLLM 实例:
启动 vLLM 时,LMCache 自动加载并缓存键值对。示例代码:from vllm import LLM from lmcache.integration.vllm.utils import ENGINE_NAME from vllm.config import KVTransferConfig ktc = KVTransferConfig(kv_connector="LMCacheConnector", kv_role="kv_both") llm = LLM(model="meta-llama/Meta-Llama-3.1-8B-Instruct", kv_transfer_config=ktc)
2. 多存储后端
LMCache 支持将键值缓存存储在 GPU、CPU、磁盘或 Redis 上。用户可根据硬件资源选择存储方式:
- 本地磁盘存储:
python3 -m lmcache_server.server localhost 9000 /path/to/disk这将启动 LMCache 服务器,存储缓存到指定磁盘路径。
- Redis 存储:
配置 Redis 后端需设置用户名和密码,参考文档:export LMCACHE_REDIS_USERNAME=user export LMCACHE_REDIS_PASSWORD=pass
3. 分布式缓存
在多 GPU 或容器化环境中,LMCache 支持跨节点共享缓存:
- 启动 LMCache 服务器:
python3 -m lmcache_server.server localhost 9000 cpu - 配置 vLLM 实例连接服务器,参考
disagg_vllm_launcher.sh示例。
4. 多模态支持
LMCache 支持多模态模型,通过哈希图像 token(mm_hashes)缓存键值对,优化视觉 LLM 推理:
- 在 vLLM 中启用多模态支持,参考官方示例
LMCache-Examples仓库。
5. 测试工具
LMCache 提供测试工具,生成工作负载以验证性能:
- 克隆测试仓库:
git clone https://github.com/LMCache/lmcache-tests.git cd lmcache-tests bash prepare_environment.sh - 运行测试用例:
python3 main.py tests/tests.py -f test_lmcache_local_cpu -o outputs/输出结果保存在
outputs/test_lmcache_local_cpu.csv。
操作注意事项
- 环境检查:确保 CUDA 和 Python 版本兼容,推荐使用 Conda 管理环境。
- 日志监控:检查
prefiller.log、decoder.log和proxy.log以调试问题。 - 社区支持:加入 LMCache Slack 或参加 bi-weekly 社区会议获取帮助,会议时间为每周二上午 9 点(PT)。
应用场景
- 多轮问答系统
LMCache 缓存上下文中的键值对,加速多轮对话场景。用户在聊天机器人中连续提问时,LMCache 复用之前的计算结果,减少延迟。 - 检索增强生成(RAG)
在 RAG 应用中,LMCache 缓存文档的键值对,快速响应相似查询,适合智能文档搜索或企业知识库。 - 多模态模型推理
对于视觉-语言模型,LMCache 缓存图像和文本的键值对,降低 GPU 内存占用,提升响应速度。 - 大规模分布式部署
在多 GPU 或容器化环境中,LMCache 的分布式缓存功能支持跨节点共享,优化企业级 AI 推理。
QA
- LMCache 支持哪些平台?
目前支持 Linux 和 NVIDIA GPU 环境,Windows 可通过 WSL 使用。 - 如何与 vLLM 集成?
通过pip install lmcache vllm,并在 vLLM 配置中启用 LMCacheConnector,参考官方示例代码。 - 是否支持非前缀缓存?
支持,LMCache 使用部分重计算技术,缓存 RAG 工作负载中的非前缀文本。 - 如何调试性能问题?
检查日志文件并运行测试用例,输出 CSV 文件分析延迟和吞吐量。
























