

Ao criar sistemas Retrieval Augmented Generation (RAG), os desenvolvedores geralmente se deparam com os seguintes cenários confusos:
- Os cabeçalhos das tabelas entre páginas são deixados na página anterior, fazendo com que os dados não sejam relacionados.
- O modelo fornece com confiança erros completos diante de digitalizações borradas.
- O símbolo de soma "Σ" em uma fórmula matemática foi reconhecido incorretamente como a letra "E".
- Marcas d'água ou notas de rodapé em documentos são extraídas como se fossem o conteúdo do corpo, interferindo na precisão das informações.
Quando o sistema não consegue dar a resposta certa, pode ser muito cedo para culpar diretamente o Large Language Model (LLM) pelo problema. Na maioria dos casos, a raiz do problema está na falha da etapa inicial da análise de documentos.
Imagine um cenário de aplicativo no domínio farmacêutico. Um documento PDF que documenta reações adversas a medicamentos geralmente é apresentado em um layout de duas colunas com caixas de texto flutuantes entre as páginas. Se for analisado usando uma ferramenta de código aberto que afirma ter uma precisão de extração de texto de até 99%, os seguintes resultados fragmentados poderão ser obtidos:
第一页末尾:...注意事项(不完整)
第二页开头:特殊人群用药...(无上下文)
在 RAG Quando indexados, esses dois segmentos de texto semanticamente não relacionados são cortados em partes diferentes. Quando um usuário consulta "Contraindicações ao uso do medicamento X em pacientes com insuficiência hepática", o sistema pode recuperar apenas o parágrafo que contém a palavra-chave "contraindicações". Entretanto, como o título contextual principal "OCK para populações especiais" está faltando no parágrafo, o modelo não pode fornecer uma resposta completa e precisa.
Essa é uma boa indicação de que a qualidade da análise de documentos determina diretamente a qualidade do RAG O limite superior do desempenho do sistema.
Por que a análise de documentos é tão complicada?
A análise de documentos não é uma ferramenta algorítmica única, mas um conjunto complexo de soluções. Sua complexidade decorre de uma combinação de desafios nas várias dimensões a seguir:
- formato de arquivoPDF, Word, Excel, PPT, Markdown e outros formatos são tratados de maneiras diferentes.
- NegóciosEstilos de layout exclusivos para diferentes documentos, como trabalhos acadêmicos, relatórios comerciais, demonstrações financeiras e assim por diante.
- tipo de idioma (em uma classificação)O reconhecimento de diferentes idiomas depende do corpus correspondente para o treinamento do modelo.
- elemento de documentaçãoRedução precisa de elementos como parágrafos, cabeçalhos, tabelas, fórmulas, cantos, etc., é uma parte importante para ajudar a
LLMA chave para entender a estrutura hierárquica de uma redação. - layout da páginaLayouts como coluna única, duas colunas e multicoluna mista têm um impacto direto na restauração correta da ordem de leitura.
- Conteúdo da imagem: Texto
OCRO reconhecimento de escrita à mão e a otimização da resolução da imagem são particularmente problemáticos em cenários de texto misto. - estrutura da tabelaTabela: A estrutura complexa de células mescladas, páginas cruzadas, aninhamento etc. nas tabelas torna sua análise diferente da de textos e imagens.
- capacidade adicionalEmbora a fragmentação inteligente não seja uma parte natural da análise, a fragmentação de alta qualidade, especialmente para tabelas muito grandes, pode melhorar significativamente os resultados de Q&A.
Nenhuma ferramenta isolada pode se destacar em todas as dimensões acima. Portanto, a escolha de uma ferramenta de código aberto sem pensar nisso geralmente faz com que se perca de vista uma ou outra e dificulta o atendimento às necessidades de um aplicativo de alta qualidade.
Como avaliar cientificamente as ferramentas de análise de documentos?
Como não existe uma ferramenta perfeita para uso geral, como avaliar a escolha ideal para um determinado cenário? Um resultado de pesquisa do Laboratório de Inteligência Artificial de Xangai fornece uma referência para isso. A pesquisa, que foi apresentada na principal conferência de visão computacional CVPR 2024 pesquisa recebida, lançou uma avaliação especializada da PDF Benchmarking de recursos de análise de documentos -OmniDocBench。
OmniDocBench A partir de 200.000 PDF Os recursos visuais são extraídos dos documentos, e 6.000 páginas com diferenciação significativa são filtradas por meio de análise de agrupamento, e 981 delas são finalmente anotadas com anotações refinadas. As dimensões da anotação são muito ricas, abrangendo caixas delimitadoras de layout, atributos de layout, ordem de leitura e relações hierárquicas etc. É especialmente fácil anotar a relevância do conteúdo entre páginas.
Em termos de indicadores de avaliação.OmniDocBench Para diferentes dimensões, como texto, tabelas, fórmulas e ordem de leitura, Normalised Edit Distance (NED), Tree Edit Distance Based Similarity (TEDS) e BLEU e muitos outros algoritmos para garantir que a avaliação seja abrangente e justa.
Quem são os líderes em cada dimensão?
OmniDocBench O relatório de avaliação revela uma tendência interessante.

(Fonte: https://arxiv.org/abs/2402.07626)
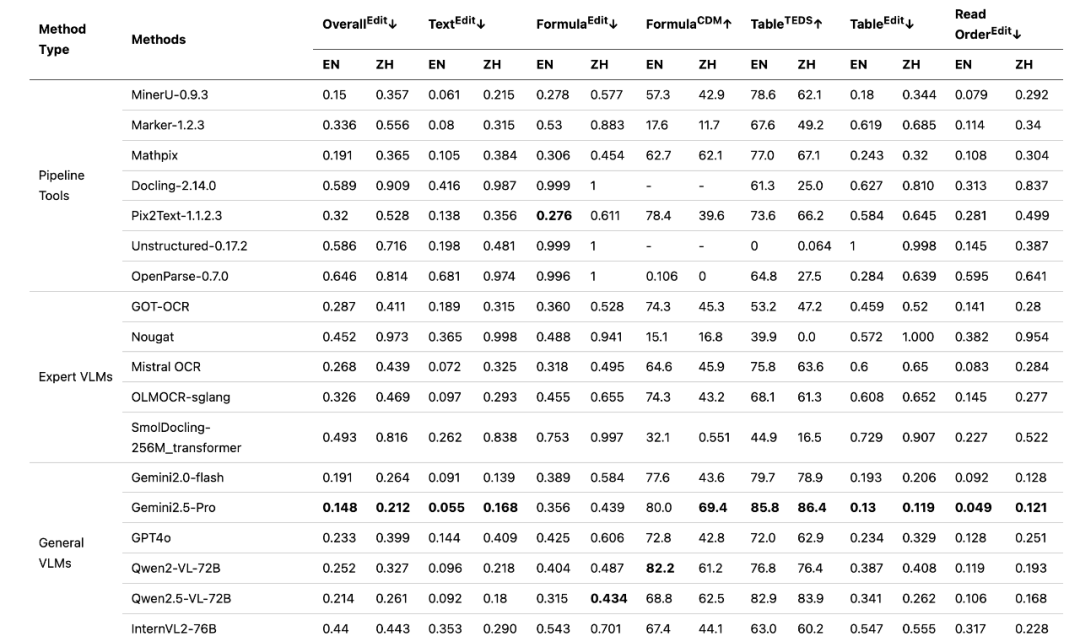
(Fonte: https://github.com/opendatalab/OmniDocBench/blob/main/README_zh-CN.md)
Nos primeiros gráficos de tese do projeto, vários tipos de ferramentas tradicionais de análise de documentos competiam entre si em diferentes dimensões. No entanto, quando macromodelos visuais genéricos (por exemplo Gemini 1.5 Pro) foi incluída na análise, pois suas sólidas capacidades gerais permitiram que ela alcançasse uma posição de liderança em todos os indicadores.
Essa vantagem decorre de Gemini Macromodelos multimodais nativos como esses são capazes de processar informações de imagem e texto de ponta a ponta para entender melhor o layout geral e a semântica de um documento. Mas esse recurso avançado tem um alto custo.
以 Gemini 1.5 Pro Por exemplo, embora reconhecesse com precisão a escrita manuscrita, ainda apresentava erros significativos de análise ao lidar com uma tabela complexa contendo várias células mescladas e rótulos de canto.
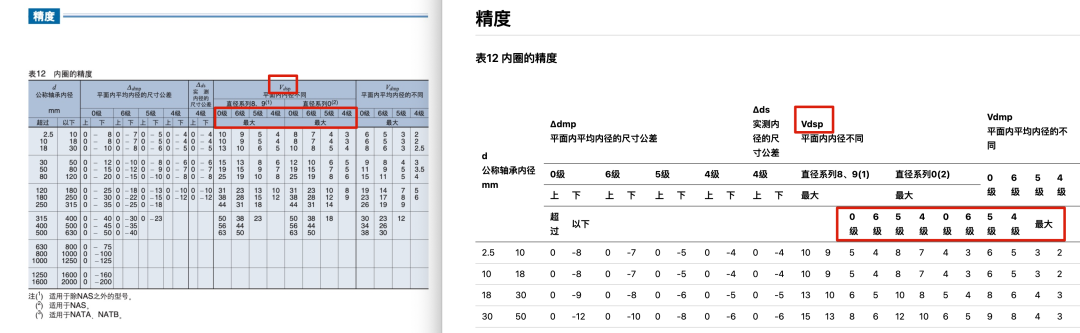
(Use Gemini 1.5 Pro Exemplos de erros ao analisar tabelas complexas)
Mais importante ainda é a questão do custo. Apenas analisando esta página PDFO custo foi de aproximadamente RMB 1,2 yuan. A principal fonte de custo é a saída do modelo de Token o que representa uma enorme sobrecarga para as organizações que precisam processar documentos em grande escala.
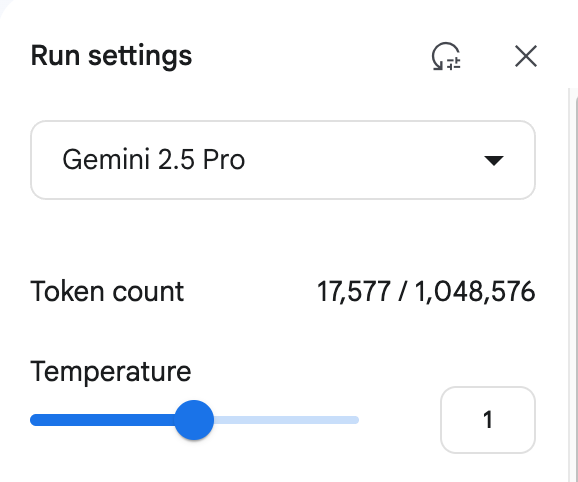
(Use Gemini 1.5 Pro (Exemplo de consumo de custos para análise de documentos)
Portanto.Gemini Não é um antídoto único para todos os cenários. No Gemini Além disso, o setor tem unstructured.io、Marker 和 PyMuPDF e muitas outras excelentes soluções comerciais ou de código aberto que podem ser mais vantajosas para tarefas específicas e controle de custos. A escolha certa começa com uma definição clara do cenário do aplicativo e a necessidade de encontrar um equilíbrio entre desempenho, custo e necessidades específicas.
Conselhos práticos
Ao criar ou otimizar RAG Quando o sistema, os desenvolvedores podem consultar as etapas a seguir para superar o problema de análise de documentos:
- Biblioteca de documentação de diagnósticoRevisão de seus documentos para identificar os contratos, relatórios ou digitalizações mais difíceis, esclarecendo se os principais desafios neles são decorrentes de tabelas complexas, fórmulas matemáticas ou layouts de página específicos.
- Validação direcionada:: Comparação
OmniDocBenchou outros relatórios de análise, selecione uma ou duas ferramentas que se destacam em dimensões específicas para validação direcionada, a fim de encontrar a solução que melhor atenda às suas necessidades comerciais. - De olho nas fronteiras: A tecnologia de análise de documentos ainda está evoluindo rapidamente, fique atento!
OmniDocBenchEsses tipos de estudos de benchmark e ferramentas de análise emergentes podem ajudá-lo a otimizar continuamente o desempenho do sistema.
Pesquisas relacionadas
OmniDocBenchTese: https://arxiv.org/abs/2402.07626






































