



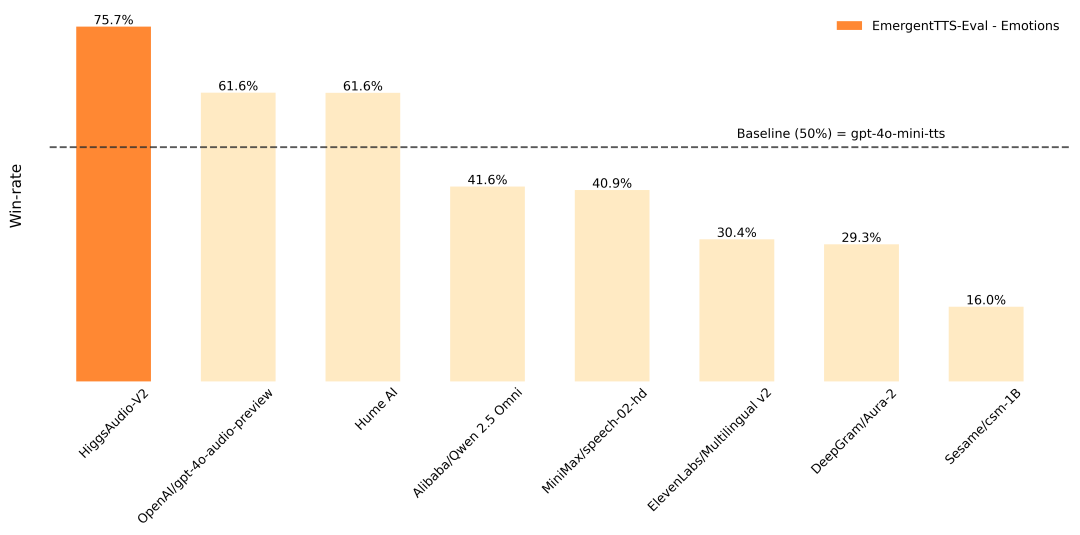
O Higgs Audio é um projeto de conversão de texto em fala (TTS) de código aberto desenvolvido pela Boson AI, focado na geração de fala de alta qualidade e emocionalmente rica e no diálogo com vários caracteres. O projeto baseia-se em mais de 10 milhões de horas de treinamento de dados de áudio e oferece suporte à clonagem de fala de amostra zero, geração de diálogo natural e saída de fala multilíngue. O Higgs Audio v2 usa uma arquitetura Dual-FFN inovadora e o Unified Audio Phrase Splitter para processar com eficiência as informações de texto e áudio e gerar efeitos de fala realistas. Ele tem um bom desempenho no benchmark EmergentTTS-Eval com uma taxa de ganho de expressão emocional de 75,7%, significativamente melhor do que outros modelos. O projeto fornece código detalhado e guias de instalação para desenvolvedores, pesquisadores e criadores, e é amplamente utilizado na criação de conteúdo de áudio, assistentes virtuais e educação.
Lista de funções
- Geração de fala de alta qualidade: Converta texto em uma fala natural e rica em emoções que suporta uma ampla gama de entonação e expressão emocional.
- Geração de diálogos com várias funções: suporta a geração de discursos com várias funções, simulando pausas, interrupções e sobreposições em diálogos naturais.
- Clonagem de voz com amostra zero: gere rapidamente a voz do personagem-alvo a partir do áudio de referência sem treinamento adicional.
- Suporte a vários idiomas: suporta a geração de fala em inglês, chinês, alemão, coreano e outros idiomas.
- Combinação de música e fala: pode gerar música de fundo e fala ao mesmo tempo, o que é adequado para narração de histórias em áudio ou experiências imersivas.
- Inferência eficiente: suporta a execução em dispositivos de borda, como o Jetson Orin Nano, com um baixo consumo de recursos.
- Código-fonte aberto: forneça uma base de código e uma API completas, dê suporte aos desenvolvedores para que personalizem o desenvolvimento.
Usando a Ajuda
Processo de instalação
O Higgs Audio é um projeto de código aberto hospedado no GitHub. O processo de instalação é simples, mas requer algum suporte do ambiente de desenvolvimento. Abaixo estão as etapas detalhadas de instalação, aplicáveis a diferentes ambientes:
1. clonagem da base de código
Primeiro, clone o repositório GitHub do Higgs Audio localmente:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
2. ambiente de configuração
O Higgs Audio oferece várias maneiras de configurar o ambiente, incluindo ambientes virtuais, Conda e uv. Recomenda-se o Python 3.10 ou superior. Veja a seguir as etapas para configurar um ambiente virtual:
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
Se você usar o Conda:
conda create -n higgs_audio_env python=3.10
conda activate higgs_audio_env
pip install -r requirements.txt
pip install -e .
Para cenários de alto rendimento, é recomendável usar o vLLM Motor. Referência examples/vllm execute o seguinte comando para iniciar o servidor de API:
python -m vllm.entrypoints.openai.api_server --model bosonai/higgs-audio-v2-generation-3B-base --tensor-parallel-size 4 --gpu-memory-utilization 0.9
Requisitos de hardwarePara obter o melhor desempenho, recomenda-se uma GPU com pelo menos 24 GB de memória de vídeo (como a NVIDIA RTX 4090). Dispositivos de borda, como o Jetson Orin Nano, também podem executar modelos menores.
3. verificação da instalação
Após a conclusão da instalação, execute o seguinte código Python para verificar se o ambiente está configurado corretamente:
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine
engine = HiggsAudioServeEngine(
"bosonai/higgs-audio-v2-generation-3B-base",
"bosonai/higgs-audio-v2-tokenizer",
device="cuda"
)
output = engine.generate(content="Hello, welcome to Higgs Audio!", voice_profile="neutral")
Se um arquivo de áudio for gerado, a instalação foi bem-sucedida.
Função Fluxo de operação
Os principais recursos do Higgs Audio incluem conversão de texto em fala, geração de diálogos com vários caracteres e clonagem de voz. Veja a seguir as etapas para fazer isso:
1. conversão de texto em fala
O Higgs Audio oferece suporte à conversão de texto em fala natural, e a expressão emocional pode ser expressa por meio do voice_profile Controle de parâmetros. Por exemplo, para gerar uma voz com um tom "urgente":
curl http://localhost:8000/v1/audio/generation -H "Content-Type: application/json" -d '{"text": "Security alert: Unauthorized access detected", "voice_profile": "urgent"}'
Os usuários podem especificar diferentes rótulos de emoção (por exemplo happy、sad、neutral), o modelo ajusta automaticamente o tom e o ritmo de acordo com a semântica do texto.
2) Geração de diálogo com vários atores
O Higgs Audio é bom para gerar diálogos com vários caracteres que simulam interações naturais em cenários da vida real. O usuário deve fornecer um texto contendo tags de caracteres, por exemplo:
dialogue = """
SPEAKER_0: Hey, have you tried Higgs Audio yet?
SPEAKER_1: Yeah, it’s amazing! The voices sound so real!
"""
output = engine.generate(content=dialogue, multi_speaker=True)
O modelo gera vozes diferentes com base em tags de caracteres, adicionando automaticamente pausas e mudanças de tom, o que o torna adequado para uso em audiolivros ou diálogos de jogos.
3. clonagem de fala com amostra zero
O usuário pode fornecer um trecho de áudio de referência e o modelo clonará seus recursos de fala. Exemplo:
output = engine.generate(
content="This is a test sentence.",
reference_audio="path/to/reference.wav",
voice_profile="cloned"
)
O áudio de referência deve ser uma única voz clara com duração recomendada de 5 a 10 segundos. A voz clonada pode ser usada para geração de áudio personalizado.
4. suporte multilíngue
O Higgs Audio oferece suporte à geração de fala multilíngue. Os usuários só precisam especificar o conteúdo do idioma no texto e o modelo se adaptará automaticamente. Por exemplo:
output = engine.generate(content="你好,欢迎体验Higgs Audio!", voice_profile="neutral")
Atualmente, há suporte para inglês, chinês, alemão e coreano, mas pode haver limitações no manuseio de números e símbolos chineses, que precisam ser otimizados ainda mais.
5. integração de música e fala
O Higgs Audio gera fala com música de fundo para experiências imersivas. Os usuários devem adicionar tags de música ao texto:
content = "[music_start] The stars shimmered above. [music_end] This is a magical night."
output = engine.generate(content=content, background_music=True)
O modelo gera música de fundo com base em tags e a mescla com a fala.
Precauções de uso
- Otimização de hardwareExecução na GPU pode melhorar significativamente a velocidade de inferência. Os dispositivos de borda precisam usar modelos menores para reduzir o uso de recursos.
- formato de entradaEntrada de texto: A entrada de texto precisa ser clara, evitando símbolos complexos ou erros de formatação para garantir uma geração eficaz.
- Áudio de referênciaClonagem de voz: A clonagem de voz requer áudio de referência de alta qualidade para evitar a interferência de ruídos de fundo.
- multilinguismoSímbolos complexos: algarismos chineses e sinais de porcentagem podem levar a uma geração ruim, e recomenda-se evitar símbolos complexos.
cenário do aplicativo
- Produção de audiolivros
O Higgs Audio transforma textos de livros em audiolivros ricos em emoções, com suporte para diálogos com vários personagens e trilhas sonoras, adequados para editoras ou criadores individuais que produzem audiolivros de alta qualidade. - Criação de conteúdo educacional
Os professores podem usar o Higgs Audio para gerar fala ou áudio instrucional multilíngue de figuras históricas para aprimorar a imersão e a interatividade de suas aulas. - desenvolvimento de jogos
Os desenvolvedores podem usar o recurso de diálogo com vários personagens para gerar vozes dinâmicas de personagens para jogos que suportam interrupções naturais e expressões emocionais para aprimorar a experiência do jogo. - Desenvolvimento de assistente virtual
As empresas podem desenvolver assistentes virtuais baseados no Higgs Audio com voz personalizada para atendimento ao cliente ou dispositivos inteligentes. - dublagem (produção de filmes)
A clonagem de voz e o suporte a vários idiomas do Higgs Audio são ideais para gerar dublagens para produções de cinema e TV, adaptando-se rapidamente a diferentes personagens e idiomas.
QA
- Quais idiomas são suportados pelo Higgs Audio?
Atualmente, suporta inglês, chinês, alemão, coreano e outros idiomas, com planos de expandir o suporte para mais idiomas no futuro. - Como otimizar a estabilidade da clonagem de voz?
Forneça áudio de referência claro e de uma única pessoa, com duração de 5 a 10 segundos, evitando o uso direto do áudio gerado como referência para manter o controle emocional. - Ele requer uma GPU para ser executado?
As GPUs aumentam o desempenho, mas modelos menores podem ser executados em dispositivos de ponta, como o Jetson Orin Nano, para aplicativos leves. - Quais são as limitações da geração de fala chinesa?
Os números e símbolos chineses podem causar uma geração ruim; recomenda-se simplificar o texto de entrada, que será otimizado em versões futuras. - Como você lida com as distinções de voz em diálogos com vários personagens?
Ao adicionar tags de caracteres (por exemplo, SPEAKER_0) ao texto, o modelo gera automaticamente diferentes discursos e simula o ritmo natural do diálogo.































