

no rastro de wan2.1 Com o surgimento de modelos de vídeo, como a geração de vídeo localizado, o ecossistema de tecnologia para geração de vídeo localizado está amadurecendo gradualmente. No passado, o hardware de alto desempenho era o principal obstáculo para a criação de fluxos de trabalho de vídeo, mas, com a popularidade dos recursos de computação em nuvem e o desenvolvimento de técnicas de otimização de modelos, até mesmo os usuários sem placas de vídeo de primeira linha agora podem alugar placas de vídeo em nuvem. 4090 Placas gráficas e outras formas de aprender e explorar em profundidade wan2.1 Fluxo de trabalho de vídeo.
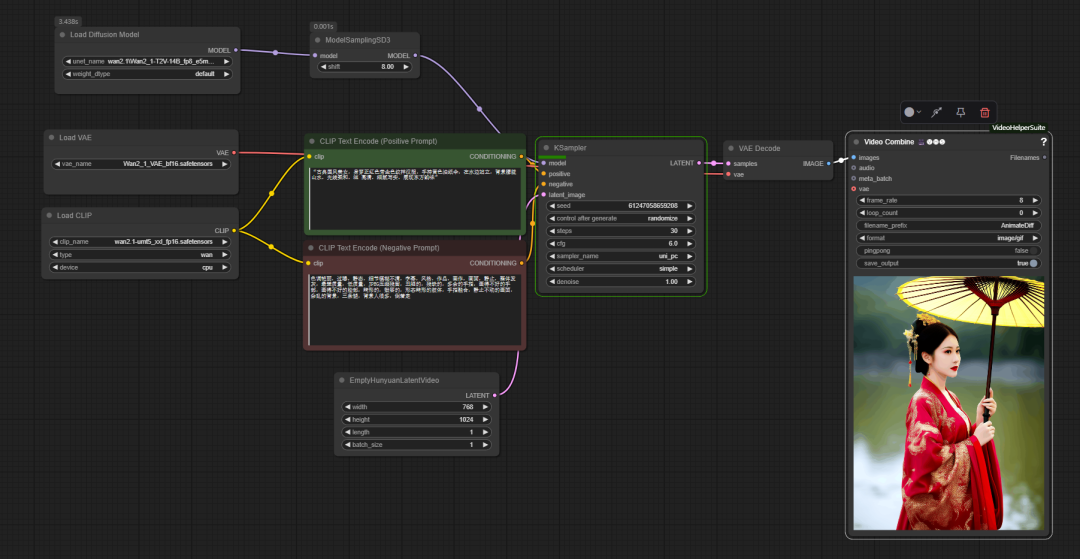
在 ComfyUI no fluxo de trabalho de base oficial dowan2.1 é usado de forma semelhante ao processo tradicional do diagrama de Vincennes, mas com a adição de um nó-chave model sampling sd3. Esse nó é usado para ajustar o UNet Esse parâmetro afeta a capacidade do modelo de entender e controlar as palavras-chave, otimizando assim os detalhes da imagem gerada.
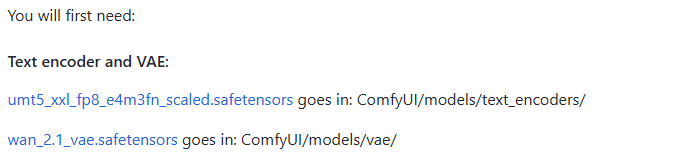
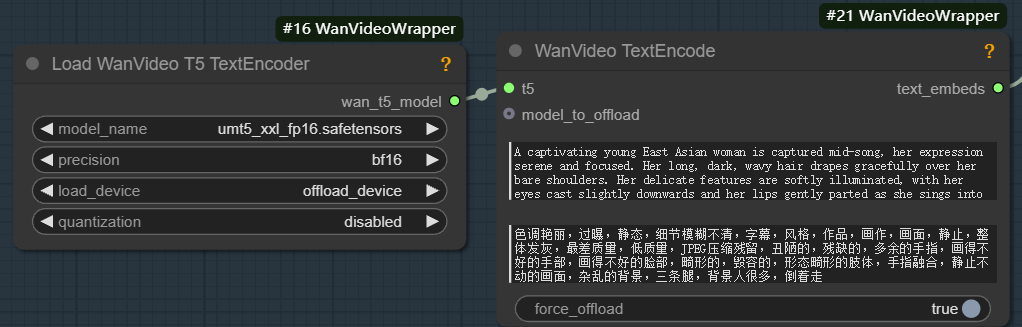
Para executar wan2.1 que deve ser equipado com o modelo correspondente unmt5 Codificador de texto e wan2.1 VAE (Variable Auto-Encoder, codificador automático variável): o VAE consiste em duas partes, codificador e decodificador. O codificador é responsável pela compactação da imagem de entrada em um espaço potencial de baixa dimensão, enquanto o decodificador faz a amostragem do espaço potencial e o reduz a uma imagem.
A função do codificador de texto é transformar as dicas de texto de entrada em vetores de recursos que possam ser compreendidos pelo modelo. Esse processo consiste em duas etapas principais:
- Extraia características de informações semânticas do texto, por exemplo, "1 garota".
- As informações semânticas são transformadas em um vetor de incorporação de alta dimensão.
Com base nesses vetores de incorporação, os modelos generativos (por exemplo, UNet) geram recursos de imagem no espaço latente que correspondem às descrições textuais, determinando assim o tipo, a posição, a cor e a pose dos objetos no quadro.
Diferentemente do fluxo de trabalho do diagrama de Venn estático, a etapa final do processo de geração de vídeo é a Video Combine (composição de vídeo).
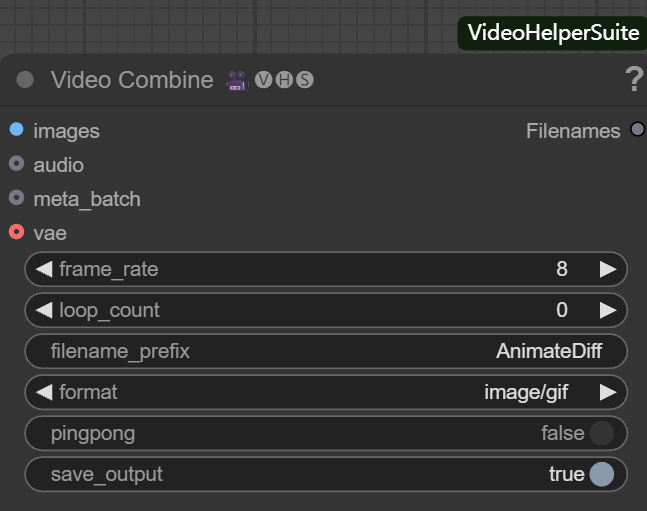
Esse nó é responsável por retificar as sequências de imagens em arquivos de vídeo ou de imagem em movimento. Seus principais parâmetros incluem:
- frame_rate. Determina a suavidade da reprodução de vídeo, por exemplo, definida como
8Isso significa que são reproduzidos 8 quadros por segundo. - loop_count.
0Representa um loop infinito, aplicável a GIFs;1Então, isso significa tocar uma vez e depois parar. - filename_prefix (prefixo do nome do arquivo). Defina um prefixo para o arquivo de saída, por exemplo
AnimateDiffO programa é fácil de gerenciar. - formato. selecionável
image/gifproduz uma imagem em movimento, ouvideo/mp4e outros formatos de vídeo. - pingpong (ida e volta).
falsepara reprodução sequencial regular.trueEm seguida, é realizada uma reprodução de ida e volta do início ao fim e de volta ao início. - save_output. definido como
trueQuando o nó é executado, o arquivo é salvo automaticamente após a execução do nó.
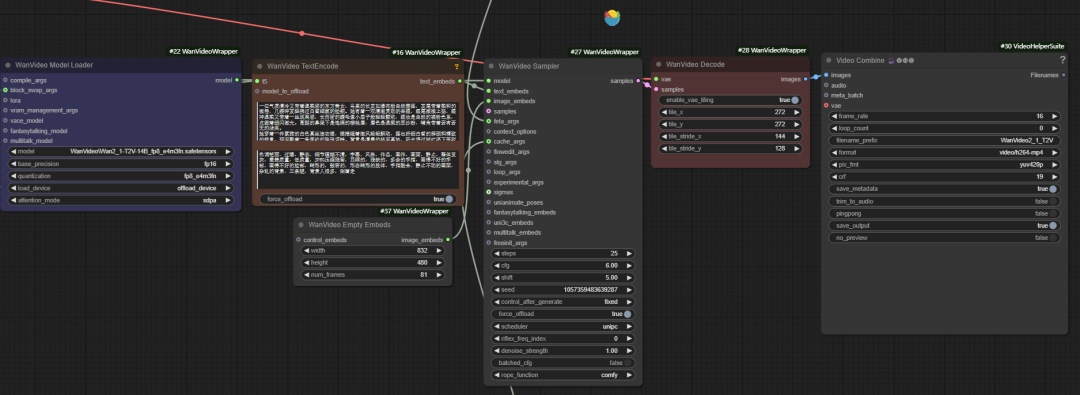
O fluxo de trabalho oficial implementa apenas a funcionalidade básica e tem limitações em termos de otimização de memória, aprimoramento de vídeo e assim por diante. Por esse motivo, o desenvolvedor "K-God" criou o wanvideo wrapper que fornece uma variedade de nós de otimização.
O coração da otimização: wanvideo wrapper
wanvideo model loader
wanvideo model loader é um nó de carregamento de modelo avançado que não apenas carrega o wanvideo e também oferece uma grande variedade de opções de otimização.
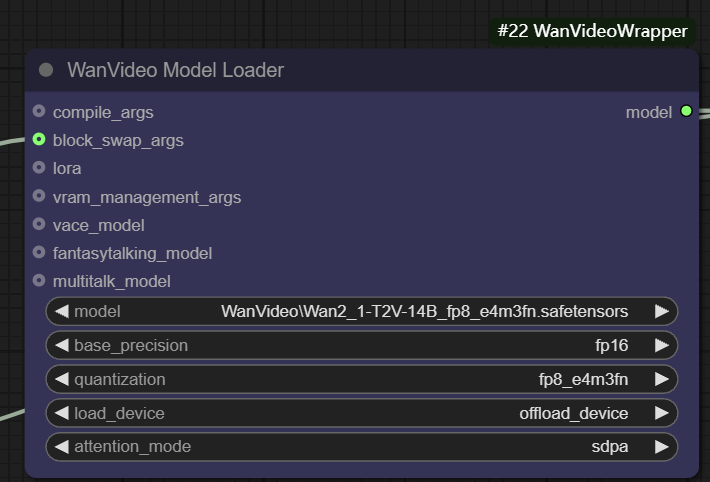
- Precisão de base. O usuário pode selecionar diferentes precisões de modelo, como
fp32、bf16、fp16。fp32(ponto flutuante de 32 bits) Maior precisão, mas maior espaço de memória e sobrecarga computacional;fp16(ponto flutuante de 16 bits) pode reduzir significativamente o uso da memória e aumentar a velocidade, mas pode sacrificar um pouco a precisão. - Quantificação. aprovar (um projeto de lei ou inspeção etc.)
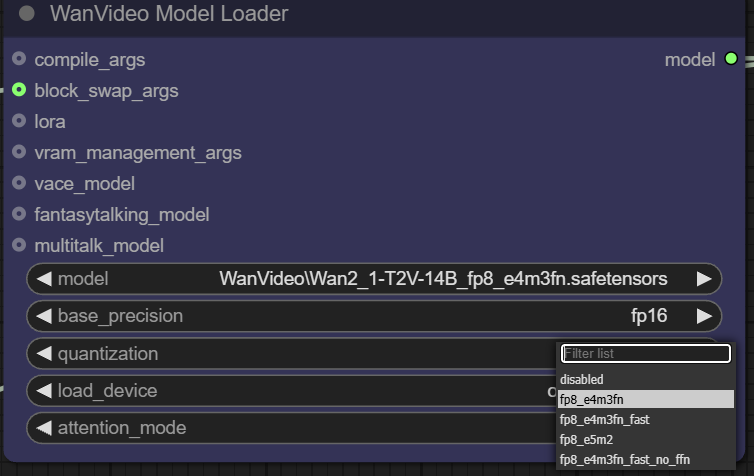
quantizationo modelo pode ser quantificado para compressão adicional. Por exemplo, a opçãofp8_e4m3fnO formato usa uma representação de ponto flutuante de 8 bits, o que reduz bastante os requisitos de memória e é particularmente adequado para dispositivos com memória de vídeo limitada, mas geralmente exige que o modelo tenha uma quantificação pré-suportada.
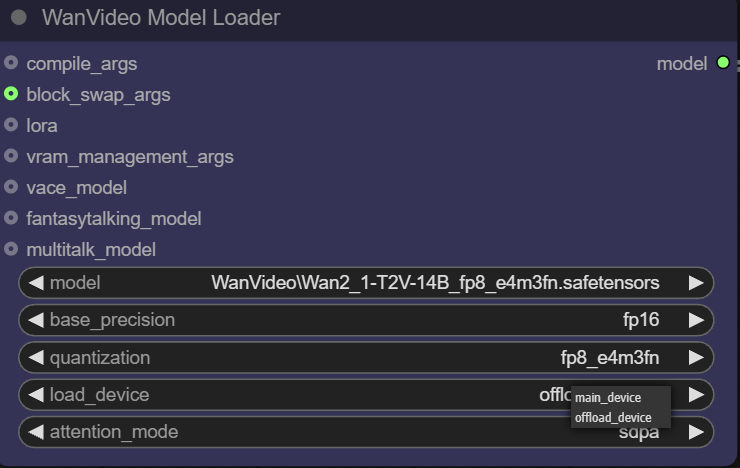
- Dispositivo de carga.
main devicegeralmente se refere à GPU, enquantooffload deviceEssa função permite transferir alguns componentes do modelo para a CPU para economizar recursos valiosos da memória de vídeo.
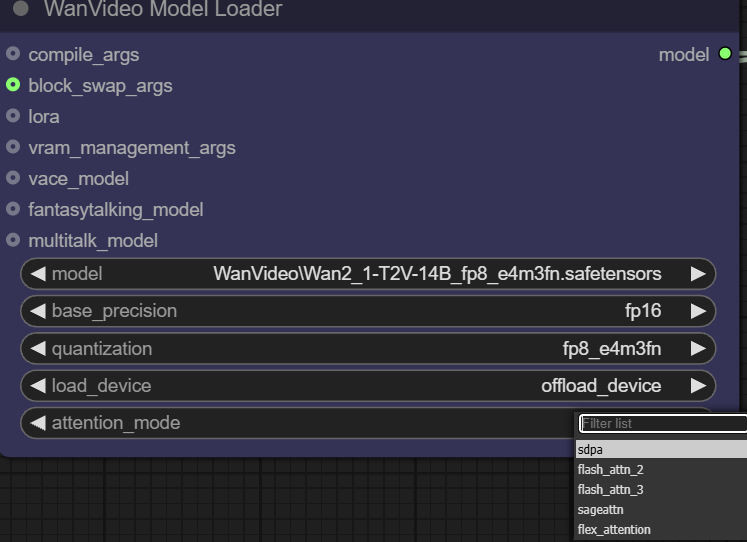
- Modo de atenção. Essa opção permite que o usuário escolha uma implementação diferente do mecanismo de atenção para equilibrar o desempenho e a memória. O mecanismo de atenção está no centro do modelo Transformer e determina como o modelo "se concentra" nas partes relevantes das informações de entrada ao gerar conteúdo.
O carregador também oferece várias interfaces de entrada para otimização avançada:
- compilar args. Essa interface pode ser usada para configurar
torch.compile或xformerse outras otimizações de compilação.xformersé uma ferramenta especializada para otimizar Transformer para computação, e a bibliotecatorch.compileé o compilador on-the-fly introduzido no PyTorch 2.0. Se você tiver oTritoné possível obter um aumento de velocidade de cerca de 301 TP3T.
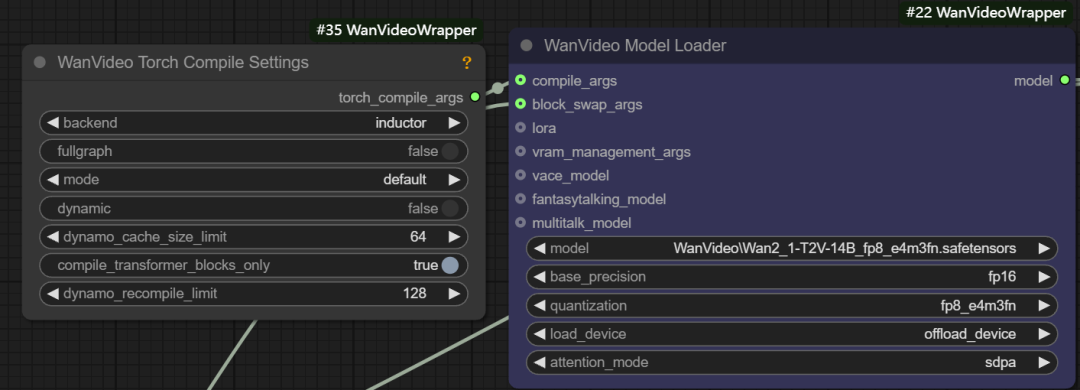
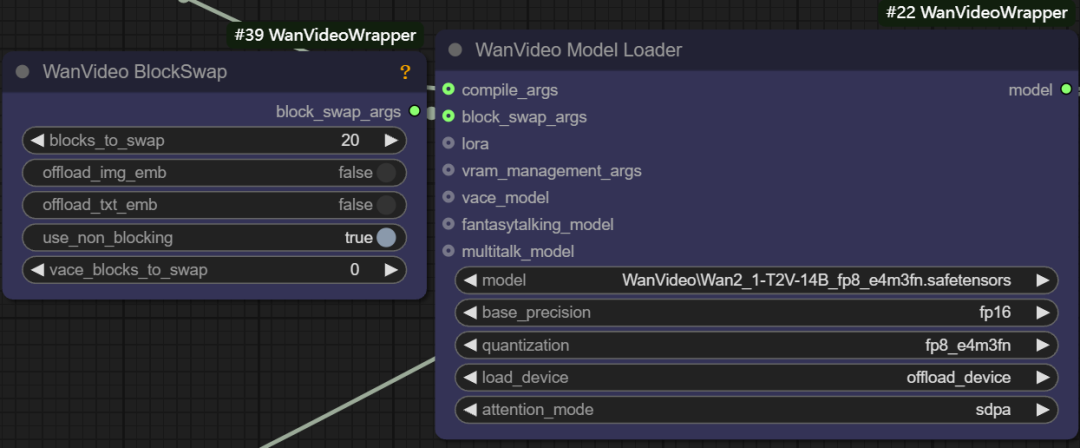
- Args de troca de bloco. Essa função permite armazenar temporariamente alguns "blocos" do modelo na CPU quando não há memória suficiente para armazenar todo o modelo, por exemplo, definindo o parâmetro
blocks to swapé 20, o que significa que 20 blocos do modelo são movidos para fora da GPU e passados de volta por meio de não bloqueio quando necessário. Quanto mais blocos forem movidos, mais significativa será a economia de memória, mas uma certa quantidade de velocidade de geração é sacrificada pela transferência de dados para frente e para trás.
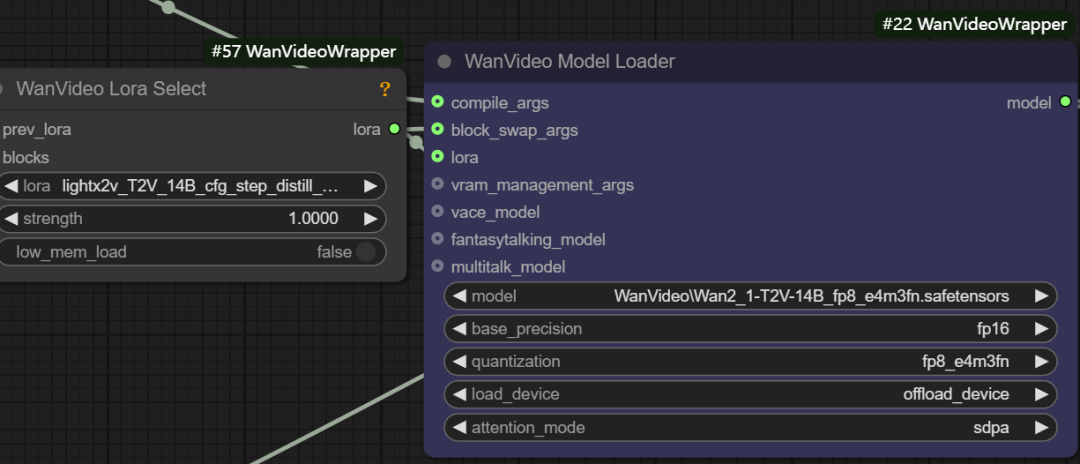
- Carregamento de LoRA. Essa interface pode ser conectada a
wanvideo lora selectnós para carregar vários tipos de modelos LoRA, por exemplo, para acelerar o vídeo Vincenneslight x2v t2vLoRA.
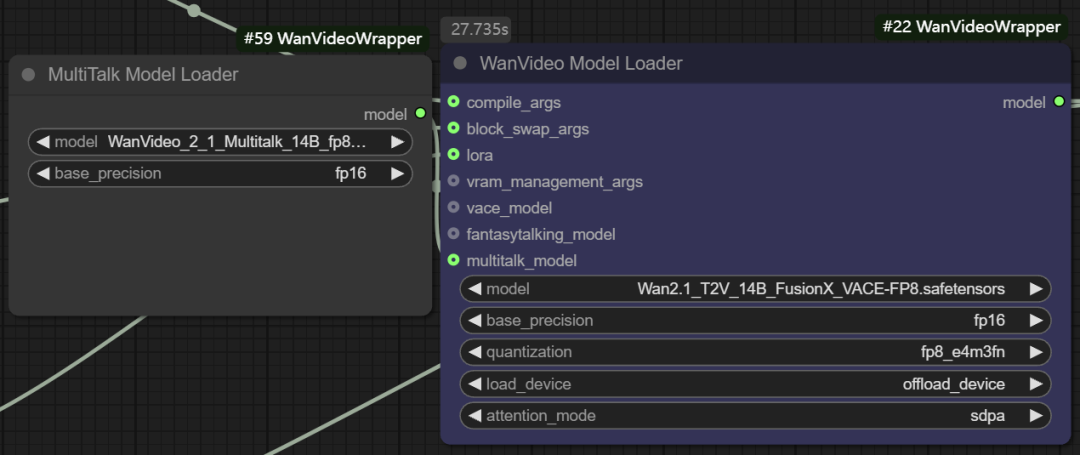
- Modelagem funcional multitalk. O nó também suporta o carregamento de
Multitalk、Fantasytalkinge outros modelos humanos digitais, que são integrados pelo desenvolvedor aowanvideo wrapperde projetos emergentes de código aberto.
wanvideo sampler
wanvideo sampler é baseado em wan2.1 Modele nós de amostragem de vídeo personalizados que são fundamentais para gerar quadros de sequência de vídeo.
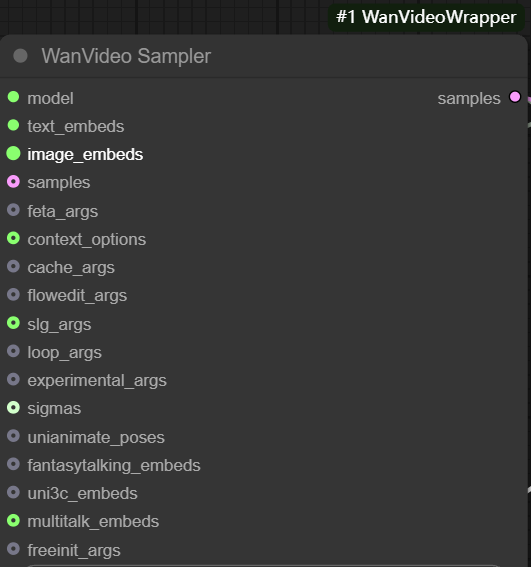
Suas principais entradas incluem:
- model: conexão de
wanvideo model loaderO modelo. - incorpora texto. rejunte
wanvideo text encodeque usará a saídaunmt5O vetor de texto codificado é passado.
- incorporações de imagens. Usado para ativar a geração de imagem para vídeo. Esse fluxo de trabalho geralmente começa com a função
wanvideo clipvision encodeExtraia o mapa de referência doCLIPe, em seguida, por meio dowanvideo image to video encodeOs nós usam o VAE para codificar os recursos da imagem em uma representação vetorial utilizável pelo modelo.
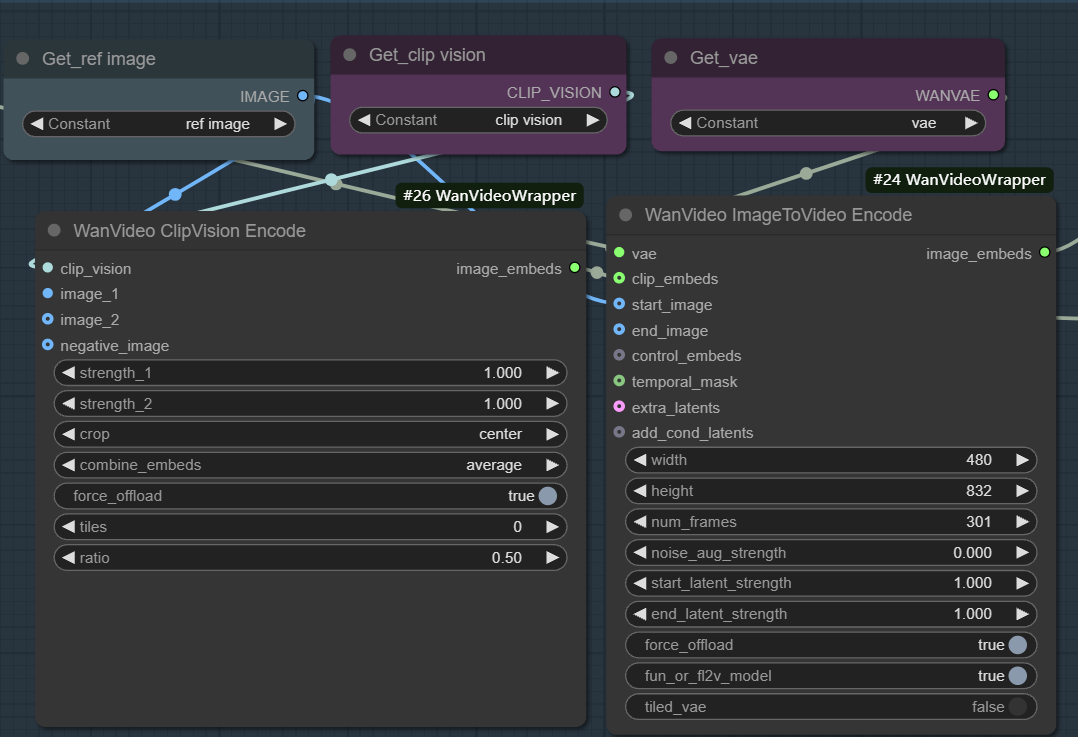
A essência desse processo é que as informações visuais e semânticas de uma imagem estática são primeiro transformadas em vetores de recursos e, em seguida, o amostrador usa esses recursos como uma condição de bootstrap para a redução iterativa de ruído, gerando quadros de vídeo consecutivos cujo conteúdo e estilo são consistentes com o mapa de referência. Ao ajustar parâmetros como pesos, ruído e número de quadros, a influência do mapa de referência e a diversidade do vídeo podem ser controladas com precisão.
- samples: Teoricamente, essa entrada poderia receber os resultados da amostragem do estágio anterior como ponto de partida para a iteração de difusão, mas sua
latentFormatação e gráficos padrão de VincenneslatentIncompatibilidade. - feta args: Usado para conectar nós de aprimoramento de vídeo para melhorar os detalhes do vídeo, o alinhamento de quadros e a estabilidade de tempo.
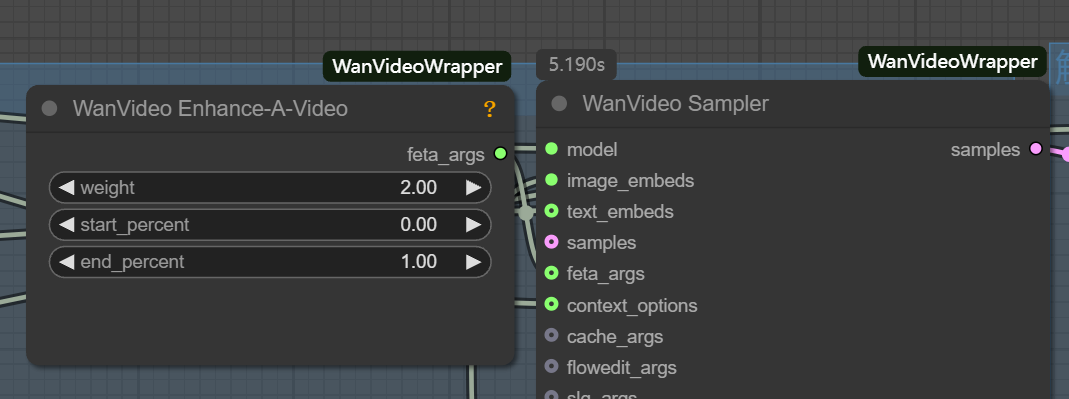
- wanvideo context options: Esse é o principal controlador para garantir a coerência entre os quadros de vídeo. Ele resolve o problema de quadros desconectados e movimentos não naturais causados pela geração independente de quadros, controlando a forma como o modelo se refere às informações contextuais ao gerar o quadro atual.
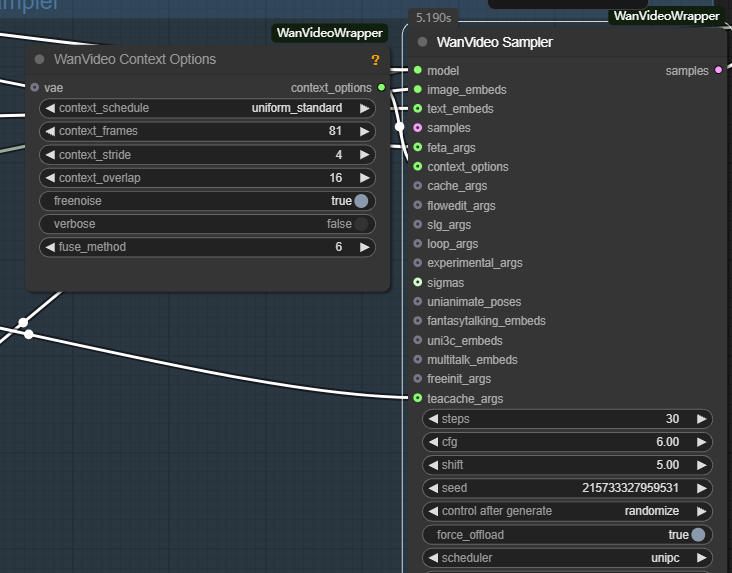
Os principais parâmetros são os seguintes:
- context_frames. Define o número de quadros vizinhos que o modelo referencia de uma só vez. Quanto maior o valor, melhor será a coerência das mudanças de movimento e de cena, mas o esforço computacional aumenta proporcionalmente.
- context_stride (etapa do contexto). Controla o intervalo entre os quadros de referência amostrados. Quanto menor for o tamanho da etapa, mais densa será a referência e mais suave será a transição de detalhes; quanto maior for o tamanho da etapa, mais eficiente será o cálculo.
- context_overlap. Define o número de quadros sobrepostos entre janelas de referência vizinhas. Uma sobreposição maior garante transições mais suaves entre os quadros e evita mudanças abruptas ao alternar entre as janelas.
O potencial da modelagem de vídeo no campo dos diagramas de Venn
Vale a pena mencionar que ele wan2.1 Definir a taxa de quadros de saída do fluxo de trabalho como 1 o torna uma ferramenta avançada de geração de texto, ainda melhor do que o Flux e outros modelos de imagem especializados. Os modelos de vídeo podem ter uma compreensão superior da estrutura interna e dos detalhes de uma imagem devido ao processamento adicional da dimensão temporal. Isso indica que os modelos de vídeo podem se tornar uma força importante no campo da geração de imagens estáticas no futuro.





























