



ShareGPT-4o-Image 是一个由 FreedomIntelligence 团队在 GitHub 上开源的大型多模态图像生成数据集,包含 91K 个高质量样本,基于 GPT-4o 的图像生成能力构建。数据集分为 45K 个文本到图像样本和 46K 个文本加图像到图像样本,旨在帮助开源多模态模型对齐 GPT-4o 的图像生成能力。团队还基于此数据集开发了 Janus-4o 模型,支持文本到图像和图像编辑功能,性能优于前代 Janus-Pro。该项目致力于通过开源数据和模型,推动多模态人工智能的社区发展,提供高质量资源用于研究和开发。
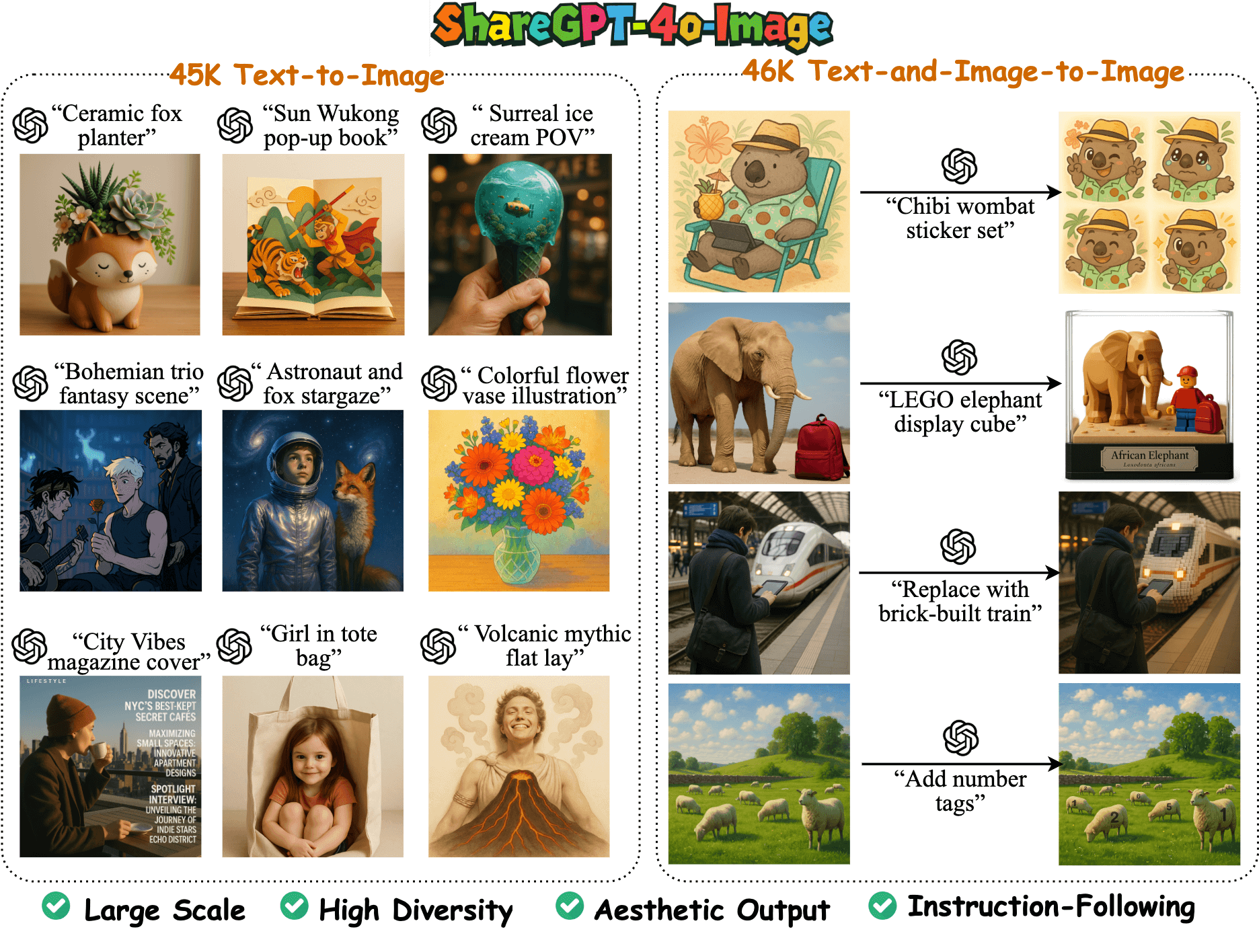
功能列表
- 提供 91K 个高质量图像生成样本,包含 45K 文本到图像和 46K 文本加图像到图像样本。
- 支持开源多模态模型的训练和优化,提升图像生成和编辑能力。
- 包含 Janus-4o 模型,支持文本到图像生成和文本加图像到图像的编辑功能。
- 数据集在 Hugging Face 上可下载,格式为 Parquet 文件,大小约 20.7 MB,包含 92,256 行数据。
- 提供详细的文档和代码示例,支持开发者快速上手使用数据集和模型。
- 开源代码和模型托管在 GitHub 和 Hugging Face,方便社区贡献和扩展。
使用帮助
数据集获取与安装
ShareGPT-4o-Image 数据集可在 Hugging Face 或 GitHub 上免费获取。以下是具体步骤:
- 访问数据集:
- 打开 Hugging Face 页面:https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image。
- 或者访问 GitHub 仓库:https://github.com/FreedomIntelligence/ShareGPT-4o-Image。
- 数据集以 Parquet 格式存储,大小约 20.7 MB,包含 92,256 行数据。
- 下载数据集:
- 在 Hugging Face 页面,点击“Download”按钮,直接下载 Parquet 文件。
- 或者使用 Git 命令克隆 GitHub 仓库:
git clone https://github.com/FreedomIntelligence/ShareGPT-4o-Image.git - 下载后,解压文件(如果需要),确保 Parquet 文件可被 Python 环境读取。
- 环境准备:
- 安装 Python 3.7 或以上版本。
- 安装必要的依赖库,例如
pandas和datasets,以加载和处理 Parquet 文件:pip install pandas datasets - 如果使用 Janus-4o 模型,需安装
torch和transformers:pip install torch transformers
- 加载数据集:
- 使用 Python 的
datasets库加载数据集:from datasets import load_dataset dataset = load_dataset("FreedomIntelligence/ShareGPT-4o-Image") print(dataset) - 数据集包含文本提示和生成图像的对应关系,可直接用于模型训练或分析。
- 使用 Python 的
使用 Janus-4o 模型
Janus-4o 是一个基于 ShareGPT-4o-Image 数据集微调的多模态模型,支持文本到图像生成和图像编辑。以下是具体操作步骤:
- 加载模型:
- 从 Hugging Face 下载 Janus-4o-7B 模型:
from transformers import AutoModelForCausalLM, VLChatProcessor model_path = "FreedomIntelligence/Janus-4o-7B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda().eval() - 确保你的设备支持 GPU 并安装了 CUDA,否则可使用 CPU(性能较慢)。[](https://huggingface.co/FreedomIntelligence/Janus-4o-7B)
- 从 Hugging Face 下载 Janus-4o-7B 模型:
- 文本到图像生成:
- 使用提供的
text_to_image_generate函数生成图像:def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5): torch.cuda.empty_cache() conversation = [{"role": "<|User|>", "content": input_prompt}, {"role": "<|Assistant|>", "content": ""}] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts( conversations=conversation, sft_format=vl_chat_processor.sft_format, system_prompt="" ) prompt = sft_format + vl_chat_processor.image_start_tag # 后续生成步骤参考 GitHub 文档 - 输入示例提示如:“一张夕阳下的海滩,沙滩上有椰子树,远处有帆船”。
- 生成的图像将保存到指定
output_path。
- 使用提供的
- 文本加图像到图像编辑:
- Janus-4o 支持基于输入图像和文本提示进行图像编辑。例如,输入一张风景图和提示“将天空替换为星空”。
- 操作流程与文本到图像类似,但需额外提供图像路径,具体代码参考 GitHub 仓库中的示例。
- 查看文档:
- 访问 GitHub 仓库的 README 文件,获取详细的模型参数和生成设置说明。
- Hugging Face 页面也提供数据集结构和样本预览,便于理解数据格式。
注意事项
- 数据集和模型需要稳定的网络环境下载。
- 使用 GPU 加速模型推理,推荐至少 16GB 显存。
- 如果遇到模型加载或生成问题,可参考 GitHub Issues 页面或提交问题反馈。
- 数据集和模型均为开源,社区鼓励贡献代码或改进数据集。
应用场景
- 多模态模型开发
开发者可以使用 ShareGPT-4o-Image 数据集训练或微调自己的多模态模型,提升文本到图像生成或图像编辑能力,适用于生成艺术作品、设计草图等场景。 - 学术研究
研究人员可利用数据集分析 GPT-4o 的图像生成模式,探索多模态模型的语义对齐和生成质量,适合人工智能、计算机视觉领域的学术研究。 - 创意内容生成
设计师或内容创作者可以使用 Janus-4o 模型,根据文本描述快速生成高质量图像,或对现有图像进行风格化编辑,应用于广告、游戏或影视制作。 - 教育与教学
教师和学生可利用数据集和模型进行 AI 课程实验,学习多模态模型的工作原理,实践文本到图像生成和图像编辑任务。
QA
- ShareGPT-4o-Image 数据集是免费的吗?
是的,数据集完全开源,可在 Hugging Face 和 GitHub 免费下载和使用,遵循 Apache-2.0 许可证。 - Janus-4o 模型与 GPT-4o 相比如何?
Janus-4o 是基于 ShareGPT-4o-Image 数据集微调的开源模型,支持文本到图像和图像编辑,但在整体性能上仍略逊于 GPT-4o。 - 需要什么硬件运行 Janus-4o?
推荐使用支持 CUDA 的 GPU(至少 16GB 显存)以获得最佳性能,CPU 也可以运行但速度较慢。 - 如何贡献到项目?
可以在 GitHub 仓库提交 Pull Request,贡献代码、优化模型或补充数据集,具体指引见仓库的贡献指南。































