



O RAGLight é uma biblioteca Python leve e modular projetada para possibilitar a Geração Aumentada de Recuperação (RAG). Com suporte para vários modelos de linguagem, modelos incorporados e armazenamentos de vetores, o RAGLight é ideal para que os desenvolvedores criem rapidamente aplicativos de IA com reconhecimento de contexto. Projetado com simplicidade e flexibilidade em mente, o RAGLight pode integrar facilmente dados de pastas locais ou repositórios do GitHub para gerar respostas precisas. Ollama ou LMStudio, suporta implementações localizadas e é adequado para projetos sensíveis à privacidade e aos custos.
Lista de funções
- Há suporte para várias fontes de dados: as bases de conhecimento podem ser importadas de pastas locais (por exemplo, PDF, arquivos de texto) ou de repositórios do GitHub.
- modularização RAG Pipeline: combina a recuperação de documentos e a geração de idiomas com suporte para os modos RAG padrão, RAG agêntico e RAT (Retrieval Augmented Thinking).
- Integração flexível de modelos: suporta modelos Ollama e LMStudio para linguagens grandes, como
llama3。 - Armazenamento eficiente de vetores: gere vetores de documentos usando os modelos de incorporação Chroma ou HuggingFace para dar suporte a pesquisas rápidas de similaridade.
- Configuração personalizada: permite que o usuário ajuste o modelo de incorporação, os caminhos de armazenamento de vetores e os parâmetros de recuperação (por exemplo
k(Valor). - Automatize o processamento de documentos: extraia e indexe automaticamente o conteúdo de documentos de fontes especificadas, simplificando a construção da base de conhecimento.
Usando a Ajuda
Processo de instalação
A instalação e o uso do RAGLight requerem um ambiente Python e um Ollama ou LMStudio em execução:
- Instalação do Python e das dependências
Certifique-se de que o Python 3.8 ou posterior esteja instalado em seu sistema. Use o seguinte comando para instalar o RAGLight:pip install raglightSe você usar modelos incorporados do HuggingFace, precisará instalar dependências adicionais:
pip install sentence-transformers - Instalação e execução do Ollama ou do LMStudio
- Faça download e instale o Ollama (https://ollama.ai) ou o LMStudio.
- Puxando modelos em Ollama, por exemplo:
ollama pull llama3 - Certifique-se de que o modelo esteja carregado e em execução no Ollama ou no LMStudio.
- Ambiente de configuração
Crie uma pasta de projeto para preparar os dados da base de conhecimento (por exemplo, pasta PDF ou URL do repositório do GitHub). Certifique-se de que você tenha uma boa conexão com a Internet para acessar o GitHub ou o HuggingFace.
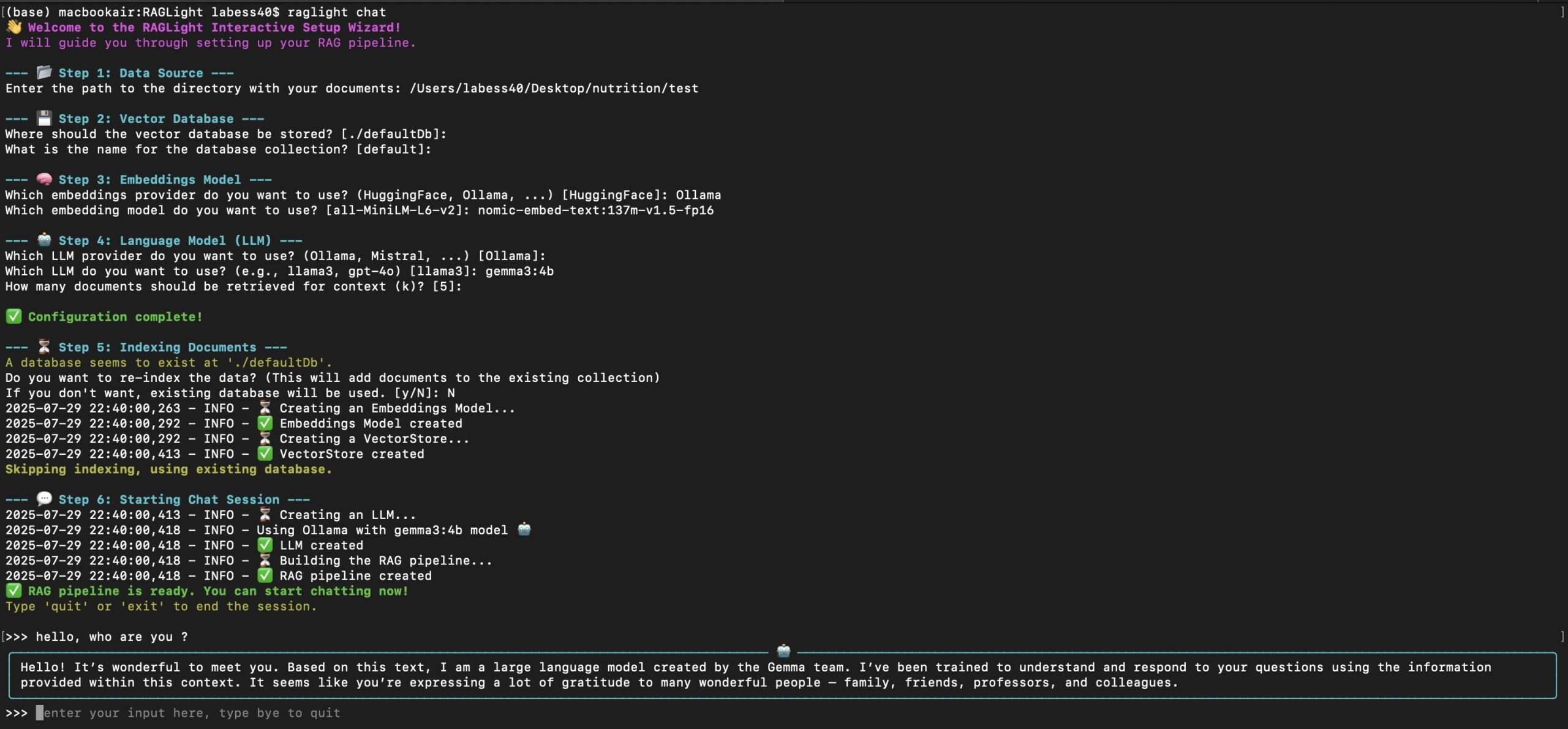
Criação de um pipeline RAG simples com o RAGLight
O RAGLight fornece uma API limpa para criar pipelines RAG. Abaixo está um exemplo básico para criar uma base de conhecimento e gerar respostas a partir de pastas locais e repositórios do GitHub:
from raglight.rag.simple_rag_api import RAGPipeline
from raglight.models.data_source_model import FolderSource, GitHubSource
from raglight.config.settings import Settings
Settings.setup_logging()
# 定义知识库来源
knowledge_base = [
FolderSource(path="/path/to/your/folder/knowledge_base"),
GitHubSource(url="https://github.com/Bessouat40/RAGLight")
]
# 初始化 RAG 管道
pipeline = RAGPipeline(
knowledge_base=knowledge_base,
model_name="llama3",
provider=Settings.OLLAMA,
k=5
)
# 构建管道(处理文档并创建向量存储)
pipeline.build()
# 生成回答
response = pipeline.generate("如何使用 RAGLight 创建一个简单的 RAG 管道?")
print(response)
Operação da função em destaque
- Suporte a várias fontes de dados
O RAGLight permite que os usuários importem dados de pastas locais ou repositórios do GitHub.- Local Folder (Pasta local): Coloque os arquivos PDF ou de texto em uma pasta especificada, por exemplo
/path/to/knowledge_base。 - Repositórios do GitHub: forneça a URL do repositório (por exemplo
https://github.com/Bessouat40/RAGLight), o RAGLight extrai automaticamente os documentos do repositório.
Exemplo de configuração:
knowledge_base = [ FolderSource(path="/data/knowledge_base"), GitHubSource(url="https://github.com/Bessouat40/RAGLight") ] - Local Folder (Pasta local): Coloque os arquivos PDF ou de texto em uma pasta especificada, por exemplo
- Tubos RAG padrão
O pipeline padrão do RAG combina a recuperação e a geração de documentos. Depois que um usuário insere uma consulta, o RAGLight converte a consulta em um vetor, recupera fragmentos de documentos relevantes por meio de uma pesquisa de similaridade e insere esses fragmentos no LLM como contexto para gerar uma resposta.
Procedimento operacional:- inicialização
RAGPipelinee especificar a base de conhecimento, os modelos e osk(número de documentos recuperados). - invocações
pipeline.build()Processa documentos e gera armazenamentos de vetores. - fazer uso de
pipeline.generate("查询")Obter respostas.
- inicialização
- Modos RAG e RAT autênticos
- Agentic RAG: através de
AgenticRAGPipelineadicionando funções corporais inteligentes para dar suporte ao raciocínio em várias etapas e ao ajuste dinâmico das estratégias de recuperação.
Exemplo:from raglight.rag.simple_agentic_rag_api import AgenticRAGPipeline from raglight.config.agentic_rag_config import SimpleAgenticRAGConfig config = SimpleAgenticRAGConfig(k=5, max_steps=4) pipeline = AgenticRAGPipeline(knowledge_base=knowledge_base, config=config) pipeline.build() response = pipeline.generate("如何优化 RAGLight 的检索效率?") print(response) - RAT (Retrieval Augmented Thinking, Pensamento Aumentado por Recuperação): através de
RATPipelineRealização, etapas adicionais de reflexão (reflectionparâmetros) para melhorar a lógica e a precisão das respostas.
Exemplo:from raglight.rat.simple_rat_api import RATPipeline pipeline = RATPipeline( knowledge_base=knowledge_base, model_name="llama3", reasoning_model_name="deepseek-r1:1.5b", reflection=2, provider=Settings.OLLAMA ) pipeline.build() response = pipeline.generate("如何简化 RAGLight 的配置?") print(response)
- Agentic RAG: através de
- Armazenamento de vetores personalizados
O RAGLight usa o Chroma como armazenamento de vetores padrão e oferece suporte aos modelos de incorporação HuggingFace (por exemploall-MiniLM-L6-v2). Caminhos de armazenamento e nomes de coleções definidos pelo usuário:from raglight.config.vector_store_config import VectorStoreConfig vector_store_config = VectorStoreConfig( embedding_model="all-MiniLM-L6-v2", provider=Settings.HUGGINGFACE, database=Settings.CHROMA, persist_directory="./defaultDb", collection_name="my_collection" )
Precauções de manuseio
- Certifique-se de que o modelo de tempo de execução do Ollama ou do LMStudio esteja carregado; caso contrário, será relatado um erro.
- O caminho da pasta local deve conter documentos válidos (por exemplo, PDF, TXT) e o repositório do GitHub deve ser acessível publicamente.
- adaptar
kpara controlar o número de documentos recuperados.k=5Normalmente, é uma escolha que equilibra eficiência e precisão. - Se estiver usando o modelo incorporado do HuggingFace, certifique-se de que a API do HuggingFace esteja acessível à rede.
cenário do aplicativo
- pesquisa acadêmica
Os pesquisadores podem importar PDFs de artigos para uma pasta local e usar o RAGLight para pesquisar rapidamente a literatura e gerar resumos ou responder a perguntas. Por exemplo, digite "avanços recentes em um campo" para obter respostas contextualizadas para artigos relevantes. - Base de conhecimento empresarial
As organizações podem importar documentos internos (por exemplo, manuais técnicos, perguntas frequentes) para o RAGLight para criar sistemas inteligentes de perguntas e respostas. Depois que os funcionários inserem as perguntas, o sistema recupera e gera respostas precisas a partir dos documentos. - Ferramentas do desenvolvedor
Os desenvolvedores podem usar a documentação de código dos repositórios do GitHub como uma base de conhecimento para procurar rapidamente o uso da API ou trechos de código. Por exemplo, digite "how to call a function" (como chamar uma função) para obter a documentação. - Auxílios educacionais
Professores ou alunos podem importar livros didáticos ou notas de curso para o RAGLight para gerar respostas direcionadas ou resumos de seu aprendizado. Por exemplo, digite "explicar um conceito" para acessar o conteúdo relevante do livro didático.
QA
- Quais modelos de idiomas são compatíveis com o RAGLight?
O RAGLight é compatível com os modelos fornecidos pela Ollama e pelo LMStudio, comollama3、deepseek-r1:1.5betc. O usuário precisa pré-carregar o modelo no Ollama ou no LMStudio. - Como faço para adicionar uma fonte de dados personalizada?
fazer uso deFolderSourceEspecifique o caminho para uma pasta local ouGitHubSourceEspecifique um URL de repositório público do GitHub. Certifique-se de que o caminho seja válido e que o formato do arquivo seja compatível (por exemplo, PDF, TXT). - Como otimizar a precisão da pesquisa?
crescentekpara recuperar mais documentos ou usar o modo RAT para ativar a reflexão. Selecione um modelo de incorporação de alta qualidade (por exemploall-MiniLM-L6-v2) também melhora a precisão. - Ele oferece suporte à implementação na nuvem?
O RAGLight foi projetado principalmente para implantação local e precisa ser executado com o Ollama ou o LMStudio. Ele não é compatível diretamente com a nuvem, mas pode ser implantado por meio de contêineres (por exemplo, Docker).
























