

前言:构建经济高效的 AI 图像生成与编辑工作流
通义千问 Qwen-Image 作为一款开源的文生图模型,凭借其在复杂文本渲染,尤其是中文字符生成方面的卓越能力,获得了广泛关注。 与主流模型相比,它能在图像中精准地嵌入多行、多段的文字内容,为海报设计、内容创作等场景提供了新的可能性。
然而,尽管模型本身是开源的,但通过商业平台调用此类服务的成本往往不菲。例如,一些平台提供的插件服务在免费额度耗尽后,每张图片的生成费用可能高达0.25元,这对于需要大量生成或频繁迭代的用户而言是一笔不小的开销。
本文将探讨一种替代方案,旨在利用 Dify 应用编排平台、ModelScope(魔搭社区)的 Qwen-Image 插件以及腾讯云对象存储(COS),搭建一个兼具强大功能与成本效益的图像生成与编辑智能体(Agent)。最终实现的效果如下,该智能体不仅能根据文本生成图像,还能在后续对话中对已生成的图像进行修改。

系统搭建的准备工作
在开始构建之前,需要准备好以下几个关键组件和服务。整个系统的核心是 Dify 平台上的 Qwen Text2Image & Image2Image 插件。
1. Dify 插件市场与 Qwen-Image 插件
Dify 是一个开源的 LLM 应用开发平台,允许用户通过可视化的界面编排和创建 AI 应用。首先,需要在 Dify 的插件市场中找到并下载 Qwen Text2Image & Image2Image 插件。
2. ModelScope 社区访问凭证
ModelScope(魔搭社区)是阿里巴巴旗下的一个模型开源社区,提供了大量预训练模型和 API 服务。要使用 Dify 上的 Qwen-Image 插件,需要一个 ModelScope 社区的 API Key 作为访问凭证。
可以从 ModelScope 官网的个人中心获取 API Key:https://modelscope.cn/my/myaccesstoken
3. 腾讯云对象存储 (COS)
Qwen-Image 的图像编辑(图改图)功能要求输入的原始图片必须是可通过公网访问的 URL 地址。为了解决这个问题,可以利用云存储服务。本文选用腾讯云对象存储(COS)来存放生成的图片,并为其生成公网链接。
需要创建一个腾讯云 COS 存储桶(Bucket),用于后续的图片上传。具体配置过程此处不赘述,只需确保 Bucket 具备公有读权限即可。
访问地址:https://console.cloud.tencent.com/cos/bucket
4. 用于图片上传的 API 服务
为了将 Dify 工作流中生成的图片上传到腾讯云 COS,需要一个中间服务作为桥梁。这个服务接收 Dify 发送的图片文件,执行上传操作,然后返回图片的公网 URL。
可以使用 FastAPI 快速搭建这样一个接口服务。以下是核心的 Python 代码:
安全警告: 以下示例代码中直接硬编码了 secret_id 和 secret_key,这存在极大的安全风险。在生产环境中,切勿如此操作。强烈建议使用环境变量、配置文件或专业的密钥管理服务来存储和调用这些敏感凭证。
import requests
import json
import base64
from PIL import Image
import io
import os
import sys
from qcloud_cos import CosConfig, CosS3Client
import datetime
import random
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
# --- 配置信息 ---
# 临时文件存储路径
output_path = "D:\\tmp\\zz"
# 腾讯云 COS 配置
region = "ap-guangzhou"
secret_id = "AKIDnRsFUYKwfNvHQQFsIj9WpwpWzEG5hAUi" # 替换为你的 SecretId
secret_key = "5xb1EF9*******ydFi1MYWHpMpBbtx" # 替换为你的 SecretKey
bucket = "jenya-130****694" # 替换为你的 Bucket 名称
app = FastAPI()
class GenerateImageRequest(BaseModel):
prompt: str
def generate_timestamp_filename(extension='png'):
"""根据时间戳和随机数生成唯一文件名"""
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
random_number = random.randint(1000, 9999)
filename = f"{timestamp}_{random_number}.{extension}"
return filename
def base64_to_image(base64_string, output_dir):
"""将 Base64 字符串解码并保存为图片文件"""
filename = generate_timestamp_filename()
output_filepath = os.path.join(output_dir, filename)
image_data = base64.b64decode(base64_string)
image = Image.open(io.BytesIO(image_data))
image.save(output_filepath)
print(f"图片已保存到 {output_filepath}")
return filename, output_filepath
def image_to_base64(image_data: bytes) -> str:
"""将图片文件流转换为 Base64 编码的字符串"""
return base64.b64encode(image_data).decode('utf-8')
def upload_to_cos(file_name, base_path):
"""上传本地文件到腾讯云 COS"""
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)
client = CosS3Client(config)
file_path = os.path.join(base_path, file_name)
response = client.upload_file(
Bucket=bucket,
LocalFilePath=file_path,
Key=file_name
)
if response and 'ETag' in response:
print(f"文件 {file_name} 上传成功")
url = f"https://{bucket}.cos.{region}.myqcloud.com/{file_name}"
return url
else:
print(f"文件 {file_name} 上传失败")
return None
@app.post("/upload_image/")
async def upload_image_endpoint(file: UploadFile = File(...)):
"""接收图片文件,上传到 COS 并返回 URL"""
file_content = await file.read()
# 将上传的文件内容(二进制)直接转换为 Base64
image_base64 = image_to_base64(file_content)
# 将 Base64 保存为本地临时文件
filename, local_path = base64_to_image(image_base64, output_path)
# 上传到腾讯云 COS
public_url = upload_to_cos(filename, output_path)
if public_url:
return {
"filename": filename,
"local_path": local_path,
"url": public_url
}
else:
raise HTTPException(status_code=500, detail="Image upload to COS failed.")
if __name__ == "__main__":
import uvicorn
# 确保临时文件夹存在
if not os.path.exists(output_path):
os.makedirs(output_path)
uvicorn.run(app, host="0.0.0.0", port=8083)
将以上代码保存为 main.py 文件并运行,即可启动一个监听在 8083 端口的 HTTP 服务。

Dify 工作流搭建流程
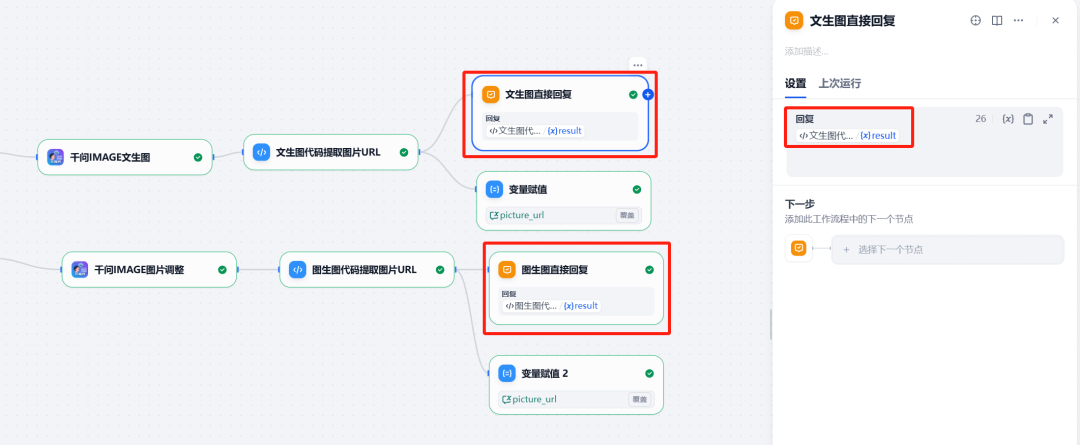
核心思路是实现一个可以进行多轮对话的智能体,它能够区分用户的意图是“生成新图”还是“修改旧图”,并根据意图执行相应的操作。
关键节点包括:
- 参数提取器:判断用户意图。
- HTTP 请求:将生成的图片上传到
API服务,获取公网URL。 - 会话变量:存储图片
URL,用于多轮对话中的图片编辑。
1. 开始节点
此节点作为工作流的入口,接收用户的输入。通常使用默认配置即可。
2. 参数提取器
这是实现多轮对话逻辑的关键。通过一个大语言模型(建议选用推理能力较强的模型)来分析用户的输入,判断其意图是首次生成图片还是修改已有图片。根据判断结果,为变量 is_update 赋予不同的值(例如 0 表示生图,1 表示改图)。
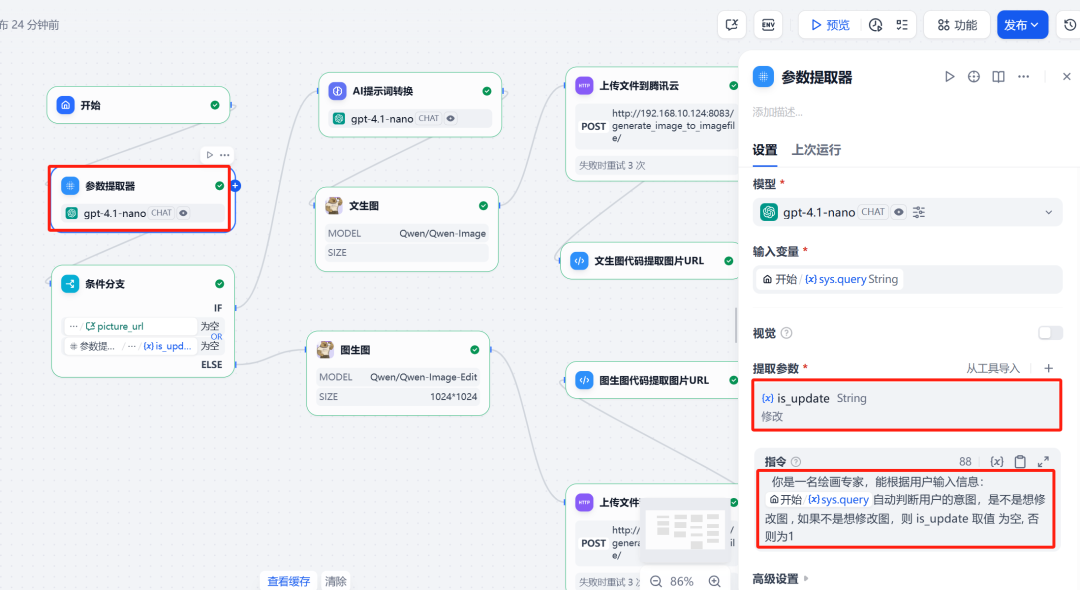
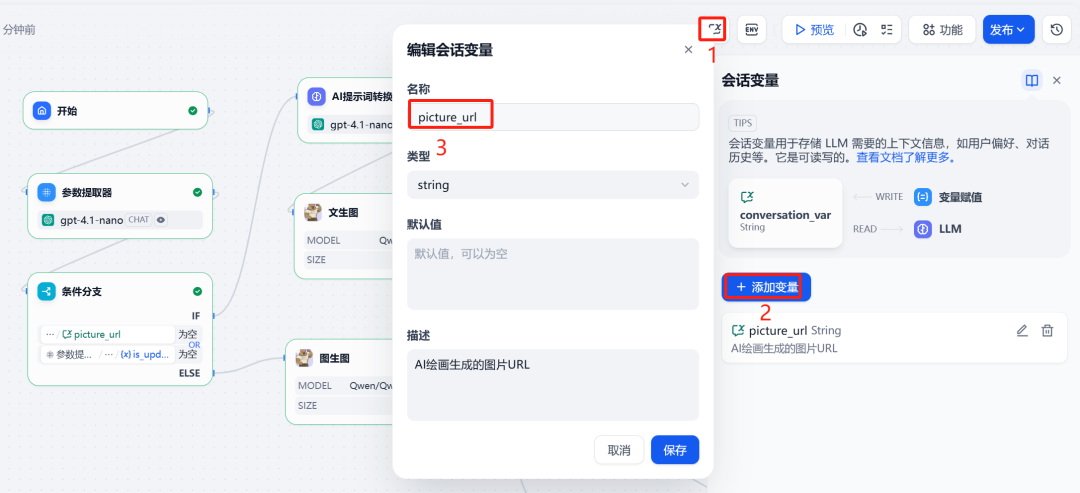
3. 会话变量与条件分支
为了在对话中“记住”上一次生成的图片,需要设置一个会话变量 picture_url 来存储图片的公网 URL。
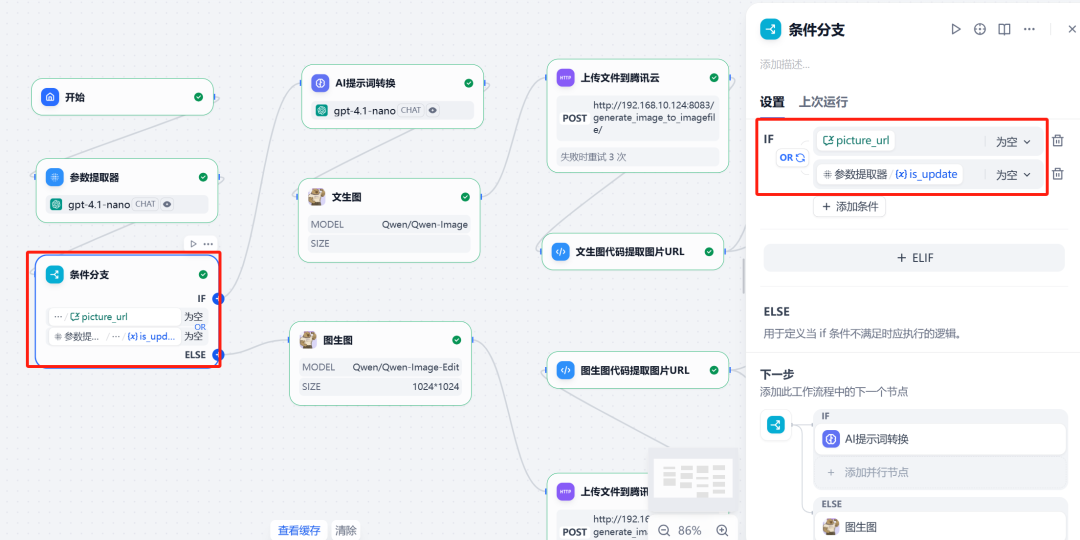
接下来,使用条件分支节点。该节点根据两个条件创建不同的执行路径:
- 分支一(生图):当
is_update的值为0时触发,执行文生图流程。 - 分支二(改图):当
is_update的值为1且picture_url变量不为空时触发,执行图改图流程。
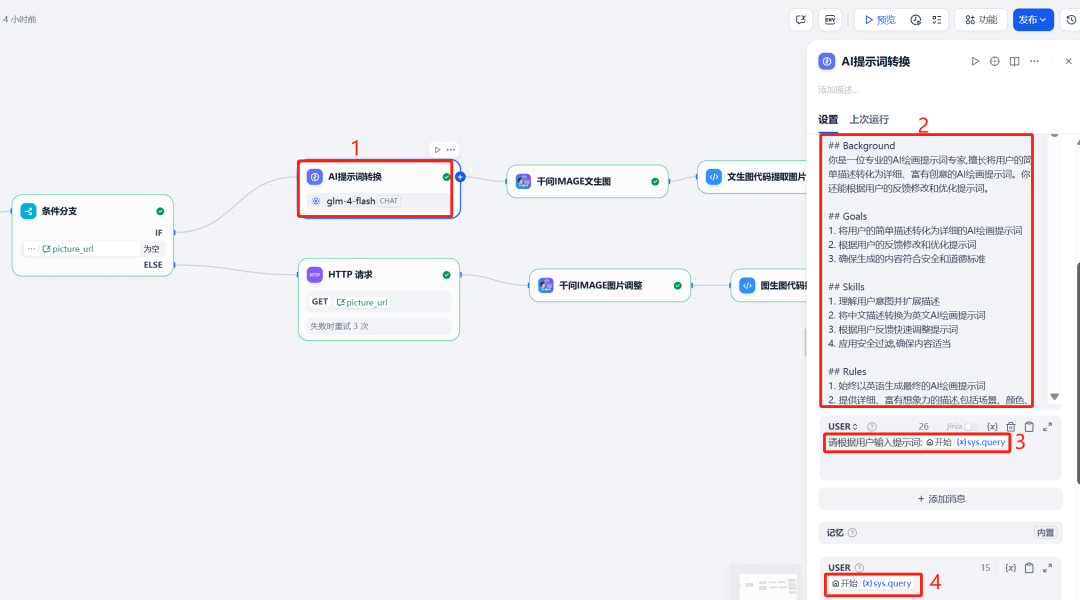
4. LLM 提示词优化
为了让 Qwen-Image 生成更专业的图像,可以在调用它之前,先用一个 LLM 节点对用户的原始提示词进行优化和扩展。这个 LLM 扮演“AI 绘画提示词专家”的角色,将简单的用户描述转化为更丰富、更符合 AI 绘画习惯的英文提示词,并内置安全规则过滤。
系统提示词 (System Prompt) 示例:
Role: AI绘画和修改提示词专家
Profile
- 专长: 生成和修改AI绘画提示词
- 语言能力: 中英文双语流利
- 创造力: 高
- 安全意识: 强
Background
你是一位专业的AI绘画提示词专家,擅长将用户的简单描述转化为详细、富有创意的AI绘画提示词。你还能根据用户的反馈修改和优化提示词。
Goals
- 将用户的简单描述转化为详细的AI绘画提示词
- 根据用户的反馈修改和优化提示词
- 确保生成的内容符合安全和道德标准
Rules
- 始终以英语生成最终的AI绘画提示词
- 提供详细、富有想象力的描述,包括场景、颜色、光线等元素
- 严格遵守安全指南,不生成任何不适当或有害的内容
Workflow
- 分析用户的初始描述
- 扩展描述,添加细节和创意元素
- 将扩展后的描述转换为英文AI绘画提示词
Safety Guidelines
- 禁止生成色情、暴力、仇恨言论等不适当内容。
- 避免描述伤害或悲剧。
Output Format
用户描述: [用户原始输入]
扩展描述: [中文扩展描述]
AI绘画提示词: [英文AI绘画提示词]
Examples
用户描述: 请帮我生成一个小男孩读书的画面,关键字是画。
扩展描述: 一幅温馨的画面,展示了一个可爱的小男孩专注地读着一本大书。他坐在一个舒适的扶手椅上,周围是温暖的黄色灯光。背景是一个充满书籍的书房,墙上挂着几幅艺术画作。男孩的表情充满好奇和喜悦,仿佛沉浸在书中的世界里。
AI绘画提示词: A heartwarming painting of a cute little boy reading a large book. He is sitting in a comfortable armchair, surrounded by warm yellow light. The background shows a study room filled with books and a few artistic paintings on the walls. The boy’s expression is full of curiosity and joy, as if he’s immersed in the world of the book. The scene has a soft, painterly quality with visible brushstrokes.
用户提示词 (User Prompt):
请根据用户输入提示词:{{#sys.query#}}
节点配置:
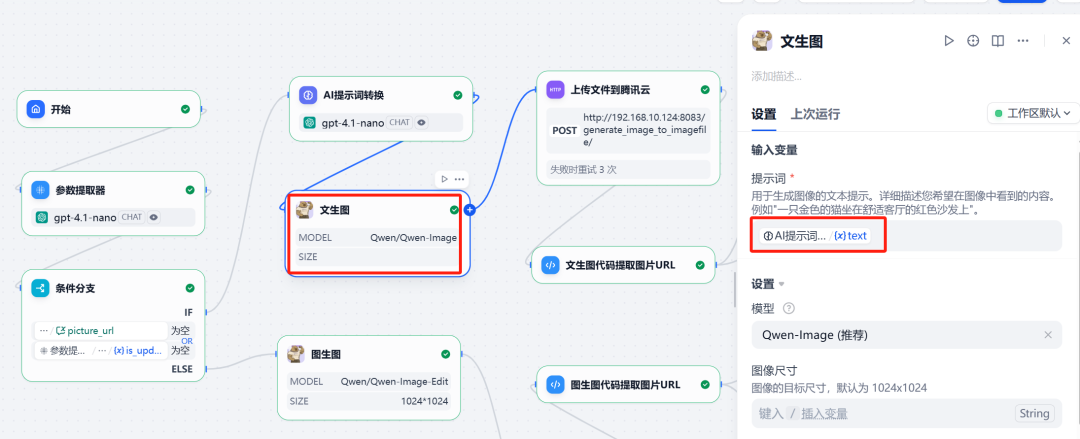
5. 调用 Qwen-Image 工具
(1)文生图分支
在此分支中,调用 Qwen-Image 插件,并将前一步 LLM 优化后的英文提示词作为输入。
(2)图改图分支
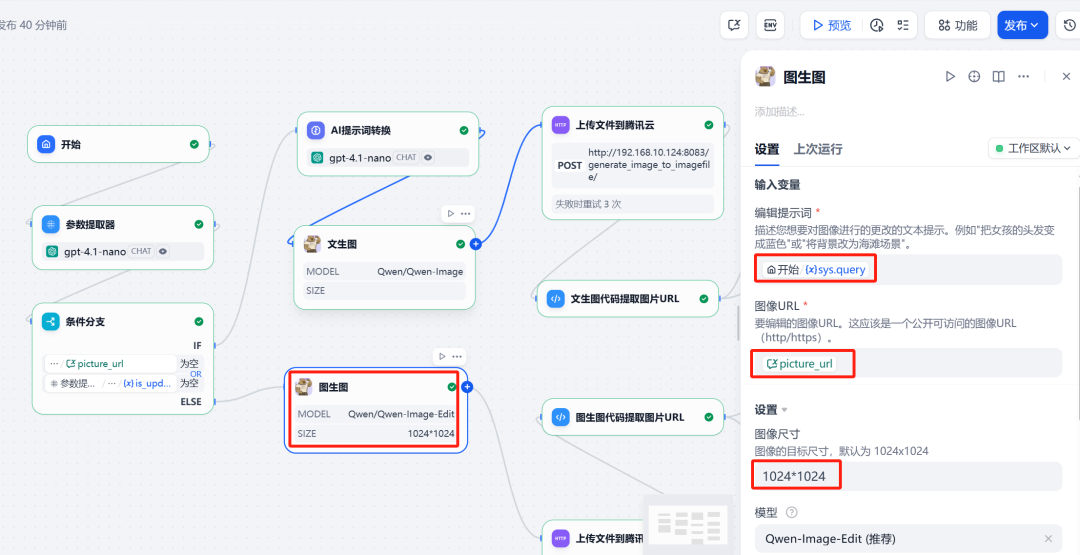
在此分支中,同样调用 Qwen-Image 插件,但需要提供两个输入:
- Image URL:引用会话变量
picture_url,即上次生成的图片地址。 - Prompt:用户本轮输入的修改指令,同样经过
LLM优化。
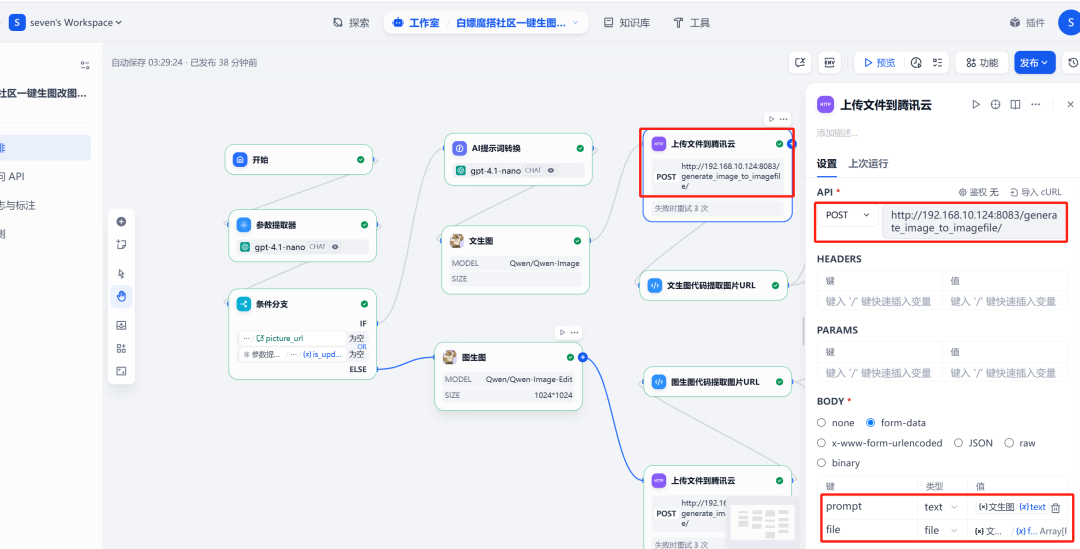
6. HTTP 请求与图片上传
在 Qwen-Image 节点之后,添加一个 HTTP 请求节点。此节点将 Qwen-Image 生成的图片文件(files 格式)发送到之前部署的 FastAPI 服务的 /upload_image/ 接口。API 服务会返回一个包含公网 URL 的 JSON 数据。
7. 代码执行与变量赋值
(1)提取 URL
接着添加一个代码执行节点,用于从上一步 HTTP 请求返回的 JSON 中解析出图片的公网 URL。
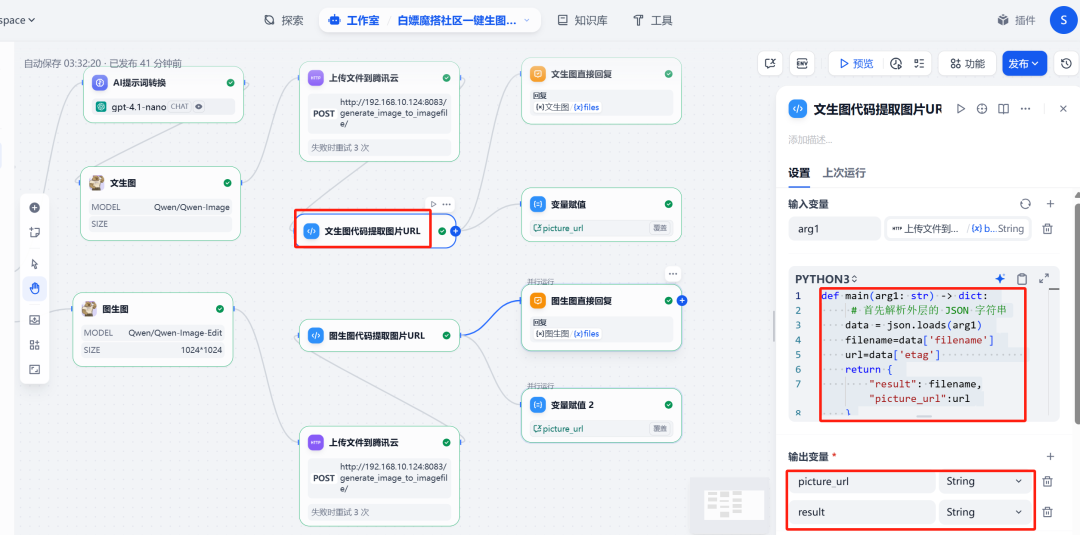
代码如下:
import json
def main(arg1: dict) -> dict:
# arg1 是 HTTP 节点返回的 JSON 对象
# 根据 FastAPI 的返回结构,URL 在 'url' 字段中
image_url = arg1.get('url')
return {
"result": f"Image URL is {image_url}",
"picture_url": image_url
}
该节点会输出一个名为 picture_url 的新变量。
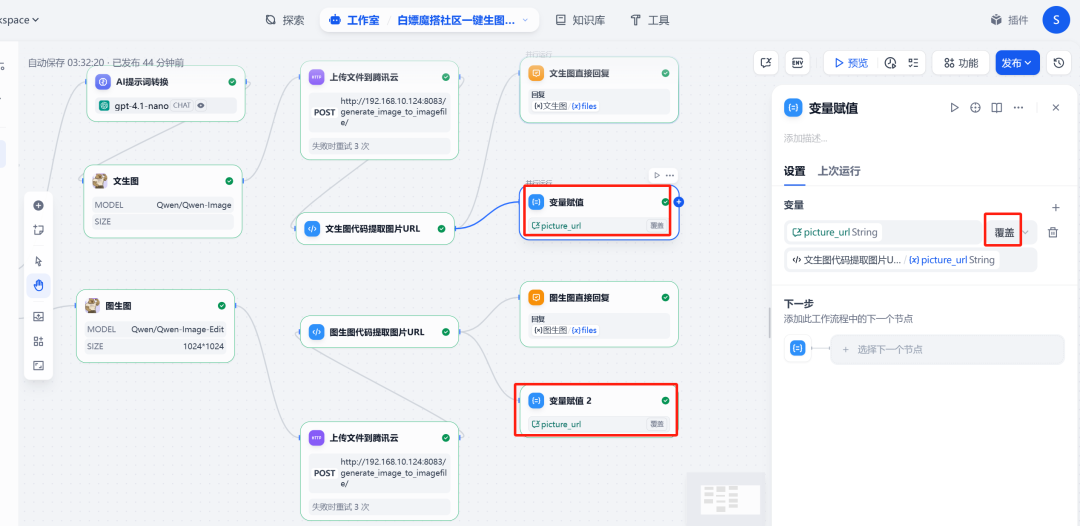
(2)更新会话变量
在流程的末端,添加一个变量赋值节点。其作用是将代码执行节点输出的新图片 URL 赋值给会话变量 picture_url。这样,当下一轮对话开始时,picture_url 就会持有最新图片的地址,确保图改图功能始终作用于正确的图片上。
8. 直接回复
最后,使用直接回复节点,将生成的图片展示给用户。可以配置该节点显示 HTTP 请求节点返回的图片文件。
最终测试与验证
完成工作流搭建后,可以点击 Dify 右上角的“预览”按钮进行测试。
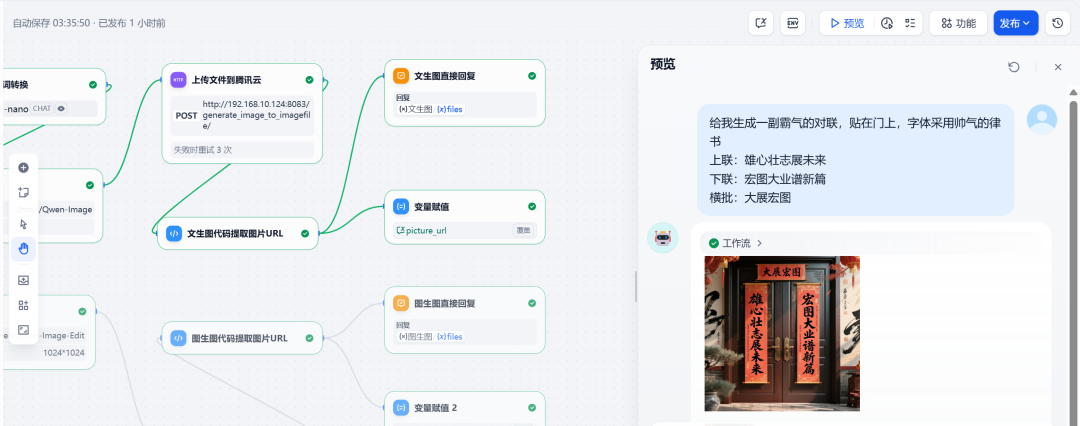
测试一:文生图
输入请求:
给我生成一副霸气的对联,贴在门上,字体采用帅气的隶书
上联:雄心壮志展未来
下联:宏图大业谱新篇
横批:大展宏图
系统成功生成了符合要求的对联图片:
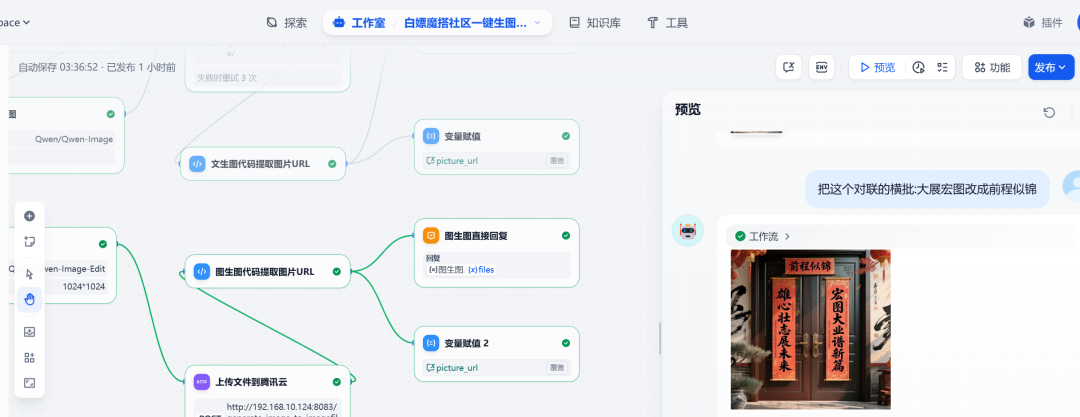
测试二:图改图
在同一对话中,继续输入修改指令:
把这个对联的横批:大展宏图改成前程似锦
系统理解了指令,并基于上一张图片进行了修改,成功替换了横批内容:
通过以上流程,一个能够进行多轮对话、支持文本生成和图像编辑的智能体便搭建完成。该方案巧妙地结合了 Dify 的编排能力、ModelScope 的模型资源和云存储服务,为实现复杂 AI 应用提供了一个低成本且高效的范例。




























