



ARC-Hunyuan-Video-7B 是一个由腾讯 ARC 实验室开发的开源多模态模型,专注于理解用户生成的短视频内容。它通过整合视频的视觉、音频和文本信息,提供深度的结构化分析。该模型能处理复杂视觉元素、高密度音频信息和快速节奏的短视频,适用于视频搜索、内容推荐和视频摘要等场景。模型采用 7B 参数规模,通过多阶段训练,包括预训练、指令微调和强化学习,确保高效推理和高质量输出。用户可通过 GitHub 访问代码和模型权重,轻松部署到生产环境。
功能列表
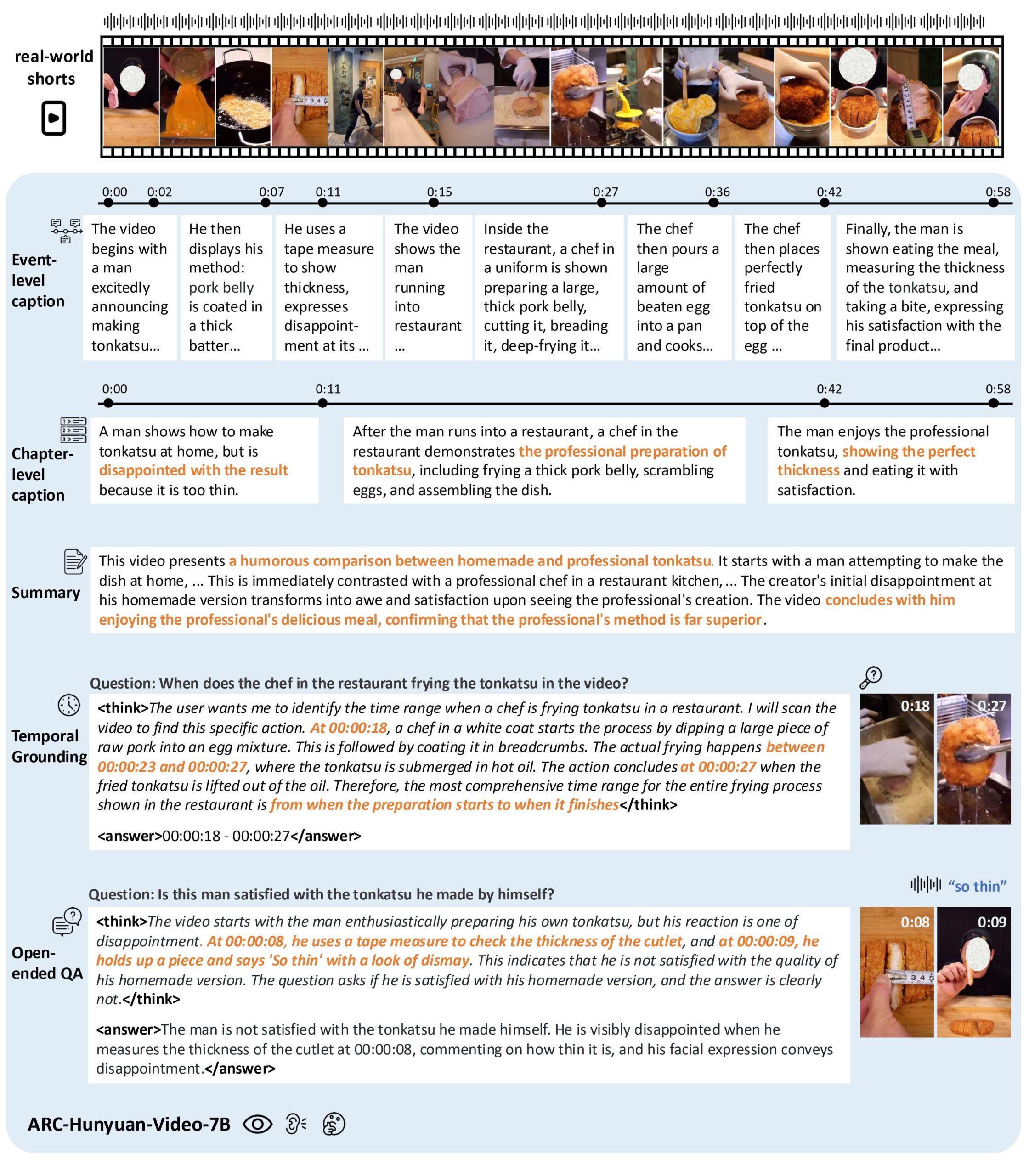
- 视频内容理解:分析短视频的视觉、音频和文本,提取核心信息和情感表达。
- 时间戳标注:支持多粒度时间戳视频描述,精确标注事件发生时间。
- 视频问答:回答关于视频内容的开放性问题,理解视频中的复杂场景。
- 时间定位:定位视频中的特定事件或片段,支持视频搜索和剪辑。
- 视频摘要:生成视频内容的简洁摘要,突出关键信息。
- 多语言支持:支持中英文视频内容分析,特别优化中文视频处理。
- 高效推理:支持 vLLM 加速,1 分钟视频推理仅需 10 秒。
使用帮助
安装流程
要使用 ARC-Hunyuan-Video-7B,用户需要克隆 GitHub 仓库并配置环境。以下是详细步骤:
- 克隆仓库:
git lfs install git clone https://github.com/TencentARC/ARC-Hunyuan-Video-7B cd ARC-Hunyuan-Video-7B - 安装依赖:
确保系统安装了 Python 3.8+ 和 PyTorch 2.1.0+(支持 CUDA 12.1)。运行以下命令安装必要库:pip install -r requirements.txt - 下载模型权重:
模型权重托管在 Hugging Face。用户可通过以下命令下载:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="TencentARC/ARC-Hunyuan-Video-7B", filename="model_weights.bin", repo_type="model")或者直接从 Hugging Face 手动下载并放置到
experiments/pretrained_models/目录。 - 安装 vLLM(可选):
为加速推理,推荐安装 vLLM:pip install vllm - 验证环境:
运行仓库提供的测试脚本,检查环境配置是否正确:python test_setup.py
使用方法
ARC-Hunyuan-Video-7B 支持本地运行和在线 API 调用。以下是主要功能操作流程:
1. 视频内容理解
用户可输入短视频文件(如 MP4 格式),模型会分析视频中的视觉、音频和文本内容,输出结构化描述。例如,输入一个 TikTok 搞笑短视频,模型能提取视频中的动作、对话和背景音乐,生成详细的事件描述。
操作步骤:
- 准备视频文件,放置在
data/input/目录。 - 运行推理脚本:
python inference.py --video_path data/input/sample.mp4 --task content_understanding - 输出结果保存在
output/目录,格式为 JSON,包含视频内容的详细描述。
2. 时间戳标注
模型支持为视频生成带时间戳的描述,适合需要精确事件定位的应用,如视频剪辑或搜索。
操作步骤:
- 使用以下命令运行时间戳标注:
python inference.py --video_path data/input/sample.mp4 --task timestamp_captioning - 输出示例:
[ {"start_time": "00:01", "end_time": "00:03", "description": "人物A进入画面,微笑挥手"}, {"start_time": "00:04", "end_time": "00:06", "description": "背景音乐响起,人物A开始跳舞"} ]
3. 视频问答
用户可针对视频提出开放性问题,模型结合视觉和音频信息回答。例如,“视频中的人物在做什么?”或“视频表达了什么情感?”
操作步骤:
- 创建问题文件
questions.json,格式如下:[ {"video": "sample.mp4", "question": "视频中的主要活动是什么?"} ] - 运行问答脚本:
python inference.py --question_file questions.json --task video_qa - 输出结果为 JSON 格式,包含问题的答案。
4. 时间定位
时间定位功能可定位视频中特定事件的片段。例如,查找“人物跳舞”的片段。
操作步骤:
- 运行定位脚本:
python inference.py --video_path data/input/sample.mp4 --task temporal_grounding --query "人物跳舞" - 输出结果为时间段,如
00:04-00:06。
5. 视频摘要
模型可生成视频内容的简洁摘要,突出核心信息。
操作步骤:
- 运行摘要脚本:
python inference.py --video_path data/input/sample.mp4 --task summarization - 输出示例:
视频展示了一位人物在公园跳舞,背景音乐欢快,传递了轻松愉快的情绪。
6. 在线 API 使用
腾讯 ARC 提供在线 API,用户可通过 Hugging Face 或官方 demo 访问。访问 demo 页面,上传视频或输入问题,模型会实时返回结果。
操作步骤:
- 访问 Hugging Face 的 ARC-Hunyuan-Video-7B demo 页面。
- 上传视频文件或输入问题。
- 查看输出结果,支持下载 JSON 格式的分析数据。
注意事项
- 视频分辨率:在线 demo 使用压缩分辨率,可能影响性能。建议本地运行以获得最佳效果。
- 硬件要求:推荐使用 NVIDIA H20 GPU 或更高配置,确保推理速度。
- 语言支持:模型对中文视频优化更好,英文视频表现稍逊。
应用场景
- 视频搜索
用户可通过关键词搜索视频中的特定事件或内容,例如在视频平台查找“烹饪教程”或“搞笑片段”。 - 内容推荐
模型分析视频的核心信息和情感,帮助平台推荐符合用户兴趣的内容,如推荐欢快音乐的短视频。 - 视频剪辑
创作者可利用时间戳标注和时间定位功能,快速提取视频中的关键片段,制作精华剪辑。 - 教育培训
在教学视频中,模型可生成摘要或回答学生的问题,帮助快速理解课程内容。 - 社交媒体分析
品牌可分析 TikTok 或 WeChat 上的用户生成内容,了解观众的情感反应和偏好。
QA
- 模型支持哪些视频格式?
支持常见格式如 MP4、AVI、MOV。建议视频时长控制在 1-5 分钟以获得最佳性能。 - 如何优化推理速度?
使用 vLLM 加速推理,并确保 GPU 支持 CUDA 12.1。降低视频分辨率也可减少计算量。 - 是否支持长视频?
模型主要优化短视频(5 分钟内)。长视频需分段处理,建议使用预处理脚本拆分视频。 - 模型是否支持实时处理?
是的,使用 vLLM 部署后,1 分钟视频推理仅需 10 秒,适合实时应用。






























