



LangExtract 是 Google 开发的一款开源 Python 库,专注于从非结构化文本中提取结构化数据。它利用大型语言模型(LLM)如 Google Gemini 系列,结合精确的源文本定位和交互式可视化功能,帮助用户快速将复杂文本转化为清晰的数据格式。用户只需提供少量示例,就能定义适用于任何领域的提取任务,无需对模型进行微调。LangExtract 特别适合处理长文档,支持并行处理和多轮提取,广泛应用于医疗、文学分析等领域。该工具以 Apache 2.0 许可证发布,代码托管于 GitHub,开放社区贡献。
功能列表
- 支持多种语言模型:兼容 Google Gemini 等云端模型及 Ollama 本地模型,灵活适配用户需求。
- 结构化信息提取:从非结构化文本中提取实体、关系和属性,并生成 JSONL 格式输出。
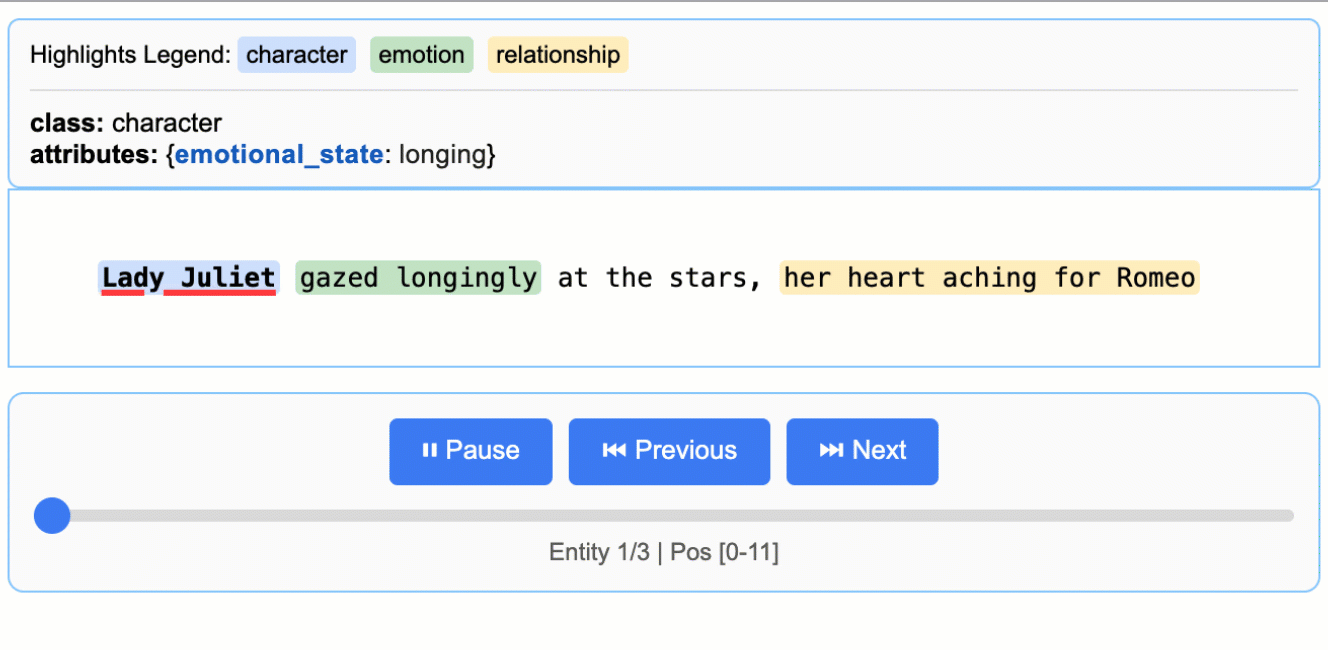
- 交互式可视化:从提取结果生成 HTML 可视化文件,方便用户查看和分析提取的实体。
- 长文档处理:通过智能分块和并行处理,高效处理超长文本,如整本小说或医疗报告。
- 自定义提取任务:通过提示词和少量示例,快速定义适用于特定领域的提取规则。
- 医疗文本处理:支持从临床笔记中提取药物名称、剂量等信息,适用于医疗领域。
- API 集成:支持云端模型 API 调用,也可扩展到第三方本地模型推理端点。
使用帮助
安装流程
LangExtract 使用 Python 开发,支持现代 Python 包管理方式。以下是详细的安装步骤:
- 克隆代码仓库
打开终端,运行以下命令克隆 LangExtract 仓库:git clone https://github.com/google/langextract.git cd langextract - 安装依赖
使用 pip 安装 LangExtract。推荐使用开发模式以便修改代码:pip install -e .如果需要开发或测试环境,安装额外依赖:
pip install -e ".[dev]" # 包含 linting 工具 pip install -e ".[test]" # 包含 pytest 测试工具 - 配置 API 密钥(如使用云端模型)
如果使用 Google Gemini 等云端模型,需要配置 API 密钥。将密钥写入.env文件:cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOF为保护密钥,添加
.env到.gitignore:echo '.env' >> .gitignore本地模型(如通过 Ollama 运行)无需 API 密钥。
- 验证安装
运行以下命令检查安装是否成功:python -c "import langextract; print(langextract.__version__)"
使用方法
LangExtract 的核心功能是通过提示词和示例从文本中提取结构化数据。以下是具体操作流程:
1. 基本信息提取
假设你要从一段文本中提取人物、情感和关系,代码示例如下:
import langextract as lx
import textwrap
# 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities.
""")
# 提供示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
{"entity": "Romeo", "type": "character", "emotion": "hopeful"},
]
)
]
# 输入文本
text = "ROMEO. But soft! What light through yonder window breaks? It is Juliet."
# 执行提取
result = lx.extract(text, prompt=prompt, examples=examples, model="gemini-2.5-flash")
# 保存结果
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
运行后,提取结果将保存为 extraction_results.jsonl 文件,包含提取的实体及其属性。
2. 生成交互式可视化
LangExtract 支持将提取结果生成 HTML 可视化文件,方便查看:
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
生成的 visualization.html 文件可在浏览器中打开,展示提取的实体及其上下文。
3. 处理长文档
对于长文档(如整本《罗密欧与朱丽叶》),LangExtract 使用智能分块和并行处理:
url = "https://www.gutenberg.org/files/1513/1513.txt"
result = lx.extract_from_url(url, prompt=prompt, examples=examples, max_workers=4)
lx.io.save_annotated_documents([result], output_name="long_doc_results.jsonl")
max_workers 参数控制并行处理的线程数,适合处理大文件。
4. 医疗文本提取
LangExtract 在医疗领域表现优异,可提取药物名称、剂量等信息。示例:
prompt = "Extract medication names, dosages, and administration routes from clinical notes."
text = "Patient prescribed Metformin 500 mg orally twice daily."
result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro")
结果将包含提取的药物信息,如:
{"entity": "Metformin", "dosage": "500 mg", "route": "orally"}
特色功能操作
- 模型选择:默认使用
gemini-2.5-flash模型,速度和质量均衡。对于复杂任务,可切换到gemini-2.5-pro:result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro") - 多轮提取:通过多次提取提高准确性,适合复杂文档:
result = lx.extract(text, prompt=prompt, num_passes=2) - RadExtract 演示:LangExtract 提供在线演示 RadExtract,专门处理放射学报告。访问 HuggingFace Spaces(
https://google-radextract.hf.space)即可试用,无需安装。
注意事项
- 云端模型需稳定的 API 密钥和网络连接。
- 处理超长文档时,建议使用 Tier 2 Gemini 配额以避免速率限制。
- 保存 API 密钥时,确保
.env文件安全。
应用场景
- 医疗数据处理
医院和研究机构可使用 LangExtract 从临床笔记或放射学报告中提取药物、剂量、诊断等信息。例如,放射学报告可被结构化为包含标题和关键实体的格式,便于数据分析和临床决策。 - 文学分析
研究人员可从长篇文学作品中提取人物、情感和关系。例如,分析《罗密欧与朱丽叶》中的角色互动,生成可视化结果以研究人物关系网。 - 商业情报提取
企业可从新闻、报告或社交媒体中提取关键实体(如公司名、产品、事件),用于市场分析或竞争情报收集。 - 法律文档处理
律师事务所可从合同或法律文件中提取条款、日期、当事人等信息,快速生成结构化摘要。
QA
- LangExtract 是否免费?
LangExtract 是开源工具,代码免费使用(Apache 2.0 许可证)。但使用云端模型(如 Gemini)需支付 API 调用费用。 - 是否支持本地模型?
支持通过 Ollama 运行本地开源模型,无需 API 密钥,适合无网络环境。 - 如何处理超长文档?
使用智能分块和并行处理(设置max_workers),并建议多次提取(设置num_passes)以提高准确性。 - 可视化结果如何查看?
运行lx.visualize生成 HTML 文件,在浏览器中打开即可交互式查看提取结果。 - 医疗应用是否合规?
LangExtract 仅为演示工具,非医疗诊断设备。健康相关应用需遵守《Health AI Developer Foundations Terms of Use》。





























