


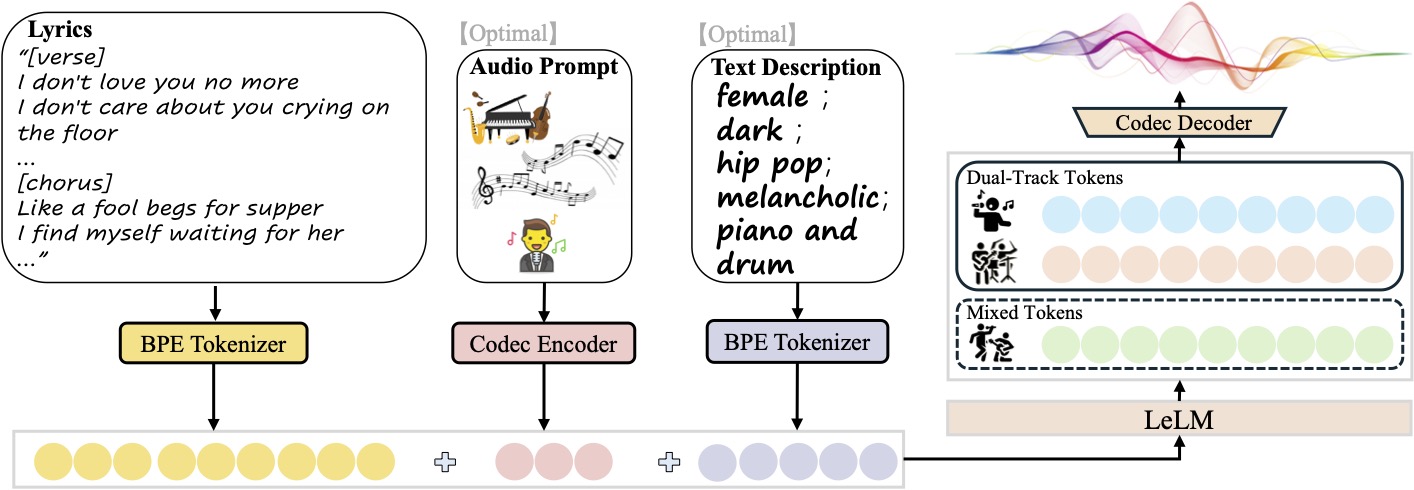
O SongGeneration é um modelo de geração de música desenvolvido e de código aberto pelo Tencent AI Lab, com foco na geração de músicas de alta qualidade, incluindo letras, acompanhamento e vocais. Ele se baseia na estrutura LeVo, combina o modelo de linguagem LeLM e codecs de música e oferece suporte à geração de músicas em chinês e inglês. O modelo é treinado em milhões de conjuntos de dados de músicas e pode gerar músicas com excelente qualidade de som e estrutura completa, adequadas para composição musical, trilha sonora de vídeo e outros cenários. Os usuários podem gerar músicas personalizadas controlando o estilo, a emoção e o ritmo da música por meio de descrições textuais ou áudio de referência. A natureza de código aberto do SongGeneration o torna acessível a desenvolvedores, entusiastas da música e criadores de conteúdo, e seu suporte para execução em dispositivos com pouca memória reduz a barreira ao uso.
Lista de funções
- Geração de músicasGeração de músicas completas com vocais e faixas de apoio com base nas letras e descrições de texto inseridas.
- Saída multipistaGeração separada de música pura, vocais puros ou faixas vocais e de apoio separadas para facilitar a pós-edição.
- Controle de estiloPersonalização de estilos musicais com descrições textuais (por exemplo, gênero, timbre, gênero, emoção, instrumento, batida).
- Áudio de referênciaO modelo pode ser carregado com um clipe de áudio de 10 segundos, e o modelo pode gerar uma nova música no mesmo estilo.
- Otimização de pouca memóriaSuporte à operação com apenas 10 GB de memória da GPU para uma ampla variedade de dispositivos.
- Suporte a código abertoPesos do modelo, scripts de inferência e arquivos de configuração são fornecidos e podem ser modificados e otimizados livremente pelo desenvolvedor.
Usando a Ajuda
Processo de instalação
Para usar o SongGeneration, você precisa configurar seu ambiente e instalar o modelo. Aqui estão as etapas, com base no repositório oficial do GitHub para Linux (os usuários do Windows podem consultar o seguinte) ComfyUI (Versão):
- Criando um ambiente Python
Com o Python 3.8.12 ou posterior, é recomendável que você crie um ambiente virtual por meio do conda:conda create -n songgeneration python=3.8.12 conda activate songgeneration - Instalação de dependências
Instale as dependências necessárias, incluindo PyTorch e FFmpeg:yum install ffmpeg pip install -r requirements.txt --no-deps --extra-index-url https://download.pytorch.org/whl/cu118 - Instalar o Flash Attention (opcional)
Para acelerar a inferência, instale o Flash Attention (requer CUDA 11.8 ou superior):wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl -P /home/ pip install /home/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whlSe a GPU não for compatível com o Flash Attention, você poderá adicionar uma inferência ao
--not_use_flash_attnParâmetros. - Download dos pesos do modelo
Faça o download dos pesos e perfis do modelo da Hugging Face e certifique-se de que ockpt和third_partyA pasta é salva em sua totalidade no diretório raiz do projeto:git clone https://github.com/tencent-ailab/SongGeneration cd SongGenerationVisite o repositório do Hugging Face (
https://huggingface.co/tencent/SongGeneration) Downloadsonggeneration_base_zhou outras versões dos pesos do modelo. - Instalação do Docker (opcional)
Para simplificar a configuração, podem ser usadas imagens oficiais do Docker:docker pull juhayna/song-generation-levo:hf0613 docker run -it --gpus all --network=host juhayna/song-generation-levo:hf0613 /bin/bash
Uso
O SongGeneration é compatível com a geração de músicas por meio de linha de comando ou script; a operação principal é preparar o arquivo de entrada e executar o script de inferência. Abaixo está o fluxo de operação detalhado:
- Preparação do arquivo de entrada
O arquivo de entrada deve ser JSON Lines (.jsonl), cada linha representa uma solicitação gerada e contém os seguintes campos:idxNome do arquivo: O nome do arquivo (identificador exclusivo) do áudio gerado.gt_lyric: letras no formato[结构] 歌词文本Por exemplo[Verse] 这是第一段歌词。. As estruturas suportadas incluem[intro-short]、[verse]、[chorus]etc., com referência específica aconf/vocab.yaml。descriptions(opcional): descreve os atributos da música, comofemale, pop, sad, piano, the bpm is 125。prompt_audio_path(Opcional): caminho de áudio de referência de 10 segundos para imitação de estilo.
exemplo típico
lyrics.jsonl:{"idx": "song1", "gt_lyric": "[intro-short]\n[verse] 这些逝去的回忆。我们无法抹去泪水。\n[chorus] 像傻瓜乞求晚餐。我在等待她的归来。", "descriptions": "female, pop, sad, piano, the bpm is 125"} - Execução de scripts de inferência
Use o script padrão para gerar músicas:sh generate.sh <ckpt_path> <lyrics.jsonl> <output_path><ckpt_path>Caminhos de peso do modelo.<lyrics.jsonl>Digite o caminho do arquivo.<output_path>Caminho de salvamento do áudio de saída.
Se a memória da GPU for insuficiente (<30 GB), use o modo de pouca memória:
sh generate_lowmem.sh <ckpt_path> <lyrics.jsonl> <output_path> - Opções de geração personalizadas
- Gerar música pura: adicione
--pure_musicLogotipo. - Gerar vocais puros: adicione
--pure_vocalLogotipo. - Vocais separados e faixas de apoio: adicione
--separate_trackspara gerar faixas vocais e de apoio separadas. - Desativar o Flash Atenção: Adicionar
--not_use_flash_attn。
- Gerar música pura: adicione
- Usuários do Windows (versão ComfyUI)
Os usuários do Windows podem usar a interface ComfyUI para simplificar as operações:- Clone o repositório de plug-ins do ComfyUI:
cd ComfyUI/custom_nodes git clone https://github.com/smthemex/ComfyUI_SongGeneration.git - montagem
fairseq(recomenda-se o uso de arquivos wheel pré-compilados no Windows):pip install liyaodev/fairseq - Coloque os pesos do modelo no
ComfyUI/models/SongGeneration/Catálogo. - Carregue o modelo por meio da interface ComfyUI, insira a letra e a descrição e clique no botão Generate (Gerar).
- Clone o repositório de plug-ins do ComfyUI:
Precauções de manuseio
- prompt de entradaEvite o fornecimento simultâneo de
prompt_audio_path和descriptionsCaso contrário, a qualidade da geração pode ser prejudicada devido a conflitos. - Formato das letrasA letra precisa ser estruturada em seções (por exemplo
[verse]、[chorus]), segmentos não-líricos (como[intro-short]) não deve conter letras. - Áudio de referênciaRecomenda-se usar o refrão da música (10 segundos ou menos) para otimizar a musicalidade.
- Requisitos de hardware: 10 GB de memória da GPU para o modelo básico e 16 GB com áudio de referência.
cenário do aplicativo
- composição musical
Os músicos podem inserir letras e descrições de estilo para gerar rapidamente demos de músicas e economizar tempo. Por exemplo, digite "Male Vocal, Jazz, Piano, 110 BPM" para gerar uma música no estilo jazz. - Trilha sonora do vídeo
Os criadores de vídeos podem carregar 10 segundos de áudio de referência para gerar uma trilha sonora estilizada para vídeos curtos, comerciais ou trilhas sonoras de filmes. - desenvolvimento de jogos
Os desenvolvedores de jogos podem gerar músicas com várias faixas, ajustando os vocais e as faixas de apoio separadamente para se adequar a diferentes cenários de jogos, como batalhas ou histórias. - Educação e experimentação
Estudantes e pesquisadores podem usar o código-fonte aberto para estudar algoritmos de geração de música ou testar os efeitos da criação de música com IA na sala de aula.
QA
- Quais idiomas são compatíveis com o SongGeneration?
Atualmente, suporta a geração de músicas em chinês e inglês, o modelo é treinado em um conjunto de dados de milhões de músicas (incluindo músicas em chinês e inglês) e pode suportar mais idiomas no futuro. - Como faço para garantir a qualidade do som da música gerada?
Use os pesos oficiais do modelo e os codecs de música fornecidos e certifique-se de que a taxa de amostragem de áudio seja de 48 kHz. Evite usar letras muito curtas, pois o modelo será concluído automaticamente para garantir a integridade estrutural. - Qual é a quantidade de memória necessária para executar o modelo?
10 GB de memória da GPU para o modelo básico e 16 GB com áudio de referência. modo de baixa memória (generate_lowmem.sh) pode otimizar o uso da memória. - A música gerada comercialmente pode ser usada?
A licença do modelo (CC BY-NC 4.0) precisa ser verificada, o conteúdo gerado pode estar sujeito a restrições de direitos autorais e recomenda-se consultar um especialista jurídico antes do uso comercial.


























