

在构建基于检索增强生成(RAG)的知识库应用时,文档的预处理和切片(Chunking)是决定最终检索效果的关键一步。开源 RAG 引擎 RAGFlow 提供了多种切片策略,但其官方文档在方法细节和具体案例上缺乏清晰说明,给开发者带来诸多困惑。
本文通过一系列的基准测试,旨在深入剖析 RAGFlow 中不同切片方法的工作机制与核心差异。测试将围绕以下几个常见问题展开:
- 文档的章节目录在切片时如何处理?会作为独立的块,还是与正文合并?
- 嵌入在正文中的图片,在切片时会如何归属?
MANUAL、BOOK、LAWS等切片方法的具体切分依据是什么?TABLE方法在按行切片时,如何确保每行数据都保留表头信息?QA切片方法是否可以被TABLE方法替代?
RAGFlow 的切片方法可以大致分为以下几类:
- 通用方法 (
General): 覆盖所有文件类型,基于“长度+分隔符”进行切分,适用性广,但精度较低。 - 文档结构化方法 (
MANUAL,BOOK,LAWS): 针对具有清晰层级结构的文档(如 DOCX、PDF),依据其目录或特定标记进行切片。 - 表格结构化方法 (
TABLE,QA): 针对表格数据(如 XLSX),按行或特定列进行处理。 - 特定场景方法 (
ONE,RESUME,PAPER,PRESENTATION): 为单一文档、简历、论文和演示文稿等特殊用途设计。
本次分析将重点聚焦于最常用且最易混淆的“文档结构化方法”和“表格结构化方法”。
按文档结构切片:MANUAL、BOOK、LAWS
这三种方法都适用于处理结构化文档,但其切片逻辑和粒度各不相同。为了直观对比,测试选用“中华人民共和国税收征收管理法.docx”作为样本,该文档包含清晰的章节结构。
原始文档结构截取如下:

MANUAL 方法:基于“标题”样式
MANUAL 方法严格依据 Word 或 PDF 中定义的“标题”样式(如 Heading 1, Heading 2)来分割文档。它会切分到最细粒度的标题层级。值得注意的是,仅有“样式”被识别为标题的文本才会触发切分,普通加粗或放大字体的文本(如文中的“第十五条”、“第十六条”)会被视为正文。
测试文档使用 MANUAL 方法的切片结果如下图所示:

分析结果显示,文档共被切分为 6 个块(Chunk)。每个内容块都会完整地继承其所有上级目录的标题,直至文档的根标题。例如,”第二章 税务管理” 下的内容块,会包含“中华人民共和国税收征收管理法”和“第二章 税务管理”两个标题。
如果顶级标题下存在直接附属的正文内容,这部分内容也会被单独切分为一个块。

BOOK 方法:基于“目录+段落”
BOOK 方法采用一种更深度的语义切分策略。它首先按章节目录分割,然后对每个章节内的正文内容进一步按语义(子主题或段落)进行切分。这使得 BOOK 方法的切片粒度在三者中最细。
使用 BOOK 方法处理同一文档,结果如下:
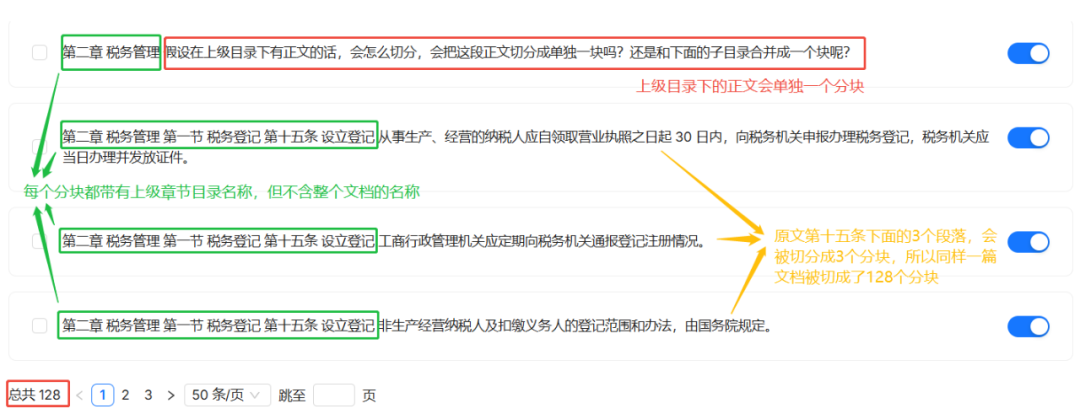
与 MANUAL 方法的核心区别在于,“第十五条”下的三个段落被精细地切分成了 3 个独立的块。整个文档最终被切分为 128 个块。
在上下文继承方面,BOOK 方法的每个块同样会包含其上级目录标题,但与 MANUAL 不同,它不包含文档的顶级标题。这种设计可能更适合在检索中聚焦于具体的章节内容,而非整个文档的背景。
LAWS 方法:基于“章节条款”标记
LAWS 方法专为法律或规定类文档设计,它通过正则表达式识别“第 X 章”、“第 X 条”等特定标记进行切分,而忽略文本的“标题”样式或目录层级。
使用 LAWS 方法处理该文档,切片结果为 87 个块。

LAWS 方法的特点如下:
- 识别标记: 即便“第十五条”、“第十六条”在文档中是普通正文样式,但因其符合“条款”标记,仍被成功切分。
- 段落处理: 与
BOOK不同,LAWS不会对条款下的多个段落进行再切分,而是将其合并在同一个块中。 - 上下文处理:
LAWS的上下文处理方式非常独特。它不会将上级目录标题直接嵌入到每个条款块中,而是将各层级的目录标题汇总成一个独立的块(如上图绿色线框所示),实现内容与目录索引的分离。
三种文档切片方法对比总结
基于以上测试,可将三种方法的特性总结如下:
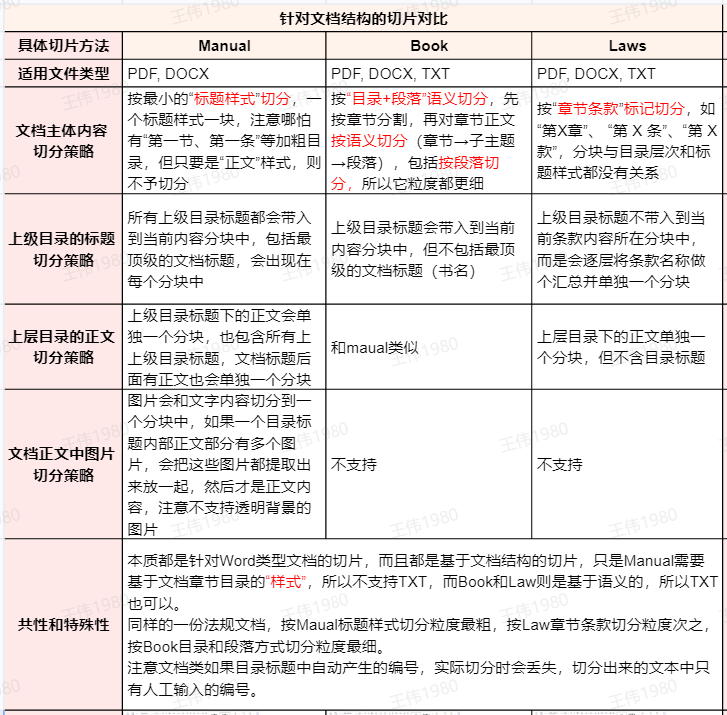
值得补充的是,MANUAL 方法的适用场景非常明确,即产品手册、技术文档等具有标准“标题”样式层级的文件。而 LAWS 专攻法律法规、政策文件。BOOK 则凭借其段落级的细粒度切分,更适合需要进行深度语义理解和问答的长篇报告或书籍。
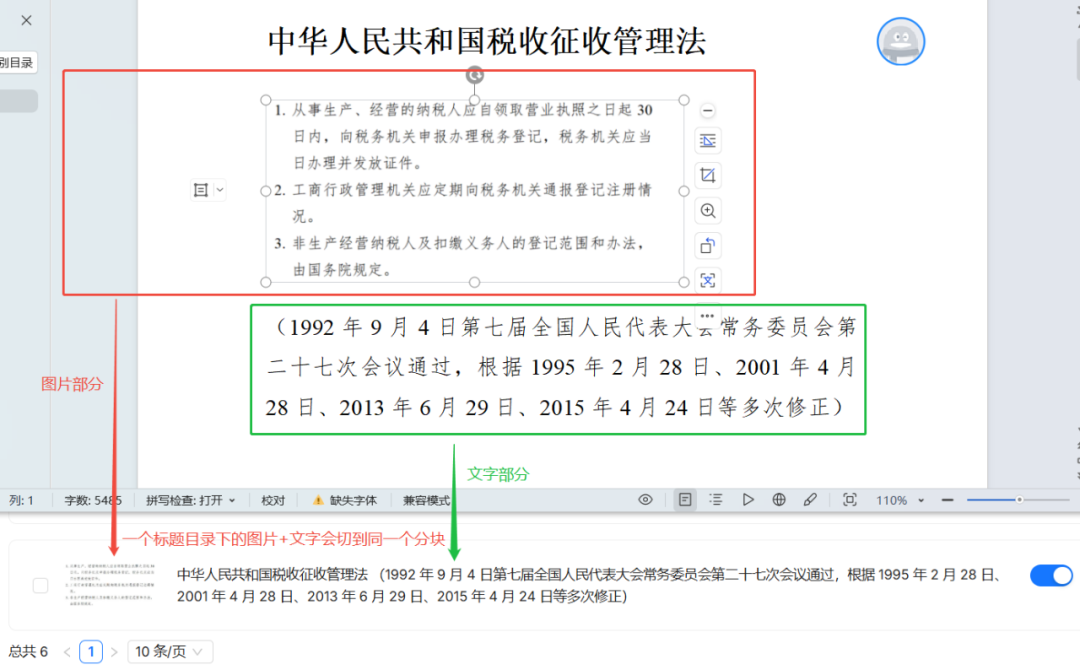
此外,测试发现 MANUAL 方法能够将文档中的图片与其相邻的文本内容切分到同一个块中,这对于图文并茂的文档处理非常有用。
按表格结构切片:TABLE、QA
接下来,我们转向对表格类数据(如 Excel 文件)的切片方法进行验证。
TABLE 方法
测试使用一个包含产品、地区、业务域、问题描述、原因和解决方案等字段的运维知识表格。
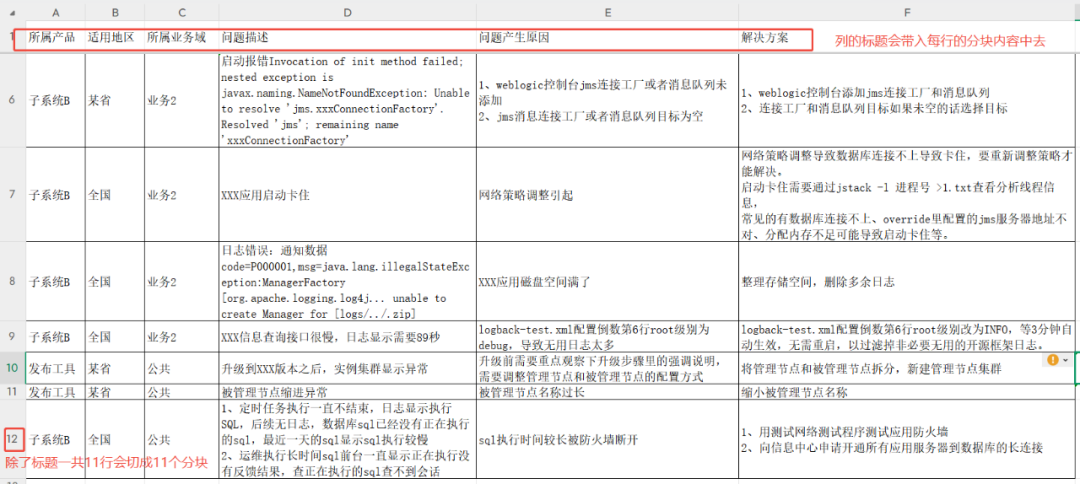
使用 TABLE 方法切片时,RAGFlow 会将表格的第一行识别为列标题(Header)。在处理时,它会逐行切片(标题行除外),并将列标题信息完整地添加到每一行的内容块中,形成“Key: Value”的格式。
切片结果如下,每一行都成为了一个独立的、包含完整上下文信息的知识块:

QA 方法
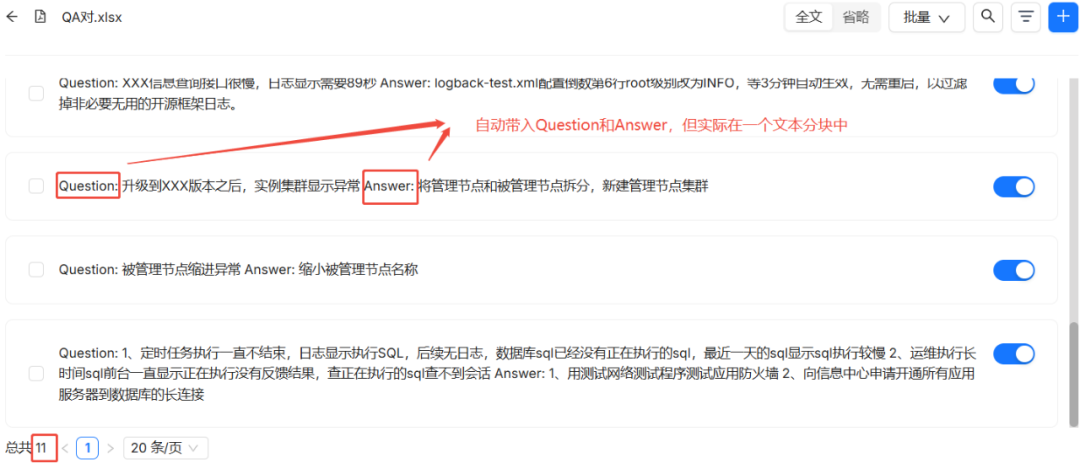
QA 方法是一种特殊用途的表格切片,它默认将表格的前两列识别为“Question”和“Answer”。如果直接用上一个运维知识表格进行测试,RAGFlow 会仅提取“所属产品”和“适用地区”两列,忽略其余所有信息。
为了准确测试,我们准备一个仅包含“问题描述”和“解决方案”两列的标准 QA 格式表格。
经过 QA 方法切片后,每一行同样被切分为一个块,并自动添加“Question:”和“Answer:”作为前缀。
两种表格切片方法对比总结
深入分析可以发现,QA 方法本质上是 TABLE 方法的一种简化特例。用户完全可以通过 TABLE 方法实现 QA 的效果,只需将表格的两列命名为“Question”和“Answer”即可。
在实际应用中,如果知识库需要基于问题描述、原因、解决方案等多维度信息进行语义检索,TABLE 方法是更优选择。如果检索场景严格限定于“问-答”对,并且希望利用产品、地区等信息进行精确过滤,那么更理想的架构是:使用 QA 方法对问答内容进行切片,同时将产品、地区等信息存入块的元数据(Metadata)中。
然而,在 RAGFlow 的测试中发现,其系统设计仅支持文档(Document)层级的元数据,而不支持更细粒度的块(Chunk)层级元数据。并且其检索 API 中似乎也缺少基于元数据进行过滤的直接参数。这在构建复杂的 RAG 系统时是一个显著的局限,也是驱动团队考虑自研知识库底座的原因之一。
其他特殊切片方法
RAGFlow 还提供了一些针对特定场景的切片方法:
- One: 不进行任何切片,将整个文档作为一个单独的块。
- Resume: 针对简历进行结构化解析,提取关键信息。
- Paper: 针对论文格式,提取摘要、作者和章节等。
- Presentation: 针对 PPT 或由 PPT 转换的 PDF,将每一页转换为一个独立的块,包含页面截图和提取的文本内容。
PRESENTATION 方法的测试效果如下:
超越切片:RAG 工程化的深度考量
尽管 RAGFlow 提供了丰富的切片工具,但一个生产级的 RAG 系统远不止于此。选择自研知识库解决方案,通常是基于更深层次的工程化需求:
- 自定义切片逻辑: 业务场景往往需要高度定制化的切片规则,例如针对代码仓库、数据字典或特定格式的内部知识,这是预置方法难以覆盖的。
- 精细化的元数据管理: 正如前文所述,为每个知识块附加丰富的元数据(如版本、来源、负责人、业务标签)并支持高效过滤,是实现精准检索、聚焦范围、提升效率的核心。
- 知识库的版本控制与生命周期管理: 生产环境中的知识库需要具备完善的工作流。知识在新增或更新时,必须经过测试和验证,确保其不影响线上服务的稳定性与准确性,最终才能安全发布。
- 知识的提炼与增强: RAG 系统还需要对原始知识进行处理,例如生成摘要、构建知识图谱关系、添加同义词扩展等,并记录这些衍生知识与原始知识的关联,以便在源头变更时进行有效的追踪和同步。
这些复杂的工程化挑战,共同构成了从一个基础 RAG 原型走向一个可靠、可维护的企业级知识服务的必经之路。


































