

在构建检索增强生成(RAG)系统时,开发者常常会遇到以下令人困惑的场景:
- 跨页表格的表头被遗留在上一页,导致数据失去关联。
- 模型面对模糊的扫描件,自信地给出完全错误的内容。
- 数学公式中的求和符号“Σ”被错误地识别为字母“E”。
- 文档中的水印或脚注被当作正文内容提取,干扰了信息的准确性。
当系统无法给出正确答案时,将问题直接归咎于大语言模型(LLM)或许为时过早。在多数情况下,问题的根源在于文档解析这个初始环节的失败。
设想一个医药领域的应用场景。一份记录药物不良反应的 PDF 文档,通常采用双栏排版,并在页面之间存在浮动的文本框。若使用一个声称文字提取准确率高达 99% 的开源工具进行解析,可能会得到如下碎片化的结果:
第一页末尾:...注意事项(不完整)
第二页开头:特殊人群用药...(无上下文)
在 RAG 系统进行索引时,这两个缺乏语义关联的文本片段被切分到不同的区块(Chunk)中。当用户查询“药物 X 在肝功能不全患者中的使用禁忌”时,系统可能只检索到包含“禁忌”关键词的段落。然而,由于该段落丢失了“特殊人群用OCK”这一关键的上下文标题,导致模型无法提供完整、准确的答案。
这充分说明,文档解析的质量直接决定了 RAG 系统性能的上限。
文档解析为何如此复杂?
文档解析并非单一的算法工具,而是一套复杂的解决方案。它的复杂性来源于以下多个维度的挑战组合:
- 文档格式:PDF、Word、Excel、PPT、Markdown 等格式的处理方式各不相同。
- 业务领域:学术论文、商业报告、财务报表等不同文档具备独特的版面风格。
- 语种:不同语言的识别需要依赖相应的语料库进行模型训练。
- 文档元素:段落、标题、表格、公式、角标等元素的精确还原,是帮助
LLM理解文章层次结构的关键。 - 页面布局:单栏、双栏、多栏混合等布局直接影响阅读顺序的正确还原。
- 图像内容:文本
OCR、手写体识别、图像分辨率优化等问题,在图文混排的场景中尤为突出。 - 表格结构:表格中的合并单元格、跨页、嵌套等复杂结构,使其解析既不同于文本,也不同于图像。
- 附加能力:智能切分(Chunking)虽然不是解析的本职工作,但高质量的切分,特别是对超大表格的处理,能显著提升问答效果。
没有任何一款单一工具能在上述所有维度上都表现出色。因此,不加思考地选用开源工具,往往会导致顾此失彼,难以满足高质量的应用需求。
如何科学评估文档解析工具?
既然不存在完美的通用工具,那么如何评估特定场景下的最优选择?上海人工智能实验室的一项研究成果为此提供了参考。这项被计算机视觉顶级会议 CVPR 2024 接收的研究,推出了一个专门用于评估 PDF 文档解析能力的基准——OmniDocBench。
OmniDocBench 从 20 万份 PDF 文档中提取视觉特征,通过聚类分析筛选出 6000 个具有显著差异化的页面,并最终对其中的 981 个页面进行了精细化标注。其标注维度非常丰富,覆盖了布局边界框、布局属性、阅读顺序和层级关系等,尤其对跨页内容的关联性标注非常友好。
在评估指标上,OmniDocBench 针对文本、表格、公式和阅读顺序等不同维度,分别采用了归一化编辑距离(NED)、基于树编辑距离的相似度(TEDS)和 BLEU 等多种算法,以确保评估的全面性和公正性。
各维度下的领先者是谁?
OmniDocBench 的评估报告揭示了一个有趣的趋势。

(来源:https://arxiv.org/abs/2402.07626)
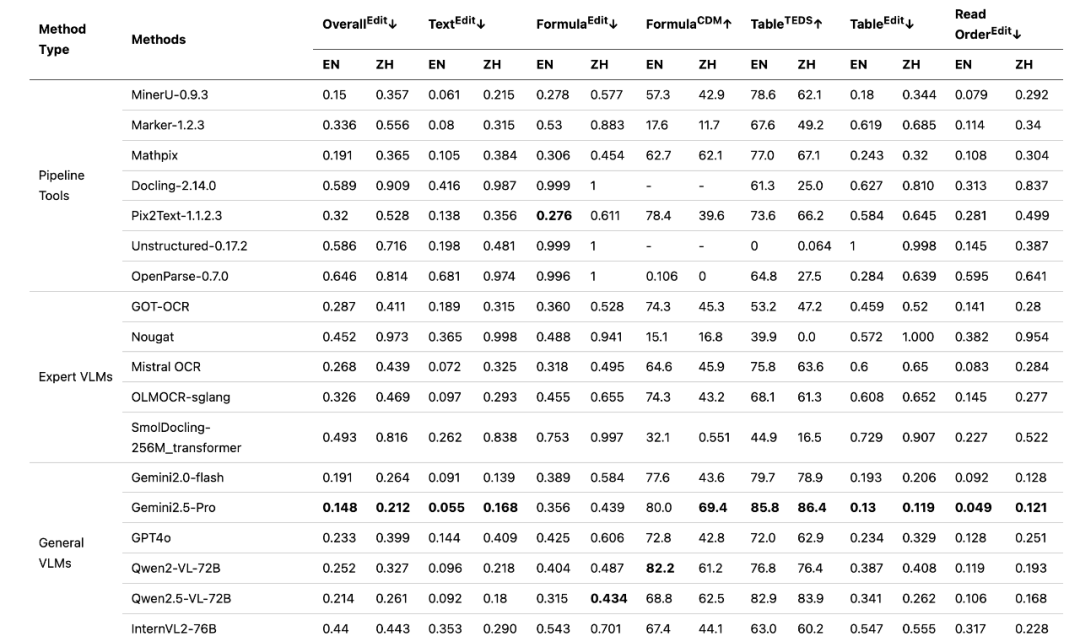
(来源:https://github.com/opendatalab/OmniDocBench/blob/main/README_zh-CN.md)
在项目早期的论文图中,各类传统文档解析工具在不同维度上竞争激烈,各有千秋。然而,当通用视觉大模型(如 Gemini 1.5 Pro)被纳入评测后,其强大的综合能力使其在各项指标上都取得了领先地位。
这种优势源于 Gemini 等原生多模态大模型能够端到端地处理图像和文本信息,从而更好地理解文档的整体布局和语义。但这种强大的能力也伴随着高昂的成本。
以 Gemini 1.5 Pro 为例,尽管它能准确识别潦草的手写体,但在处理一个包含多个合并单元格和角标的复杂表格时,仍然出现了明显的解析错误。
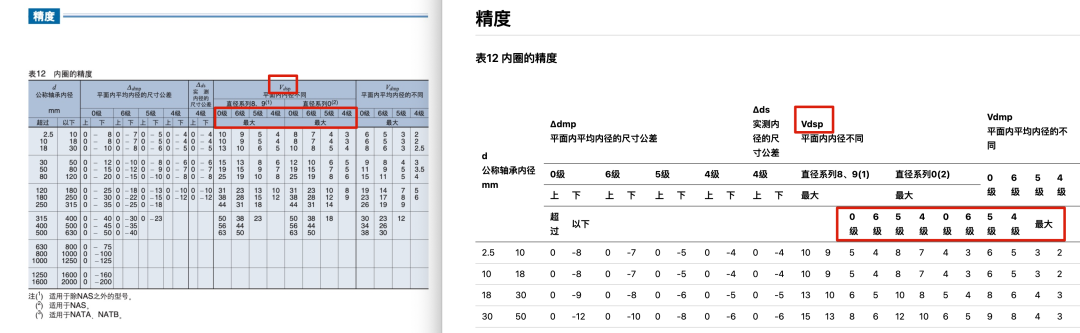
(使用 Gemini 1.5 Pro 解析复杂表格时的出错示例)
更关键的是成本问题。仅仅解析这一页 PDF,就花费了约 1.2 元人民币。费用的主要来源是模型输出的 Token 数量,这对于需要大规模处理文档的企业而言,是一笔巨大的开销。
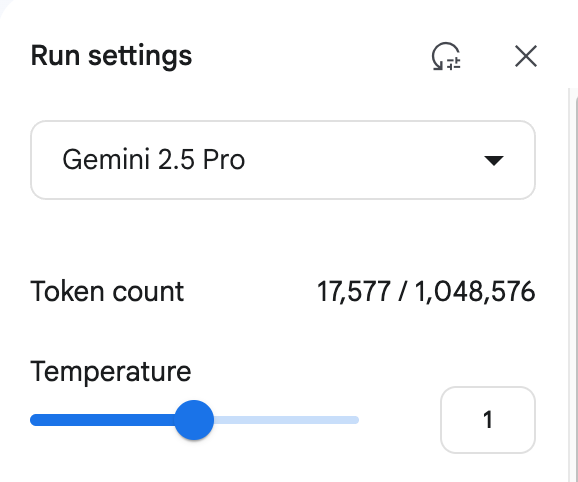
(使用 Gemini 1.5 Pro 解析文档的成本消耗示例)
因此,Gemini 并非适用于所有场景的万能解药。在 Gemini 之外,业界还有 unstructured.io、Marker 和 PyMuPDF 等众多优秀的开源或商业解决方案,它们在特定任务和成本控制上可能更具优势。正确的选择始于对应用场景的清晰定义,需要在性能、成本和特定需求之间找到平衡。
实用建议
在构建或优化 RAG 系统时,开发者可以参考以下步骤来攻克文档解析这一难题:
- 诊断文档库:审查你的文档,识别出最棘手的合同、报告或扫描件,明确其中的主要挑战是来自于复杂表格、数学公式还是特殊的页面布局。
- 针对性验证:对照
OmniDocBench或其他评测报告,选择一到两款在特定维度上表现出色的工具进行针对性验证,找到最适合自身业务需求的解决方案。 - 持续关注前沿:文档解析技术仍在快速发展,持续关注
OmniDocBench这类基准研究和新兴的解析工具,能帮助你不断优化系统性能。
相关研究
OmniDocBench论文:https://arxiv.org/abs/2402.07626






































