


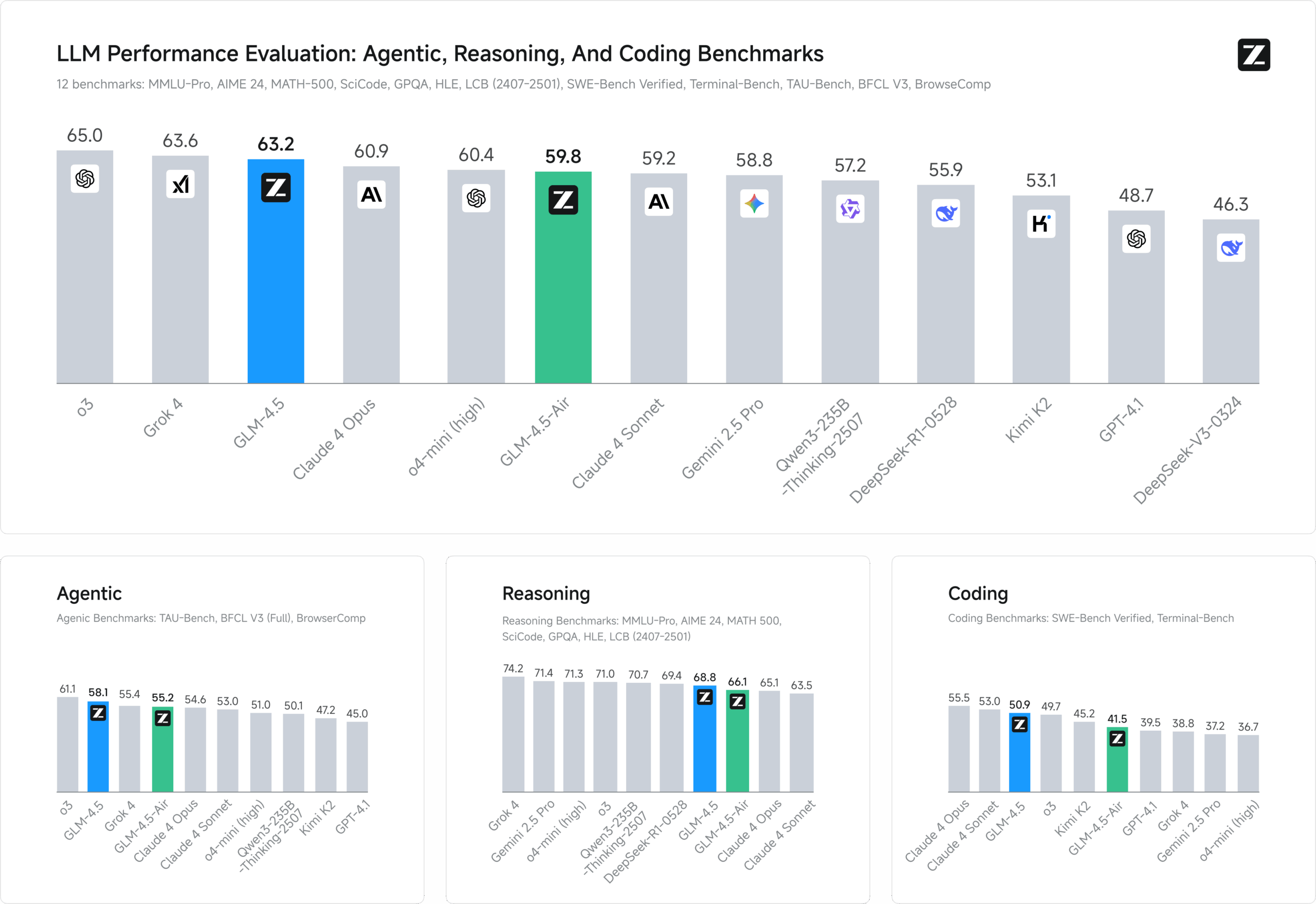
GLM-4.5 是 zai-org 开发的一款开源多模态大语言模型,专为智能推理、代码生成和智能体任务设计。它包含 GLM-4.5(3550 亿参数,320 亿活跃参数)、GLM-4.5-Air(1060 亿参数,120 亿活跃参数)等多个变体,采用混合专家(MoE)架构,支持 128K 上下文长度和 96K 输出令牌。模型在 15 万亿令牌上预训练,经过代码、推理和智能体领域的微调,性能在多个基准测试中名列前茅,特别是在编程和工具调用任务中接近甚至超越部分闭源模型。GLM-4.5 以 MIT 许可证发布,支持学术和商业用途,适合开发者、研究人员和企业在本地或云端部署。
功能列表
- 混合推理模式:支持“思考模式”处理复杂推理和工具调用,“非思考模式”提供快速响应。
- 多模态支持:处理文本和图像输入,适用于多模态问答和内容生成。
- 智能编程:生成 Python、JavaScript 等语言的高质量代码,支持代码补全和 bug 修复。
- 智能体功能:支持函数调用、网页浏览和自动化任务处理,适合复杂工作流。
- 上下文缓存:优化长对话性能,减少重复计算。
- 结构化输出:支持 JSON 等格式,便于系统集成。
- 长上下文处理:原生支持 128K 上下文长度,适合长文档分析。
- 流式输出:提供实时响应,提升交互体验。
使用帮助
GLM-4.5 通过 GitHub 仓库(https://github.com/zai-org/GLM-4.5)提供模型权重和工具,适合有技术背景的用户在本地或云端部署。以下是详细的安装和使用指南,帮助用户快速上手。
安装流程
- 环境准备
确保安装 Python 3.8 或以上版本和 Git。建议使用虚拟环境:python -m venv glm_env source glm_env/bin/activate # Linux/Mac glm_env\Scripts\activate # Windows - 克隆仓库
从 GitHub 获取 GLM-4.5 代码:git clone https://github.com/zai-org/GLM-4.5.git cd GLM-4.5 - 安装依赖
安装指定版本的依赖以确保兼容性:pip install setuptools>=80.9.0 setuptools_scm>=8.3.1 pip install git+https://github.com/huggingface/transformers.git@91221da2f1f68df9eb97c980a7206b14c4d3a9b0 pip install git+https://github.com/vllm-project/vllm.git@220aee902a291209f2975d4cd02dadcc6749ffe6 pip install torchvision>=0.22.0 gradio>=5.35.0 pre-commit>=4.2.0 PyMuPDF>=1.26.1 av>=14.4.0 accelerate>=1.6.0 spaces>=0.37.1注意:vLLM 编译可能耗时较长,若不需要可使用预编译版本。
- 模型下载
模型权重托管在 Hugging Face 和 ModelScope。以下是加载 GLM-4.5-Air 的示例:from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True) model = AutoModel.from_pretrained("zai-org/GLM-4.5-Air", trust_remote_code=True).half().cuda() model.eval() - 硬件要求
- GLM-4.5-Air:需要 16GB GPU 内存(INT4 量化约 12GB)。
- GLM-4.5:建议多 GPU 环境,约需 32GB 内存。
- CPU 推理:GLM-4.5-Air 可在 32GB RAM 的 CPU 上运行,但速度较慢。
使用方法
GLM-4.5 支持命令行、网页界面和 API 调用,提供多种交互方式。
命令行推理
使用 trans_infer_cli.py 脚本进行交互式对话:
python inference/trans_infer_cli.py --model_name zai-org/GLM-4.5-Air
- 输入文本或图像,模型返回响应。
- 支持多轮对话,自动保存历史记录。
- 示例:生成 Python 函数:
response, history = model.chat(tokenizer, "写一个 Python 函数计算三角形面积", history=[]) print(response)输出:
def triangle_area(base, height): return 0.5 * base * height
网页界面
通过 Gradio 启动网页界面,支持多模态输入:
python inference/trans_infer_gradio.py --model_name zai-org/GLM-4.5-Air
- 访问本地地址(通常为
http://127.0.0.1:7860)。 - 输入文本或上传图片、PDF,点击提交获取响应。
- 特色功能:上传 PDF,模型可解析并回答问题。
API 服务
GLM-4.5 支持 OpenAI 兼容的 API,使用 vLLM 部署:
vllm serve zai-org/GLM-4.5-Air --limit-mm-per-prompt '{"image":32}'
- 示例请求:
import requests payload = { "model": "GLM-4.5-Air", "messages": [{"role": "user", "content": "分析这张图片"}], "image": "path/to/image.jpg" } response = requests.post("http://localhost:8000/v1/chat/completions", json=payload) print(response.json())
特色功能操作
- 混合推理模式
- 思考模式 :适合复杂任务,如数学推理或工具调用:
model.chat(tokenizer, "解决方程:2x^2 - 8x + 6 = 0", mode="thinking")模型会输出详细解题步骤。
- 非思考模式 :适合快速问答:
model.chat(tokenizer, "翻译:Good morning", mode="non-thinking") - 多模态支持
- 处理文本和图像输入。例如,上传数学题目图片:
python inference/trans_infer_gradio.py --input math_problem.jpg - 注意:暂不支持同时处理图像和视频。
- 处理文本和图像输入。例如,上传数学题目图片:
- 智能编程
- 生成代码:输入任务描述,生成完整代码:
response, _ = model.chat(tokenizer, "写一个 Python 脚本实现贪吃蛇游戏", history=[]) - 支持代码补全和 bug 修复,适合快速原型开发。
- 生成代码:输入任务描述,生成完整代码:
- 上下文缓存
- 优化长对话性能,减少重复计算:
model.chat(tokenizer, "继续上一轮对话", cache_context=True)
- 优化长对话性能,减少重复计算:
- 结构化输出
- 输出 JSON 格式,便于系统集成:
response = model.chat(tokenizer, "列出 Python 的基本数据类型", format="json")
- 输出 JSON 格式,便于系统集成:
注意事项
- 使用 transformers 4.49.0 可能有兼容性问题,推荐 4.48.3。
- vLLM API 单次输入最多支持 300 张图片。
- 确保 GPU 驱动支持 CUDA 11.8 或以上。
应用场景
- 网页开发
GLM-4.5 生成前端和后端代码,支持快速构建现代 Web 应用。例如,创建交互式网页只需几句描述。 - 智能问答
模型解析复杂查询,结合网页搜索和知识库,提供精准答案,适合客服和教育场景。 - 智慧办公
自动生成逻辑清晰的 PPT 或海报,支持从标题扩展内容,适合办公自动化。 - 代码生成
生成 Python、JavaScript 等代码,支持多轮迭代开发,适合快速原型和 bug 修复。 - 复杂翻译
翻译长篇学术或政策文本,保持语义一致性和风格,适合出版和跨境服务。
QA
- GLM-4.5 和 GLM-4.5-Air 的区别是什么?
GLM-4.5(3550 亿参数,320 亿活跃)适合高性能推理;GLM-4.5-Air(1060 亿参数,120 亿活跃)更轻量,适合资源受限环境。 - 如何优化推理速度?
使用 GPU 加速,启用 INT4 量化,或选择 GLM-4.5-Air 降低资源需求。 - 是否支持商业用途?
是的,MIT 许可证允许免费商业使用。 - 如何处理长上下文?
原生支持 128K 上下文,启用yarn参数可进一步扩展。






























