



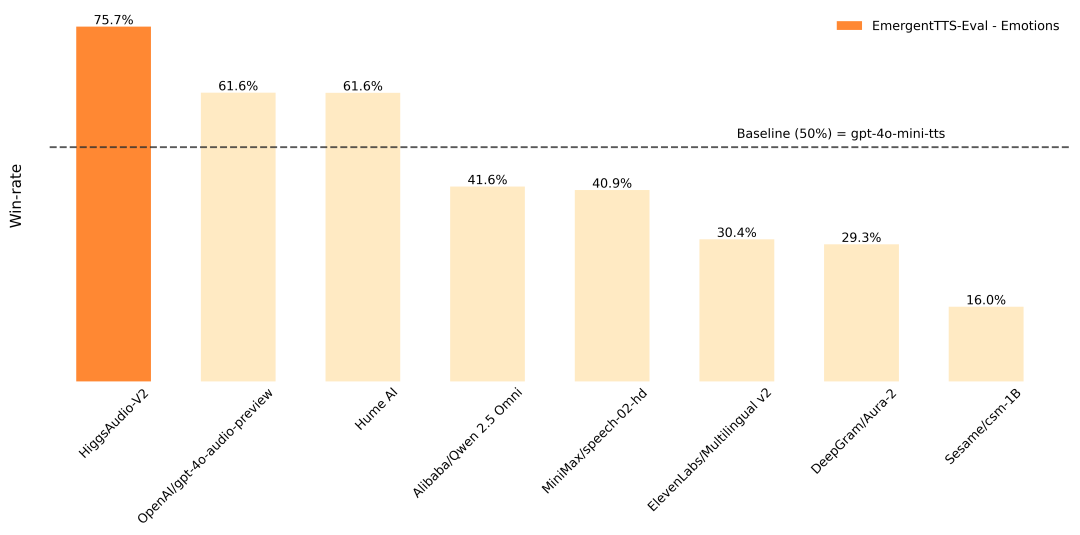
Higgs Audio 是由 Boson AI 开发的一个开源文本转语音(TTS)项目,专注于生成高质量、情感丰富的语音和多角色对话。项目基于超过1000万小时的音频数据训练,支持零样本语音克隆、自然对话生成和多语言语音输出。Higgs Audio v2 采用创新的 Dual-FFN 架构和统一音频分词器,能高效处理文本和音频信息,生成逼真的语音效果。它在 EmergentTTS-Eval 基准测试中表现出色,情感表达胜率达75.7%,显著优于其他模型。项目提供详细的代码和安装指南,适合开发者、研究人员和创作者使用,广泛应用于音频内容创作、虚拟助手和教育等领域。
功能列表
- 生成高质量语音:将文本转化为自然、情感丰富的语音,支持多种语调和情感表达。
- 多角色对话生成:支持多角色语音生成,模拟自然对话中的停顿、中断和重叠。
- 零样本语音克隆:通过参考音频快速生成目标角色的语音,无需额外训练。
- 多语言支持:支持英语、中文、德语、韩语等多种语言的语音生成。
- 音乐与语音结合:能同时生成背景音乐和语音,适合音频故事或沉浸式体验。
- 高效推理:支持在边缘设备(如 Jetson Orin Nano)上运行,资源占用低。
- 开源代码:提供完整的代码库和 API,支持开发者自定义开发。
使用帮助
安装流程
Higgs Audio 是开源项目,托管在 GitHub 上,安装过程简单但需要一定的开发环境支持。以下是详细的安装步骤,适用于不同环境:
1. 克隆代码库
首先,克隆 Higgs Audio 的 GitHub 仓库到本地:
git clone https://github.com/boson-ai/higgs-audio.git
cd higgs-audio
2. 配置环境
Higgs Audio 提供多种环境配置方式,包括虚拟环境、Conda 和 uv。推荐使用 Python 3.10 及以上版本。以下是虚拟环境的配置步骤:
python3 -m venv higgs_audio_env
source higgs_audio_env/bin/activate
pip install -r requirements.txt
pip install -e .
如果使用 Conda:
conda create -n higgs_audio_env python=3.10
conda activate higgs_audio_env
pip install -r requirements.txt
pip install -e .
对于高吞吐量场景,建议使用 vLLM 引擎。参考 examples/vllm 文件夹中的说明,运行以下命令启动 API 服务器:
python -m vllm.entrypoints.openai.api_server --model bosonai/higgs-audio-v2-generation-3B-base --tensor-parallel-size 4 --gpu-memory-utilization 0.9
硬件要求:为获得最佳性能,建议使用至少 24GB 显存的 GPU(如 NVIDIA RTX 4090)。边缘设备如 Jetson Orin Nano 也可运行较小模型。
3. 验证安装
安装完成后,运行以下 Python 代码验证环境是否正确配置:
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine
engine = HiggsAudioServeEngine(
"bosonai/higgs-audio-v2-generation-3B-base",
"bosonai/higgs-audio-v2-tokenizer",
device="cuda"
)
output = engine.generate(content="Hello, welcome to Higgs Audio!", voice_profile="neutral")
如果输出音频文件,说明安装成功。
功能操作流程
Higgs Audio 的核心功能包括文本转语音、多角色对话生成和语音克隆。以下是具体操作步骤:
1. 文本转语音
Higgs Audio 支持将文本转化为自然语音,情感表达可通过 voice_profile 参数控制。例如,生成一段带有“紧急”语调的语音:
curl http://localhost:8000/v1/audio/generation -H "Content-Type: application/json" -d '{"text": "Security alert: Unauthorized access detected", "voice_profile": "urgent"}'
用户可以指定不同的情感标签(如 happy、sad、neutral),模型会根据文本语义自动调整语调和节奏。
2. 多角色对话生成
Higgs Audio 擅长生成多角色对话,模拟真实场景中的自然交互。用户需提供包含角色标签的文本,例如:
dialogue = """
SPEAKER_0: Hey, have you tried Higgs Audio yet?
SPEAKER_1: Yeah, it’s amazing! The voices sound so real!
"""
output = engine.generate(content=dialogue, multi_speaker=True)
模型会根据角色标签生成不同语音,自动添加停顿和语气变化,适合用于有声书或游戏对话。
3. 零样本语音克隆
用户可以提供一段参考音频,模型会克隆其语音特征。例如:
output = engine.generate(
content="This is a test sentence.",
reference_audio="path/to/reference.wav",
voice_profile="cloned"
)
参考音频应为清晰的单人语音,长度建议在 5-10 秒。克隆后的语音可用于个性化音频生成。
4. 多语言支持
Higgs Audio 支持多语言语音生成。用户只需在文本中指定语言内容,模型会自动适配。例如:
output = engine.generate(content="你好,欢迎体验Higgs Audio!", voice_profile="neutral")
目前支持英语、中文、德语、韩语,但中文数字和符号的处理可能存在局限,需进一步优化。
5. 音乐与语音结合
Higgs Audio 可生成带有背景音乐的语音,适合沉浸式体验。用户需在文本中添加音乐标签:
content = "[music_start] The stars shimmered above. [music_end] This is a magical night."
output = engine.generate(content=content, background_music=True)
模型会根据标签生成背景音乐并与语音融合。
使用注意事项
- 硬件优化:在 GPU 上运行可显著提升推理速度。边缘设备需使用较小模型以降低资源占用。
- 输入格式:文本输入需清晰,避免复杂符号或格式错误,以确保生成效果。
- 参考音频:语音克隆需提供高质量参考音频,避免背景噪音干扰。
- 多语言局限:中文数字和百分号可能导致生成效果不佳,建议避免复杂符号。
应用场景
- 有声书制作
Higgs Audio 可将书籍文本转化为情感丰富的有声读物,支持多角色对话和背景音乐,适合出版商或个人创作者制作高质量有声书。 - 教育内容创作
教师可使用 Higgs Audio 生成历史人物的语音或多语言教学音频,提升课程的沉浸感和互动性。 - 游戏开发
开发者可利用多角色对话功能为游戏生成动态角色语音,支持自然中断和情感表达,增强游戏体验。 - 虚拟助手开发
企业可基于 Higgs Audio 开发具有个性化语音的虚拟助手,适用于客户服务或智能设备。 - 影视配音
Higgs Audio 的语音克隆和多语言支持适合为影视作品生成配音,快速适配不同角色和语言。
QA
- Higgs Audio 支持哪些语言?
目前支持英语、中文、德语、韩语等多种语言,未来计划扩展更多语言支持。 - 如何优化语音克隆的稳定性?
提供清晰、单人的参考音频,长度在 5-10 秒,避免直接使用生成音频作为参考以保持情感控制。 - 是否需要 GPU 运行?
GPU 可提升性能,但较小模型可在边缘设备如 Jetson Orin Nano 上运行,适合轻量应用。 - 中文语音生成有何局限?
中文数字和符号可能导致生成效果不佳,建议简化输入文本,未来版本将优化。 - 如何处理多角色对话的语音区分?
通过在文本中添加角色标签(如 SPEAKER_0),模型会自动生成不同语音并模拟自然对话节奏。




























