



MedGemma 是 Google 在 Hugging Face 平台上发布的一组开源 AI 模型,专注于医疗领域的文本和图像理解。它基于 Gemma 3 模型开发,旨在帮助开发者构建医疗相关的 AI 应用。MedGemma 提供多种模型变体,包括 4B 参数的多模态模型和 27B 参数的文本及多模态模型。这些模型在医疗文本、电子健康记录 (EHR) 和多种医疗影像(如 X 光、皮肤科图像、眼科图像和组织病理切片)上进行专门训练。开发者可以利用这些模型加速医疗 AI 应用开发,例如放射学报告生成、医疗问答和图像分类等。MedGemma 的开源特性使其易于访问,适合研究人员和开发者在单 GPU 上运行,降低开发门槛。
功能列表
- 医疗文本处理:分析和生成医疗相关的文本内容,如医疗报告、问答对和电子健康记录。
- 医疗图像理解:支持多种医疗影像分析,包括胸部 X 光、皮肤科图像、眼科图像和组织病理切片。
- 多模态推理:结合文本和图像数据,提供综合的医疗推理能力,如生成放射学报告或解释图像内容。
- 模型变体选择:提供 4B 参数多模态模型(预训练和指令微调版本)及 27B 参数文本和多模态模型(仅指令微调版本)。
- 高效推理优化:模型经过优化,适合在单 GPU 上运行,降低计算资源需求。
- 开源与可微调:模型完全开源,开发者可根据具体需求进行微调,提升性能。
使用帮助
安装与部署
MedGemma 模型托管在 Hugging Face 平台,开发者无需复杂安装即可使用。以下是具体操作步骤:
- 访问模型页面
打开https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4,浏览 MedGemma 模型集合。页面包含 4B 和 27B 参数模型的下载链接和文档。 - 环境准备
- 确保安装 Python 3.8 或更高版本。
- 安装 Hugging Face 的 Transformers 库,运行以下命令:
pip install transformers - 安装 PyTorch 或 TensorFlow(根据模型需求选择)。例如,安装 PyTorch:
pip install torch - 如果处理图像数据,需安装额外库如
Pillow:pip install Pillow
- 下载模型
在 Hugging Face 模型页面,选择需要的 MedGemma 变体(如google/medgemma-4b-it或google/medgemma-27b-multimodal)。使用以下代码下载并加载模型:from transformers import AutoModel, AutoTokenizer model_name = "google/medgemma-4b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name)27B 模型需要更多内存,建议使用至少 16GB 显存的 GPU。
- 运行环境
MedGemma 模型支持在单 GPU 上运行,适合本地开发或云端部署。推荐使用 Google Cloud 或 Hugging Face Inference Endpoints 进行部署,具体参考https://gke-ai-labs.dev/的部署指南。
主要功能操作
1. 医疗文本处理
MedGemma 可处理医疗文本,如生成报告或回答医疗问题。操作步骤如下:
- 输入准备:准备医疗相关文本,例如一段电子健康记录或医疗问题。
- 代码示例:
input_text = "患者胸部 X 光显示肺部阴影,可能是什么原因?" inputs = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - 结果:模型会生成可能的诊断解释或建议,基于其在医疗文本上的训练。
2. 医疗图像理解
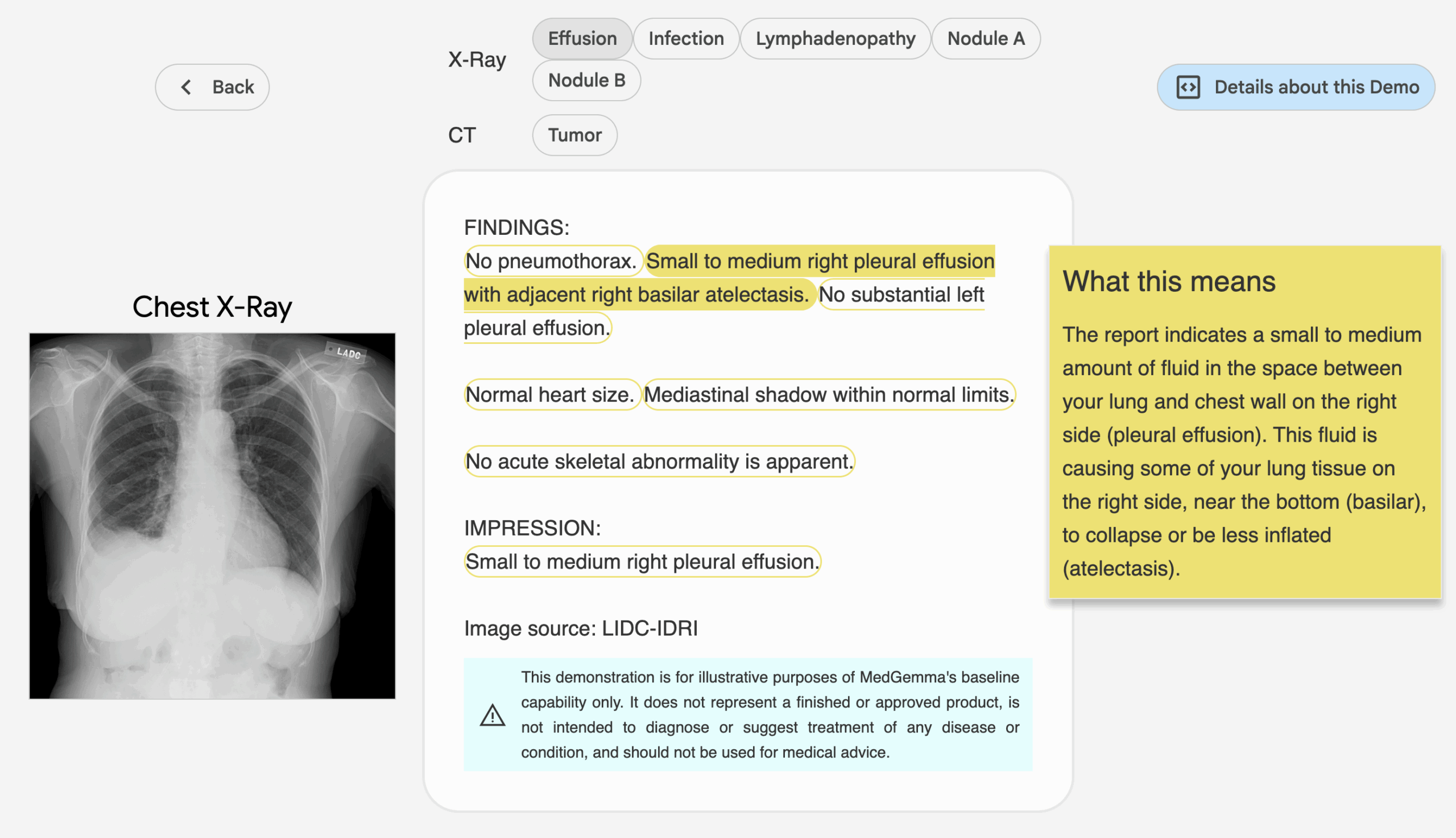
MedGemma 的多模态模型支持分析医疗影像(如 X 光、皮肤图像)。操作步骤:
- 图像预处理:将图像转换为模型可接受的格式(如 PNG 或 JPEG)。
- 代码示例(以 4B 多模态模型为例):
from PIL import Image import torch image = Image.open("chest_xray.png").convert("RGB") inputs = tokenizer(text="描述这张胸部 X 光图像", images=[image], return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - 结果:模型生成图像描述或诊断建议,如“图像显示右肺下叶有阴影,可能提示肺炎”。
3. 多模态推理
多模态模型可同时处理文本和图像。例如,输入一张 X 光图像和问题“此图像是否显示肺炎迹象?”,模型会结合图像和文本生成回答。操作与上述类似,只需在 tokenizer 中同时传入文本和图像。
4. 模型微调
开发者可根据特定任务微调模型。步骤如下:
- 收集特定医疗数据集(如自定义的放射学图像或文本)。
- 使用 Hugging Face 的
TrainerAPI 进行微调:from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./medgemma_finetuned", per_device_train_batch_size=4, num_train_epochs=3, ) trainer = Trainer(model=model, args=training_args, train_dataset=your_dataset) trainer.train() - 保存微调后的模型,供后续使用。
注意事项
- 数据污染风险:MedGemma 在预训练中可能接触过公开医疗数据,开发者需使用未公开的数据集验证模型性能,以确保其泛化能力。
- 非临床使用:MedGemma 仅用于研究和开发,未经验证不可用于实际临床诊断。
- 硬件要求:4B 模型适合低资源环境,27B 模型需要更高性能 GPU。
应用场景
- 放射学报告生成
放射科医生可使用 MedGemma 分析 X 光或 CT 图像,生成初步报告,辅助医生快速解读影像。 - 医疗问答系统
开发者可构建医疗问答机器人,利用 MedGemma 的文本处理能力回答患者或医学生的常见问题。 - 电子健康记录分析
医疗机构可使用 27B 多模态模型解析复杂的 EHR 数据,提取关键信息,优化诊疗流程。 - 医学研究支持
研究人员可利用 MedGemma 分析医学文献或图像数据集,加速研究进程,例如皮肤病图像分类或组织病理分析。
QA
- MedGemma 可以用于实际临床诊断吗?
目前 MedGemma 仅用于研究和开发,未经临床验证不可直接用于诊断。开发者需进一步验证模型在特定任务上的可靠性。 - 27B 模型和 4B 模型有何区别?
4B 模型适合低资源环境,支持多模态和文本任务;27B 模型分为文本和多模态版本,性能更强,适合复杂任务,但需要更高计算资源。 - 如何处理数据污染问题?
使用非公开或机构内部数据集验证模型,避免预训练数据影响泛化能力。 - MedGemma 支持哪些医疗影像?
支持胸部 X 光、皮肤科图像、眼科图像和组织病理切片等多种医疗影像。
































