



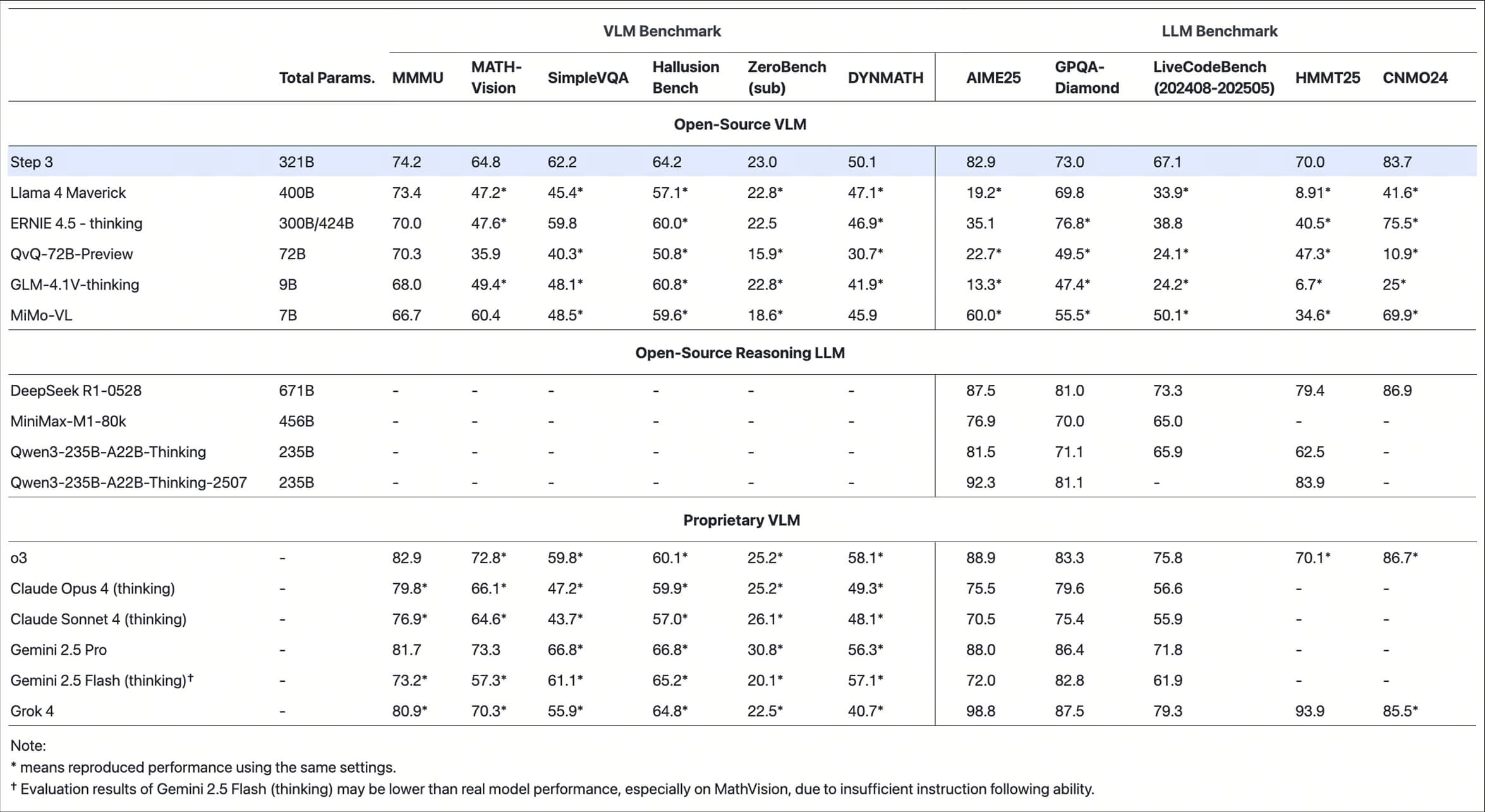
Step3 是由 StepFun 开发的一个开源多模态大模型项目,托管在 GitHub 上,旨在提供高效、经济的文本、图像和语音内容生成能力。项目以 321 亿参数(38 亿活跃参数)的混合专家模型(MoE)为核心,优化了推理速度和性能,适合生产环境使用。Step3 支持 OpenAI 和 Anthropic 兼容的 API 接口,模型权重以 bf16 和 block-fp8 格式存储,方便开发者在多种推理引擎上部署。项目提供详细的部署指南和示例代码,支持 vLLM 和 SGLang 等推理框架。StepFun 致力于通过开源推动人工智能发展,Step3 的代码和模型权重均采用 Apache 2.0 许可,开发者可以自由使用和定制。
功能列表
- 支持多模态内容生成:处理文本、图像和语音输入,生成高质量的输出。
- 高效推理优化:基于混合专家模型(MoE),提供快速推理速度,适合实时应用。
- OpenAI/Anthropic 兼容 API:通过
https://platform.stepfun.com/提供标准化的 API 接口。 - 支持 bf16 和 block-fp8 格式:模型权重优化存储,降低硬件需求。
- 提供 vLLM 和 SGLang 部署示例:简化模型在生产环境的部署流程。
- 开源代码和模型权重:开发者可自由下载、修改和使用。
使用帮助
安装与部署
要使用 Step3,开发者需要先从 GitHub 仓库克隆代码并设置开发环境。以下是详细的安装和使用步骤:
- 克隆代码仓库
使用以下命令从 GitHub 获取 Step3 项目代码:git clone https://github.com/stepfun-ai/Step3.git cd Step3这会下载 Step3 的源码到本地。
- 设置 Python 环境
Step3 推荐使用 Python 3.10 及以上版本,并需要安装 PyTorch(建议版本 ≥2.1.0)和 Transformers 库(建议版本 4.54.0)。可以按照以下步骤配置环境:conda create -n step3 python=3.10 conda activate step3 pip install torch>=2.1.0 pip install transformers==4.54.0确保安装完成后检查环境是否正确配置。
- 下载模型权重
Step3 的模型权重托管在 Hugging Face 平台,分为 bf16 和 block-fp8 格式。开发者可以从以下地址下载:- Hugging Face 模型地址:
https://huggingface.co/stepfun-ai/step3 - 下载示例:
git clone https://huggingface.co/stepfun-ai/step3
下载后,模型权重目录结构应包含必要的模型文件,如
step3-fp8或step3。 - Hugging Face 模型地址:
- 部署模型
Step3 支持 vLLM 和 SGLang 推理引擎,推荐使用多 GPU 环境(如 4 个 A800/H800 GPU,每张 80GB 显存)以获得最佳性能。以下是以 vLLM 为例的部署步骤:- 启动 vLLM 服务:
python -m vllm.entrypoints.api_server --model stepfun-ai/step3 --port 8000 - 运行后,API 服务将在本地
http://localhost:8000提供,开发者可以通过 API 调用模型。 - 示例 API 请求:
import requests url = "http://localhost:8000/v1/completions" data = { "model": "stepfun-ai/step3", "prompt": "生成一张秋天森林的图片描述", "max_tokens": 512 } response = requests.post(url, json=data) print(response.json())
- 启动 vLLM 服务:
- 使用 Transformers 库推理
如果不使用 vLLM,可以通过 Transformers 库直接加载模型进行推理。以下是示例代码:from transformers import AutoProcessor, AutoModelForCausalLM # 定义模型路径 model_path = "stepfun-ai/step3" processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", torch_dtype="auto", trust_remote_code=True) # 输入示例(图像 + 文本) messages = [ { "role": "user", "content": [ {"type": "image", "image": "https://example.com/image.jpg"}, {"type": "text", "text": "描述这张图片的内容"} ] } ] # 预处理输入 inputs = processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device) # 生成输出 generate_ids = model.generate(**inputs, max_new_tokens=32768, do_sample=False) decoded = processor.decode(generate_ids[0, inputs["input_ids"].shape[-1]:], skip_special_tokens=True) print(decoded)这段代码展示了如何加载模型、处理多模态输入并生成输出。
- 特色功能操作
- 多模态输入:Step3 支持文本、图像和语音输入。开发者可以通过 API 或 Transformers 库传入多模态数据。例如,上传一张图片并附带文本提示,模型可以生成与图片相关的描述或回答问题。
- 高效推理:Step3 的 MoE 架构优化了推理速度,适合实时应用。开发者可以通过调整
max_new_tokens参数控制输出长度,推荐值在 512 到 32768 之间。 - 模型定制:开发者可以基于 Step3 的开源代码进行微调,调整模型以适应特定任务,如生成特定风格的文本或图像。
- 调试与支持
如果部署或使用中遇到问题,可以通过 GitHub 提交 issue 或联系官方邮箱contact@stepfun.com获取支持。StepFun 社区还提供 Discord 频道(https://discord.gg/92ye5tjg7K)供开发者交流。
应用场景
- 内容创作
Step3 可用于生成文章、图片描述或短视频脚本。创作者可以输入文本提示或图像,快速生成高质量内容,适合博客、社交媒体或广告制作。 - 智能客服
Step3 的多模态能力支持语音和文本交互,可用于构建智能客服系统。企业可以通过 API 集成 Step3,处理客户咨询并生成自然语言回复。 - 教育辅助
教师和学生可以使用 Step3 生成教学材料或解答问题。例如,上传一张科学实验图片,模型可以生成详细的实验步骤说明。 - 多媒体处理
Step3 适合处理多模态数据,如分析视频帧并生成字幕,或根据音频生成文本摘要,适用于视频编辑和内容分析。
QA
- Step3 支持哪些推理引擎?
Step3 推荐使用 vLLM 和 SGLang 进行推理,支持 bf16 和 block-fp8 格式的模型权重,适合多 GPU 环境。 - 如何获取模型权重?
模型权重可在 Hugging Face 平台下载,地址为https://huggingface.co/stepfun-ai/step3。克隆仓库后即可使用。 - Step3 的硬件要求是什么?
推荐使用 4 张 80GB 显存的 A800/H800 GPU。单 GPU 推理也可以,但速度较慢。 - 是否支持微调模型?
是的,Step3 的开源代码和模型权重允许开发者进行微调,适合定制化任务。





























