



Whisper_Cloudflare 是一个由开发者 thun888 创建的开源项目,托管于 GitHub。它基于 OpenAI 的 Whisper 模型,结合 Cloudflare Workers 的无服务器架构,提供高效的语音转文字功能。用户通过部署单个 worker.js 文件,即可将音频文件转换为文本或生成 SRT 格式的字幕文件。该项目支持多种语言和音频格式,操作简单,适合开发者快速构建语音处理应用。项目完全免费,代码公开,部署无需管理服务器,适合个人或团队处理音频转录和字幕生成需求。
功能列表
- 语音转文字:将音频文件转换为文本,支持多语言识别。
- 字幕生成:生成带时间戳的 SRT 格式字幕文件。
- 支持多种音频格式:兼容 MP3、WAV 等常见音频格式。
- 服务器less部署:通过 Cloudflare Workers 快速部署,仅需
worker.js文件。 - API 接口:提供
/raw(原始转录数据)和/srt(字幕文件)两种接口。 - 语音活动检测(VAD):支持
vad_filter参数,过滤非语音部分。 - 上下文优化:通过
initial_prompt和prefix参数提升转录准确性。 - 翻译功能:支持将音频内容翻译为指定语言(如英语、中文等)。
使用帮助
部署流程
部署 Whisper_Cloudflare 项目只需将提供的 worker.js 代码复制到 Cloudflare Workers 平台,无需克隆整个 GitHub 仓库。以下是详细步骤:
- 注册 Cloudflare 账户
访问 Cloudflare 官网,注册或登录账户。确保已启用 Workers 功能(免费计划即可)。在 Cloudflare 仪表板中,进入“Workers”页面,点击“创建 Worker”。 - 创建 Worker 并粘贴代码
- 在 Workers 编辑器中,创建一个新 Worker(默认命名为
worker或自定义名称)。 - 将提供的
worker.js代码复制并粘贴到编辑器中,覆盖默认代码。 - 保存代码。
- 在 Workers 编辑器中,创建一个新 Worker(默认命名为
- 安装 Wrangler(可选,用于命令行部署)
如果希望通过命令行管理 Worker,需安装 Wrangler(Cloudflare Workers 的命令行工具)。确保已安装 Node.js(建议版本 16.17.0 或更高),然后运行:npm install -g wrangler - 配置 Wrangler 和 AI 绑定
- 运行以下命令登录 Cloudflare:
wrangler login - 创建或编辑
wrangler.toml文件,添加以下配置:name = "whisper-cloudflare" compatibility_flags = ["nodejs_compat"] [ai] binding = "AI" - 如果不使用 Wrangler,可在 Cloudflare 仪表板的 Worker 设置中手动绑定 AI 模型(选择
@cf/openai/whisper-large-v3-turbo)。
- 运行以下命令登录 Cloudflare:
- 部署 Worker
- 在 Workers 编辑器中,点击“部署”按钮,直接发布代码。
- 或通过 Wrangler 运行:
wrangler deploy - 部署成功后,Cloudflare 会提供一个 Worker URL(例如 https://whispercloudflare.tchepai.com/)。
- 准备音频文件
确保音频为 MP3 或 WAV 格式,文件大小不超过 25MB(受 Cloudflare Workers 限制)。音频文件需以二进制形式上传,或通过公开 URL 访问(例如上传至云存储)。
主要功能操作流程
语音转文字
Whisper_Cloudflare 使用 Whisper 模型将音频转换为文本。操作步骤如下:
- 上传音频:通过 POST 请求发送音频二进制数据到
/raw接口。例如:curl -X POST "https://whisper.ohen5pbf93.workers.dev/raw" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - 获取结果:返回 JSON 格式的转录结果,包含文本和时间戳:
{ "response": { "text": "这是一个测试音频。", "segments": [ {"text": "这是一个", "start": 0.0, "end": 1.2}, {"text": "测试音频", "start": 1.3, "end": 2.5} ] } } - 处理大文件:若音频超过 25MB,需手动分割为小块(建议每块 1MB),逐块上传并合并结果。
字幕生成
生成 SRT 格式字幕文件,适用于视频或播客。操作步骤:
- 请求字幕:发送音频到
/srt接口:curl -X POST "https://whispercloudflare.tchepai.com/srt" \ -H "Content-Type: application/octet-stream" \ --data-binary "@audio.mp3" - 获取结果:返回 SRT 格式文件,例如:
1 00:00:00,000 --> 00:00:01,200 这是一个 2 00:00:01,300 --> 00:00:02,500 测试音频
Web 界面使用
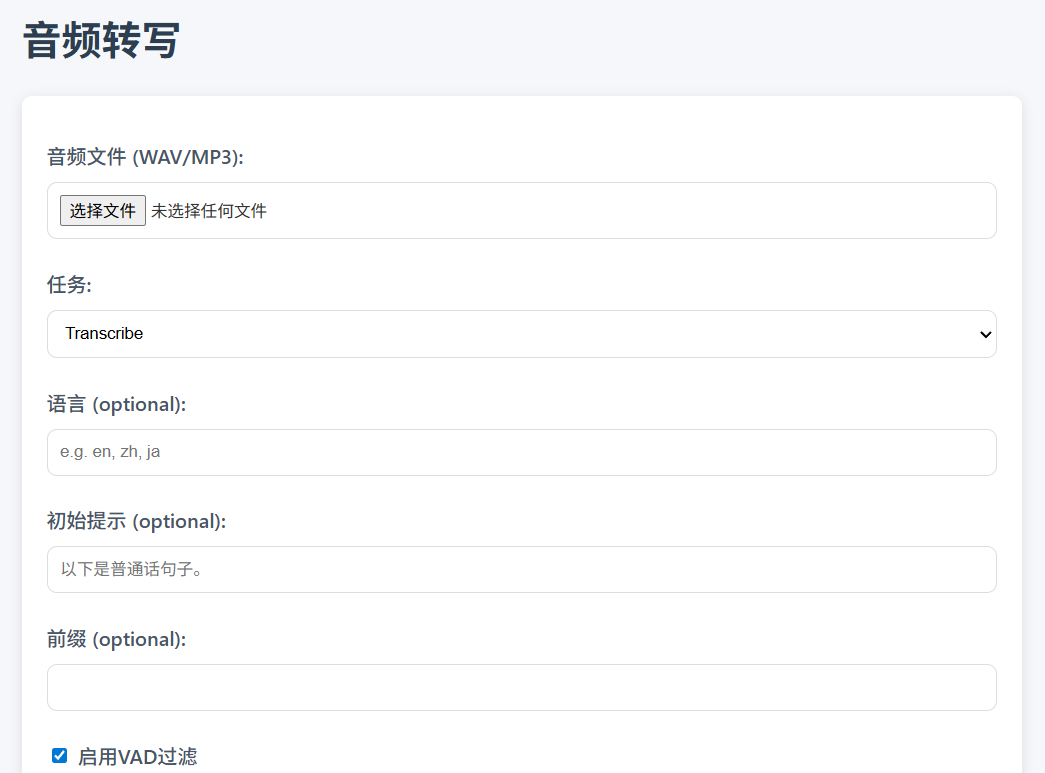
worker.js 提供一个内置 HTML 界面(访问 Worker URL 的根路径 /),用户可通过浏览器操作:
- 访问界面:打开 Worker URL(例如 https://whispercloudflare.tchepai.com/)。
- 上传音频:选择 MP3 或 WAV 文件,设置任务类型(转写或翻译)、语言、VAD 过滤等参数。
- 获取结果:提交后,界面显示 SRT 字幕,并支持下载为
.srt文件。 - 注意:界面支持进度条显示,处理 41 分钟音频约需 1.9 分钟。
API 使用
项目提供两个 API 接口:
/raw:返回 JSON 格式的原始转录数据,适合开发者进一步处理。/srt:返回 SRT 格式字幕文件,直接用于视频编辑。
示例 JavaScript 调用:
const response = await fetch('https://whispercloudflare.tchepai.com/srt', {
method: 'POST',
headers: { 'Content-Type': 'application/octet-stream' },
body: audioFile // 音频二进制数据
});
const srt = await response.text();
console.log(srt); // 输出 SRT 字幕
上下文优化
使用 initial_prompt 或 prefix 参数提供上下文,提升转录准确性。例如:
curl -X POST "https://whispercloudflare.tchepai.com/raw?initial_prompt=技术会议" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
语音活动检测(VAD)
启用 VAD 过滤(vad_filter=true)可去除非语音部分:
curl -X POST "https://whispercloudflare.tchepai.com/raw?vad_filter=true" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
翻译功能
设置 task=translate 和 language 参数,将音频翻译为指定语言。例如:
curl -X POST "https://whispercloudflare.tchepai.com/raw?task=translate&language=en" \
-H "Content-Type: application/octet-stream" \
--data-binary "@audio.mp3"
性能与限制
- 速度:测试显示,处理 41 分钟 39 秒的音频仅需 1.9 分钟。
- 限制:Cloudflare Workers 的资源限制可能导致偶尔失败,建议重试。
- 文件大小:单次请求音频不超过 25MB。
注意事项
- API 安全:在 Cloudflare 仪表板中配置 AI 绑定,勿泄露 API 令牌。
- 错误处理:若请求失败,等待几秒后重试。
- 浏览器兼容性:Web 界面在现代浏览器(如 Chrome、Firefox)上运行良好。
应用场景
- 会议记录转录
上传会议音频,生成文本或 SRT 字幕,适合多语言会议整理。 - 播客字幕生成
播客制作者生成 SRT 字幕,提升内容可访问性和搜索优化。 - 教育资源转录
教师或学生上传课堂录音,生成笔记或字幕,方便复习。 - 语音应用开发
开发者集成 API,构建实时字幕或语音助手,适合轻量级项目。
QA
- 支持哪些音频格式?
支持 MP3、WAV 等格式,建议使用高质量音频。 - 如何处理大文件?
手动分割为 1MB 小块,逐块上传并合并结果。 - 部署需要付费吗?
Cloudflare Workers 免费计划支持部署,AI 模型每日有 10,000 免费神经元,超出按每 1000 神经元 $0.011 计费。 - 如何优化转录?
使用initial_prompt、prefix或vad_filter参数提升准确性。 - 支持哪些语言?
支持英语、中文、日语等多种语言,具体代码参考 Whisper 文档。






























