

Com a evolução do paradigma da modelagem de big language e da prática de engenharia, surgiu uma série de aplicativos para inteligências projetadas para imitar o processo de pesquisa humana. Essas inteligências não são apenas ferramentas simples de perguntas e respostas, mas sistemas complexos capazes de planejar, executar, refletir e sintetizar informações de forma autônoma. Neste artigo, desconstruiremos o projeto arquitetônico e a implementação funcional de diferentes estruturas de corpos inteligentes baseadas em pesquisa, desde OpenAI Lançamento oficial DeepResearch O guia é uma fonte de ideias que analisa profundamente as diferenças intrínsecas e as filosofias de design de várias estruturas de código aberto convencionais, fornecendo uma referência sistemática e estratégica para desenvolvedores e usuários na escolha de ferramentas.
Estrutura do corpo de inteligência de pesquisa profunda de código aberto
Comparação de conceitos básicos
Atualmente, há várias estruturas de corpos inteligentes de uso geral no mercado (por exemplo Auto-GPT、AutoGen etc.) são capazes de realizar tarefas de pesquisa, mas este artigo se concentra em seis projetos de código aberto que foram otimizados com arquiteturas específicas para cenários de pesquisa profunda.
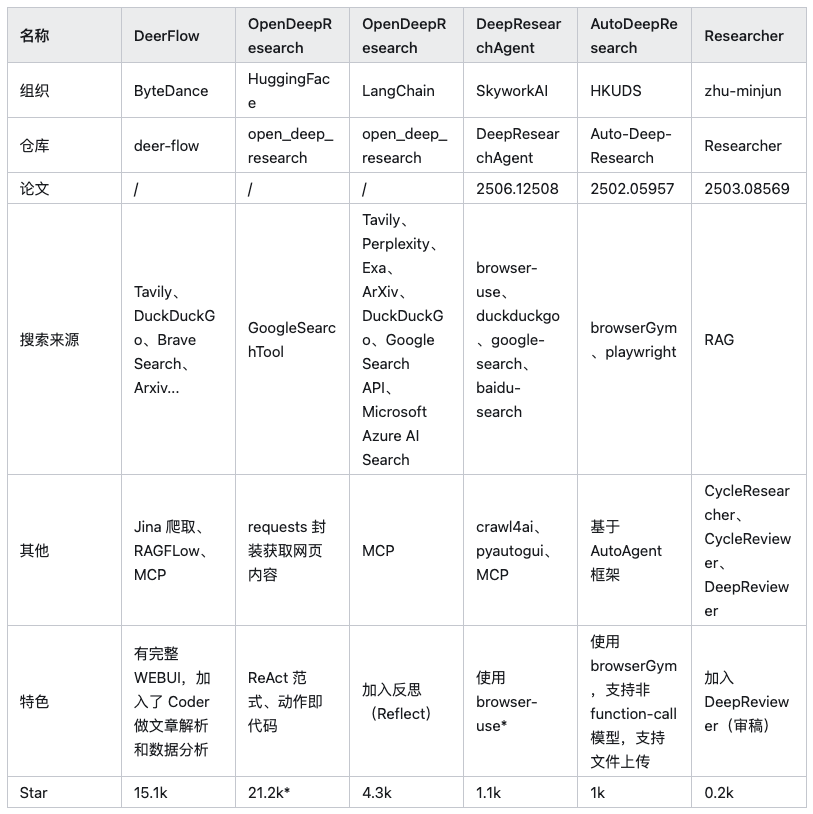
Observação: Na tabela acima HuggingFace/OpenDeepResearch O número de estrelas vem de sua dependência principal de SmolAgents Projeto.
Antes de analisar cada estrutura em profundidade, uma coisa precisa ficar clara: a essência da pesquisa aprofundada é a aquisição e a integração de informações. Sendo assim, algo como browser-use Essas ferramentas de automação de navegador orientadas por IA são um complemento importante para todas essas estruturas. Elas são responsáveis por executar tarefas como carregar páginas dinâmicas da Web, interagir com elementos da página, extrair dados etc., o que resolve o problema dos rastreadores tradicionais da Web que têm dificuldade em lidar com JavaScript O ponto problemático da renderização de conteúdo, mas não o ponto central da discussão deste artigo: a estrutura em si.
OpenAI Um guia: estabelecendo o paradigma de três etapas
OpenAI A documentação oficial do Deep Research No guia, ele propõe uma arquitetura que é a fonte de ideias para quase todas as inteligências subsequentes baseadas em pesquisas. Sua ideia central é abandonar a ilusão de resolver problemas em uma única etapa com um único e volumoso Prompt, que é extremamente frágil e difícil de depurar. O guia defende a divisão de tarefas de pesquisa complexas em três processos modulares separados:Planejar -> Executar -> SintetizarEssa é uma estratégia típica de "dividir e conquistar" para superar os desafios inerentes ao raciocínio de longo alcance e às restrições de comprimento de contexto em modelos de linguagem grandes. Essa é uma estratégia típica de "dividir e conquistar" que visa superar os desafios inerentes aos modelos de linguagem grandes em termos de raciocínio de longo alcance, consistência factual e restrições de comprimento de contexto.

- PlanoUse um modelo de ordem superior com um alto grau de abstração e raciocínio lógico (por exemplo, o
GPT-4o), divide o problema principal do usuário em uma série de subproblemas específicos, pesquisáveis de forma independente e exaustiva. A qualidade dessa etapa determina a amplitude e a profundidade da pesquisa. - ExecutarProcessamento: processa cada subproblema em paralelo. Para cada subproblema, uma API de pesquisa externa é chamada para obter informações e permitir que o modelo execute o resumo inicial e a extração de fatos de uma única fonte de informações. Essa é uma fase de coleta de informações altamente paralela.
- Síntese (Synthesize)Agregação das respostas a todas as subperguntas e entrega ao modelo de ordem superior para integração final, análise e embelezamento em um relatório final logicamente coerente e claramente estruturado.
Estratégias de implementação e práticas recomendadas
Com base nessa estrutura central, aqui estão algumas estratégias de prática importantes:
1. escolha do modelo certo para a tarefa certa
Esse é o cerne da otimização de custo e desempenho. Fases diferentes exigem tipos diferentes de "inteligência". As fases de "Planejamento" e "Síntese" requerem uma poderosaRaciocínio global, organização lógica e habilidades de geração criativaA seguir, um exemplo do tipo de dados que deve ser usado no GPT-4o 或 GPT-4 Turbo Esses são os principais modelos, pois seu desempenho determina o limite superior da qualidade do relatório final. Na fase de "execução", a tarefa de resumir páginas individuais da Web está mais concentrada emExtração de informações e enriquecimento de fatosUso GPT-3.5-Turbo ou outros modelos mais rápidos podem reduzir drasticamente o custo e a latência, mantendo a qualidade. Uma única solicitação de pesquisa profunda pode acionar dezenas de chamadas de API e, sem hierarquias de modelos, os custos podem aumentar rapidamente.
2. processamento paralelo para maximizar a eficiência
Os subproblemas do estudo geralmente são independentes uns dos outros, e o processamento em série consome muito tempo. Na fase de "execução", uma vez que a lista de subproblemas tenha sido gerada, ela deve ser programada de forma assíncrona (por exemplo, pelo Python 的 asyncio) para iniciar solicitações de pesquisa em paralelo. Isso pode reduzir um processo de vários minutos para menos de um minuto. No entanto, os desenvolvedores devem estar atentos aos limites de taxa dos fornecedores de API, especialmente o TPM (número de tokens processados por minuto). As chamadas paralelas podem gerar um grande número de solicitações instantaneamente, excedendo o limite de TPM As limitações resultarão em falhas nas solicitações, portanto, são necessárias filas de solicitações bem projetadas e mecanismos de repetição.
3. garantir a saída estruturada usando chamadas de função ou padrões JSON
Para garantir um fluxo de trabalho estável e confiável, os modelos devem sempre retornar dados estruturados legíveis por máquina, em vez de código de análise de texto de linguagem natural instável.OpenAI A melhor maneira de conseguir isso é por meio do recurso "Chamada de função" ou "Modo JSON". É o equivalente a uma chamada de função entre o código e o LLM Isso estabelece um contrato de API sólido. Na fase de planejamento, é possível forçar o modelo a gerar uma lista JSON de todas as cadeias de subproblemas e, na fase de execução, também é possível exigir que o modelo retorne os resultados em um formato JSON fixo, como {"summary": "...", "key_points": [...]}。
4. integração de ferramentas de pesquisa externas de alta qualidade
Os modelos de linguagem não têm inerentemente recursos de rede em tempo real e seu conhecimento sofre um atraso. Portanto, é importante integrar uma ou mais APIs de pesquisa de alta qualidade (como a Google Search API、Brave Search API、Serper etc.) para acessar informações abrangentes e em tempo real. Informar explicitamente ao modelo, na palavra-chave, que ele pode usar essas ferramentas e retornar os resultados das ferramentas ao modelo por meio de chamadas de função, etc., é a base para capacitá-lo com recursos de pesquisa.
5. elaboração de prompts para cada estágio (Prompt Engineering)
As palavras-chave são fundamentais para determinar a qualidade de cada estágio. As palavras-chave de cada estágio devem ser cuidadosamente elaboradas para orientar o modelo a desempenhar a função correta e produzir os resultados desejados. Os seguintes exemplos de entradas fornecidos no guia oficial são altamente informativos.
Pergunta inicial.
Research the economic impact of semaglutide on global healthcare systems.
Do:
- Include specific figures, trends, statistics, and measurable outcomes.
- Prioritize reliable, up-to-date sources: peer-reviewed research, health
organizations (e.g., WHO, CDC), regulatory agencies, or pharmaceutical
earnings reports.
- Include inline citations and return all source metadata.
Be analytical, avoid generalities, and ensure that each section supports
data-backed reasoning that could inform healthcare policy or financial modeling.
研究索马鲁肽对全球医疗保健系统的经济影响。
应做的:
- 包含具体的数字、趋势、统计数据和可衡量的成果。
- 优先考虑可靠、最新的来源:同行评审的研究、卫生组织(例如世界卫生组织、美国疾病控制与预防中心)、监管机构或制药公司
的盈利报告。
- 包含内联引用并返回所有来源元数据。
进行分析,避免泛泛而谈,并确保每个部分都支持
数据支持的推理,这些推理可以为医疗保健政策或财务模型提供参考。
Esclarecimento de dúvidas.
O objetivo dessa etapa é que o corpo inteligente atue como um verdadeiro consultor, certificando-se de que as intenções do usuário sejam totalmente compreendidas antes de iniciar uma pesquisa dispendiosa.
You are talking to a user who is asking for a research task to be conducted. Your job is to gather more information from the user to successfully complete the task.
GUIDELINES:
- Be concise while gathering all necessary information
- Make sure to gather all the information needed to carry out the research task in a concise, well-structured manner.
- Use bullet points or numbered lists if appropriate for clarity.
- Don't ask for unnecessary information, or information that the user has already provided.
IMPORTANT: Do NOT conduct any research yourself, just gather information that will be given to a researcher to conduct the research task.
您正在与一位请求开展研究任务的用户交谈。您的工作是从用户那里收集更多信息,以成功完成任务。
指导原则:
- 收集所有必要信息时务必简洁
- 确保以简洁、结构良好的方式收集完成研究任务所需的所有信息。
- 为清晰起见,请根据需要使用项目符号或编号列表。
- 请勿询问不必要的信息或用户已提供的信息。
重要提示:请勿自行进行任何研究,只需收集将提供给研究人员进行研究任务的信息即可。
Reescrita de prompts de usuário.
Essa etapa traduz a solicitação falada do usuário em uma instrução escrita detalhada e inequívoca para o Researcher Intelligence.
You will be given a research task by a user. Your job is to produce a set of
instructions for a researcher that will complete the task. Do NOT complete the
task yourself, just provide instructions on how to complete it.
GUIDELINES:
1. **Maximize Specificity and Detail**
- Include all known user preferences and explicitly list key attributes or
dimensions to consider.
- It is of utmost importance that all details from the user are included in
the instructions.
2. **Fill in Unstated But Necessary Dimensions as Open-Ended**
- If certain attributes are essential for a meaningful output but the user
has not provided them, explicitly state that they are open-ended or default
to no specific constraint.
3. **Avoid Unwarranted Assumptions**
- If the user has not provided a particular detail, do not invent one.
- Instead, state the lack of specification and guide the researcher to treat
it as flexible or accept all possible options.
4. **Use the First Person**
- Phrase the request from the perspective of the user.
5. **Tables**
- If you determine that including a table will help illustrate, organize, or
enhance the information in the research output, you must explicitly request
that the researcher provide them.
6. **Headers and Formatting**
- You should include the expected output format in the prompt.
- If the user is asking for content that would be best returned in a
structured format (e.g. a report, plan, etc.), ask the researcher to format
as a report with the appropriate headers and formatting that ensures clarity
and structure.
7. **Language**
- If the user input is in a language other than English, tell the researcher
to respond in this language, unless the user query explicitly asks for the
response in a different language.
8. **Sources**
- If specific sources should be prioritized, specify them in the prompt.
- For product and travel research, prefer linking directly to official or
primary websites...
- For academic or scientific queries, prefer linking directly to the original
paper or official journal publication...
- If the query is in a specific language, prioritize sources published in that
language.
6. introdução do Human-in-the-Loop (HIL) em pontos-chave.
Para tarefas de pesquisa sérias ou de alto risco, os processos totalmente automatizados não são confiáveis. A introdução de um "human-in-the-loop" não é apenas um recurso, mas uma filosofia de colaboração entre humanos e computadores. Uma prática eficaz é incluir um processo de revisão humana após a fase de "planejamento", em que o usuário revisa, modifica e valida a lista de subproblemas gerados pelo modelo para garantir que a direção da pesquisa esteja correta, antes de iniciar a dispendiosa fase de "execução". Isso evita o "entra lixo, sai lixo" e garante a responsabilidade pelos resultados finais.
Análise de arquitetura de código aberto
A seguir, dissecamos os recursos arquitetônicos de cada estrutura.
ByteDance/DeerFlowSistema de corpo multiinteligente hierárquico baseado em gráficos
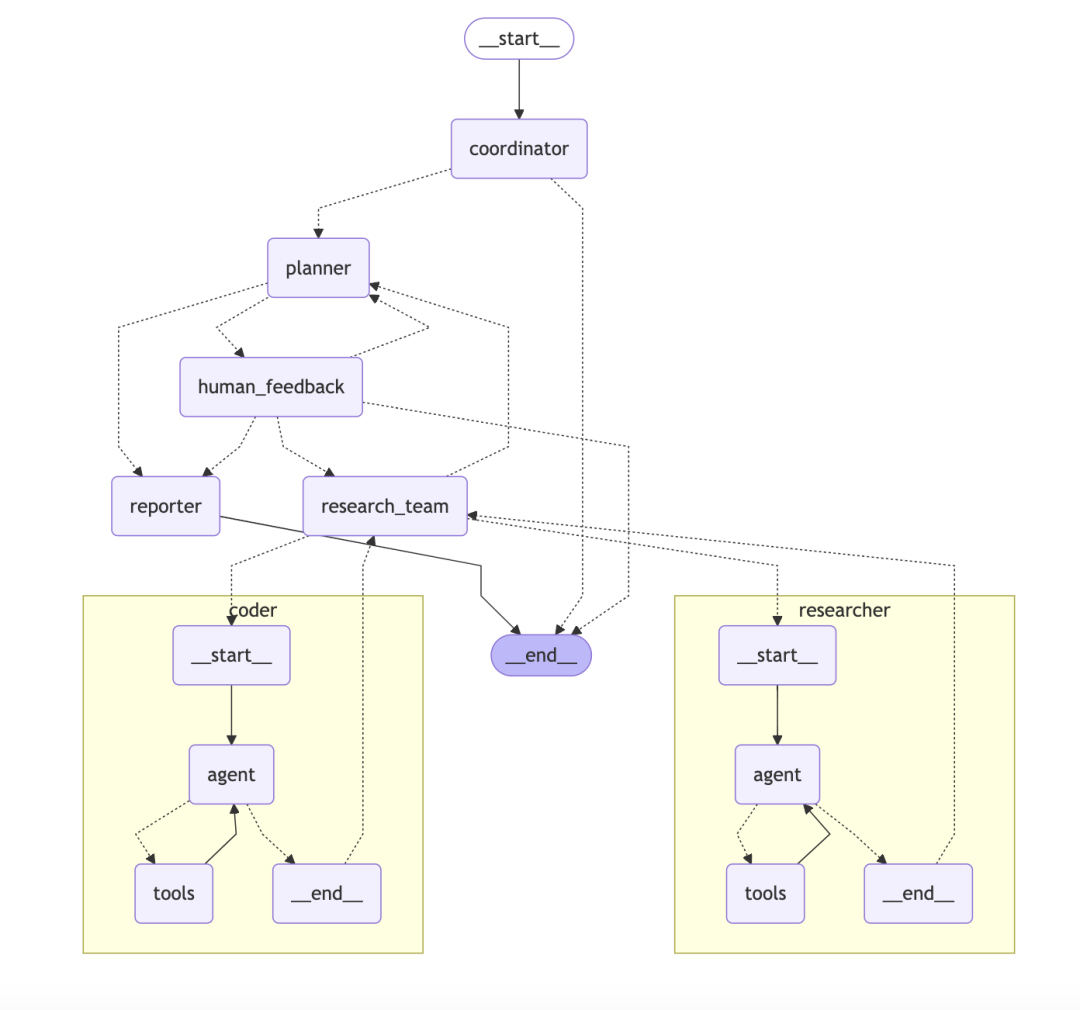
DeerFlow A arquitetura é um sistema corporal modular, hierárquico e multiinteligente, como uma equipe de pesquisa automatizada com objetivos claros e uma divisão de trabalho bem definida.
- arquitetura central:: O sistema consiste em várias funções trabalhando juntas:
- CoordenadorGerente de projeto: atuar como gerente de projeto, receber solicitações de usuários, iniciar e gerenciar o processo.
- PlanejadorComo estrategista, divida problemas complexos em etapas estruturadas.
- Equipe de pesquisa:: Como executor, há "pesquisadores" que pesquisam na Web e "programadores" que executam o código.
- RepórterComo resultado final, consolide todas as informações em relatórios, podcasts e até mesmo PPTs.
- Características técnicas:
DeerFlowO destaque tecnológico é que ele foi desenvolvido com base emLangChain和LangGraphAcima.LangGraphé um componente essencial que permite que os desenvolvedores criem fluxos de trabalho com vários inteligenciadores noGráficos com estadoCada inteligência ou ferramenta pode ser considerada como um nó no gráfico. Cada inteligência ou ferramenta pode ser considerada como um nó no gráfico, e a direção do fluxo de trabalho é definida pelas bordas. Essa abordagem suporta naturalmente processos complexos que incluem loops, como o loop Refletir-Corrigir, tornando todo o processo de pesquisa não apenas linear, mas também rastreável e depurável.
Comentário do colunista: DeerFlow O design é claro e bem definido para equipes ou aplicativos corporativos que precisam ser estáveis, dimensionáveis e suportar fluxos de trabalho complexos. Isso é feito com a introdução de LangGraphIsso eleva a colaboração inteligente do corpo, de simples chamadas em cadeia para uma rede gráfica cíclica e gerenciável que se assemelha mais a uma "plataforma de gerenciamento de processos de pesquisa" do que a uma simples ferramenta.
HuggingFace/OpenDeepResearchA filosofia minimalista do código como ação
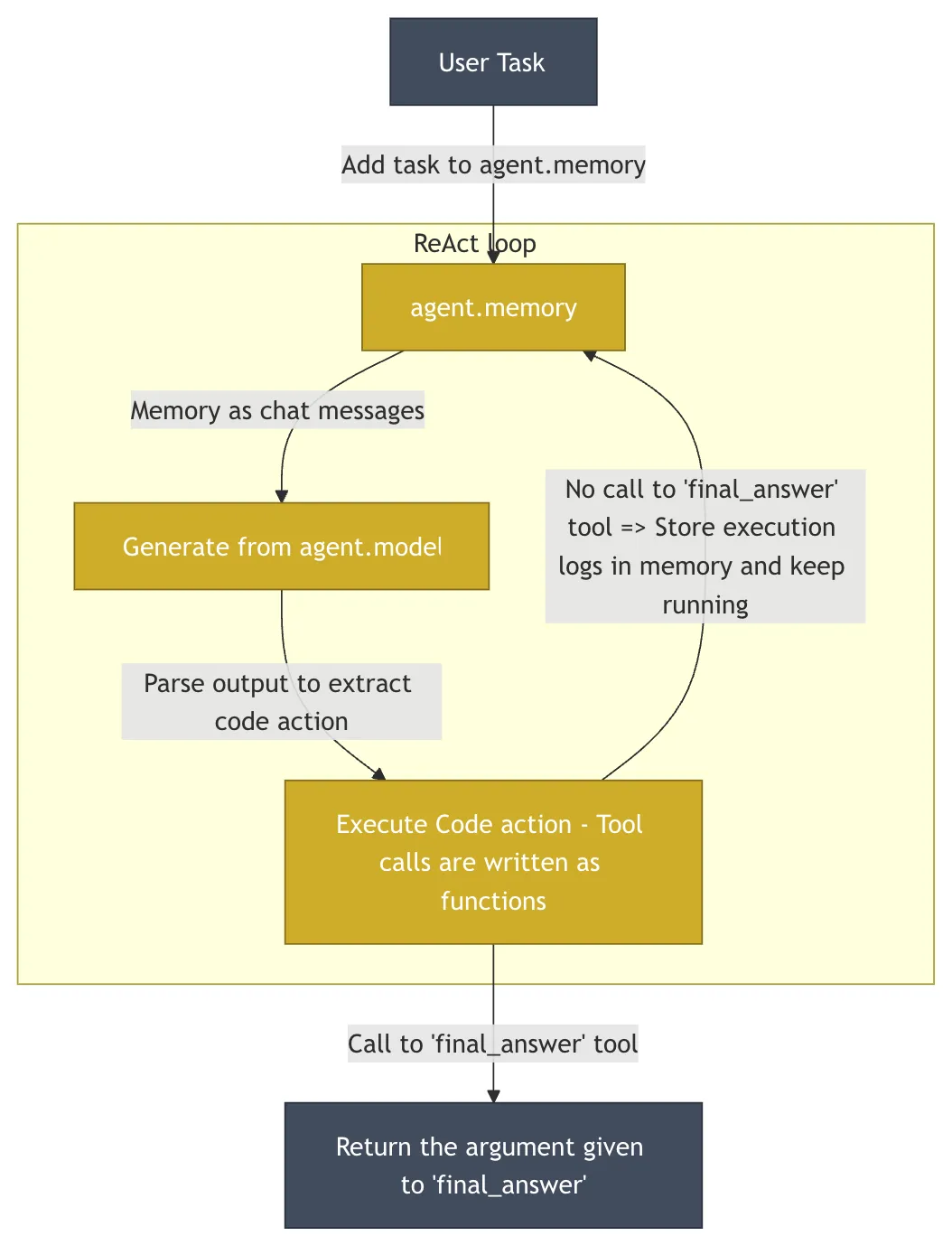
HuggingFace 的 OpenDeepResearch O projeto, cujo núcleo consiste em smolagents que assume as mesmas características da unidade DeerFlow filosofias de design muito diferentes. O projeto está em GAIA (General AI-Assisted Agent) - uma referência definitiva projetada para medir os recursos das inteligências gerais de IA por meio de tarefas do mundo real - no conjunto de validação alcançado 55% pontuação pass@1. Essa pontuação é menor do que a ChatGPT 的 67%mas como uma implementação de código aberto, demonstrou seu poder.
- ideia centralSimplicidade e abstração mínima.
smolagentsé deliberadamente mantida muito pequena (~1000 linhas), evitando o excesso de abstração que é comum em muitas estruturas e fornecendo aos desenvolvedores um alto grau de transparência e controle. - arquitetura centralEm seu núcleo está a "Inteligência de Código" (
CodeAgent). As ações dos inteligíveis são diretamente expressas comoPythonem vez do trecho de códigoJSONObjeto.LLMGerar um pequeno parágrafoPythonpara executar a próxima ação. Essa abordagem é muito mais expressiva do queJSONIsso ocorre porque o código suporta naturalmente uma lógica complexa, como loops, condicionais e definições de funções. No entanto, a execução de código arbitrário gerado pela IA acarreta riscos de segurança significativos. Por esse motivo, asmolagentsSuporte em áreas comoE2BtaisCaixa de areia Execute o código no arquivoE2BFornecer uma nuvem isoladaLinuxambiente no qual o código gerado pela IA é executado, com acesso ao sistema de arquivos e à rede, mas sem capacidade de influenciar o sistema host, garantindo assim a segurança e, ao mesmo tempo, capacitando a inteligência.
Comentário do colunista: smolagents O conceito "código é ação" é uma maneira atraente de voltar aos fundamentos da programação e dar às inteligências mais flexibilidade do que nunca. É uma ótima opção para desenvolvedores que desejam personalização profunda e controle total sobre o comportamento de suas inteligências. A filosofia é dar ao desenvolvedor o máximo de poder e fornecer proteções de segurança.
LangChainAI/OpenDeepResearchFluxos de trabalho diagramáticos e reflexão metacognitiva
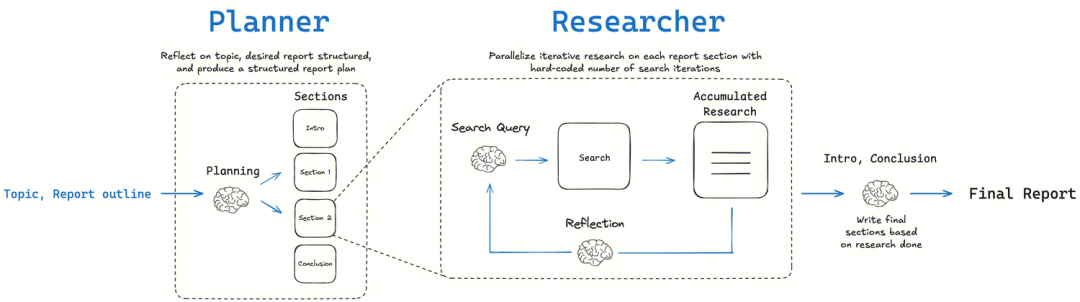
LangChain baseado na comunidade open_deep_research No centro do projeto está um fluxo de trabalho de vários estágios, iterativo e autorreflexivo, projetado para imitar o processo de pesquisa de um especialista humano.
- Conceitos básicos: Planejar-Pesquisar-Refletir-EscreverA chave para essa estrutura é o componente de "reflexão". A chave para a estrutura é o componente "reflexão". Não se trata apenas de verificar se há erros, é umMetacognição Essa é a expressão de "pensar sobre seu próprio processo de pensamento". Depois de coletar as informações iniciais, a inteligência avalia a integridade das informações atuais e se há alguma contradição ou lacuna no conhecimento. Se forem encontradas deficiências, ela gera uma nova consulta de pesquisa mais precisa e prossegue para a próxima iteração.
- método de implementação:
- Fluxo de trabalho baseado em gráficos:: Como em
DeerFlowEle é usado principalmenteLangGraphConstrução. Cada etapa do estudo é modelada como um nó no gráfico, o que torna todo o processo altamente visual, rastreável e fácil de depurar. Essa abordagem é ideal para cenários que exigem intervenção humana e controle de alta precisão. - Loop iterativo de vários agentesA inteligência avalia as informações existentes, gera novas perguntas e pesquisa mais a fundo em cada loop por meio de loops de pesquisa recursivos. Essa abordagem é dividida em dois modos:
简单模式 (Simple)O acesso direto a um único loop iterativo é rápido e adequado para problemas específicos;深度模式 (Deep)Inclui planejamento inicial e implementa pesquisadores paralelos para cada subtópico, mais aprofundado e abrangente para tópicos complexos.
- Fluxo de trabalho baseado em gráficos:: Como em
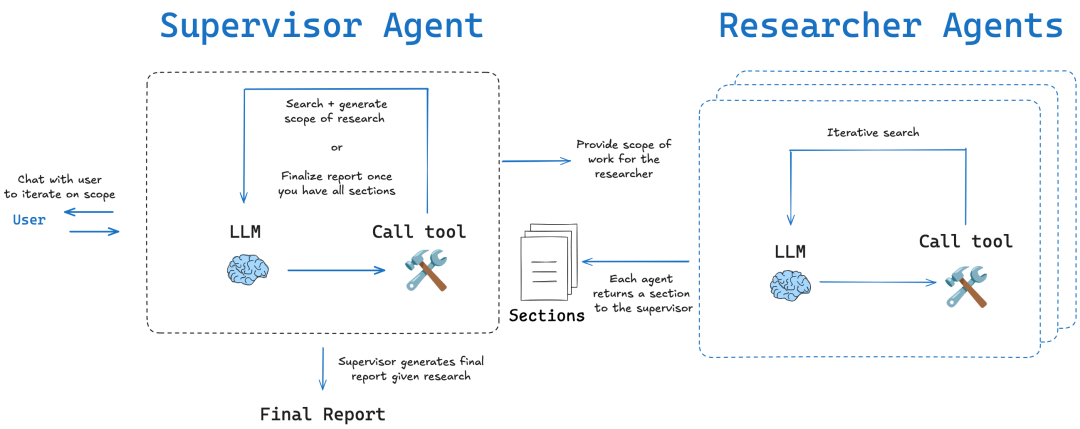
Comentário do colunista: LangChain Essa versão é um ótimo exemplo de modularidade e flexibilidade. Ela desenvolve com sucesso o conceito de ciência cognitiva de "autorreflexão" por meio do uso de LangGraph Oferece recursos avançados de modelagem para tarefas de pesquisa complexas e não lineares e é ideal para equipes que precisam produzir seus processos de pesquisa.
SkyworkAI/DeepResearchAgentCamadas clássicas e separação de preocupações
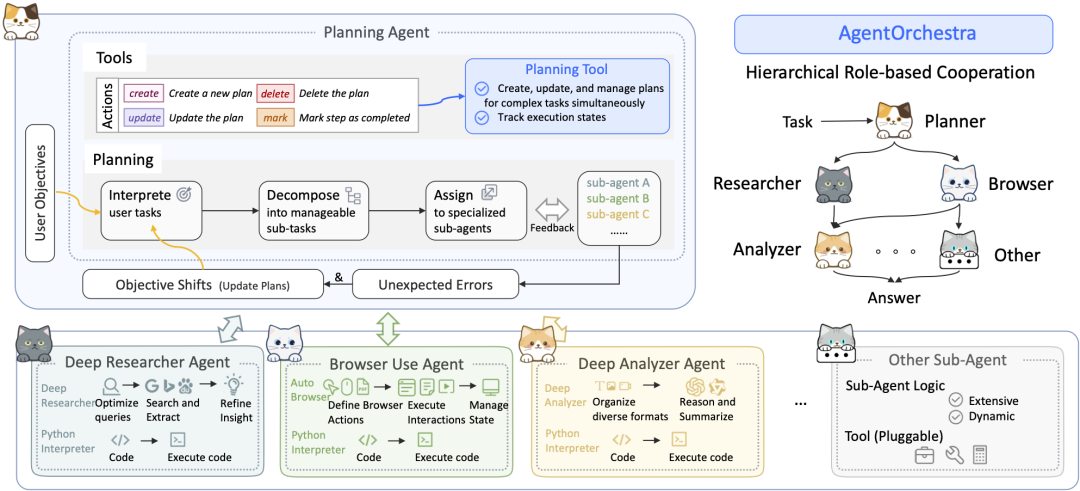
SkyworkAI 的 DeepResearchAgent É usada uma arquitetura explícita de duas camadas (Two-Layer), que é um padrão de design muito clássico na engenharia de software, no centro do qual está oSeparação de preocupações。
- arquitetura central:
- Camada 1: Agente de planejamento de nível superiorCamada de estratégia: atua como a "camada de estratégia" ou "camada de lógica comercial". Em vez de executar tarefas de pesquisa específicas, é responsável por entender a intenção do usuário, dividir metas ambiciosas em uma série de subtarefas gerenciáveis e desenvolver planos de fluxo de trabalho.
- Agentes de nível inferior (agentes especializados de nível inferior)Camada de execução: desempenha a função de "camada de execução" ou "camada de serviço". Consiste em várias inteligências com diferentes especializações, como "analisadores profundos" para análise de informações, "pesquisadores profundos" para pesquisa na Web e "usuários de navegador" para operação do navegador. "Elas executam fielmente as tarefas atribuídas pelas camadas superiores.
- Inspiração para arquitetura: O projeto foi implementado em sua
READMEEle menciona explicitamente que sua arquitetura está sujeita asmolagentsinspirado nele, e o desenvolve com aprimoramentos modulares e assíncronos. Isso reflete sua tentativa de combinarsmolagentsA simplicidade do conceito com um modelo mais estruturado de colaboração de corpos multiinteligentes.
Comentário do colunista: DeepResearchAgent A arquitetura de duas camadas consegue um bom desacoplamento entre "planejamento" e "execução". O design é bem estruturado e dimensionável e, no futuro, será fácil adicionar mais inteligência especializada (por exemplo, visualização de dados, execução de código etc.) à segunda camada sem precisar alterar a lógica de planejamento central na camada superior. Essa é uma implementação pragmática e projetada.
zhu-minjun/ResearcherMecanismos de autocrítica de confronto
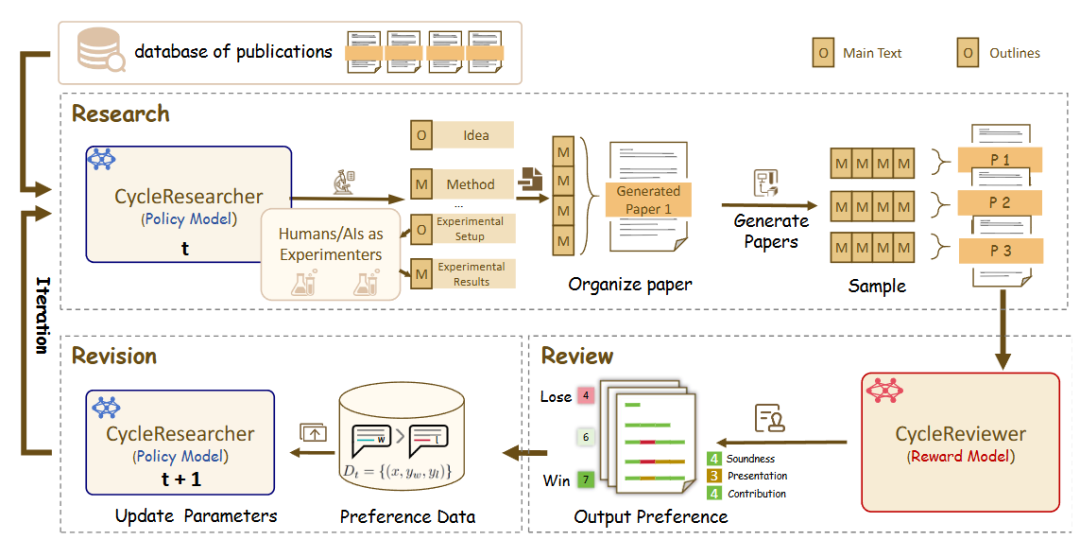
zhu-minjun/Researcher A arquitetura da empresa é uma colaboração multiinteligência em estágios semelhantes, mas seu recurso mais notável é a introdução de uma colaboração independente, que pode até ser chamada deSessões de "autocrítica" conflituosas。
- arquitetura central:
- Inteligência de planejamentoDesenvolvimento de programas e esboços de pesquisa.
- Inteligência de execução paralela:: Lançar inteligências executivas independentes para cada subtema para coletar informações em paralelo.
- Integração e geração do primeiro rascunhoSíntese de todos os resultados em um primeiro rascunho.
- Inteligência crítica e revisionistaReflexão: Esse é o destaque da arquitetura. Ela visualiza a "reflexão" como uma "inteligência crítica" independente. Essa inteligência atua como um revisor rigoroso e cético, desafiando a qualidade do primeiro rascunho e sugerindo alterações específicas e construtivas com base em regras predefinidas (por exemplo, precisão factual, objetividade, integridade da cadeia lógica, presença de viés). Em seguida, o sistema faz correções com base nesse feedback, criando um ciclo fechado de otimização iterativa.
- DeepReviewer: Em seu
Besto projeto é passado por um arquivo chamadoDeepReviewerpara obter essa experiência abrangente de auditoria, podendo até mesmo simular oSimulação de vários auditoresO relatório é submetido a testes de estresse, o que é semelhante ao processo de revisão por pares (Peer Review) no meio acadêmico.
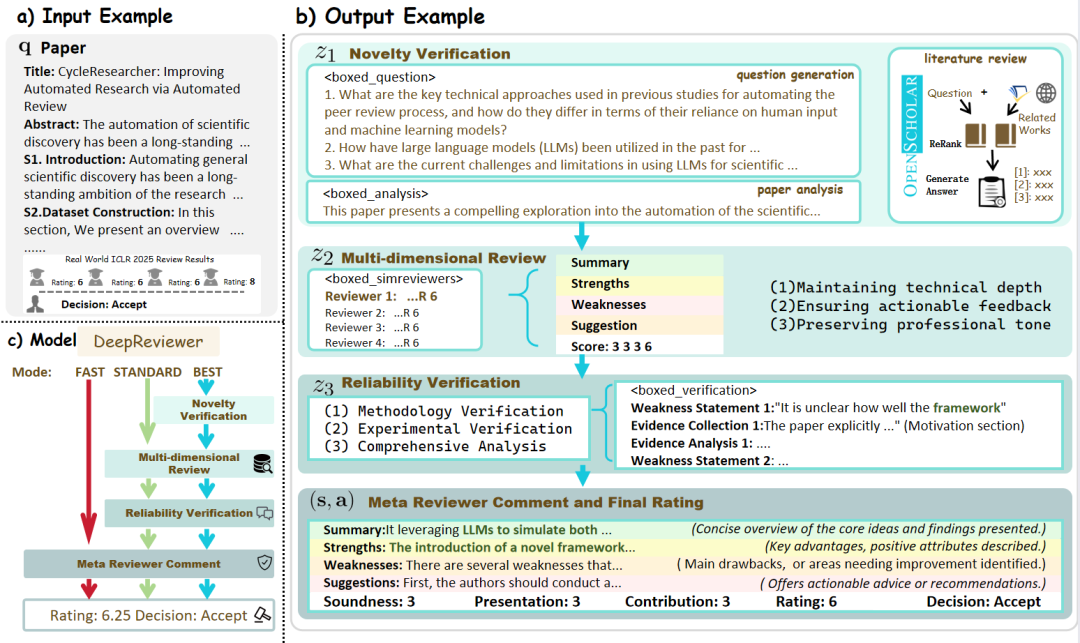
Comentário do colunistaDescrição: O projeto atualiza a "reflexão" de um estado interno para um processo externo e estruturado de confronto. Esse design "esquerda-direita" faz com que ele não seja apenas um agregador de informações, mas também um "pesquisador" que se desafia constantemente a melhorar a qualidade de seu conteúdo, buscando objetividade e abrangência.
Comercialização pesquisa aprofundada Relógio Corporal Inteligente
Depois de analisar as estruturas de código aberto para desenvolvedores, os aplicativos comercializados para usuários finais proporcionam uma experiência mais integrada e orientada para o produto.
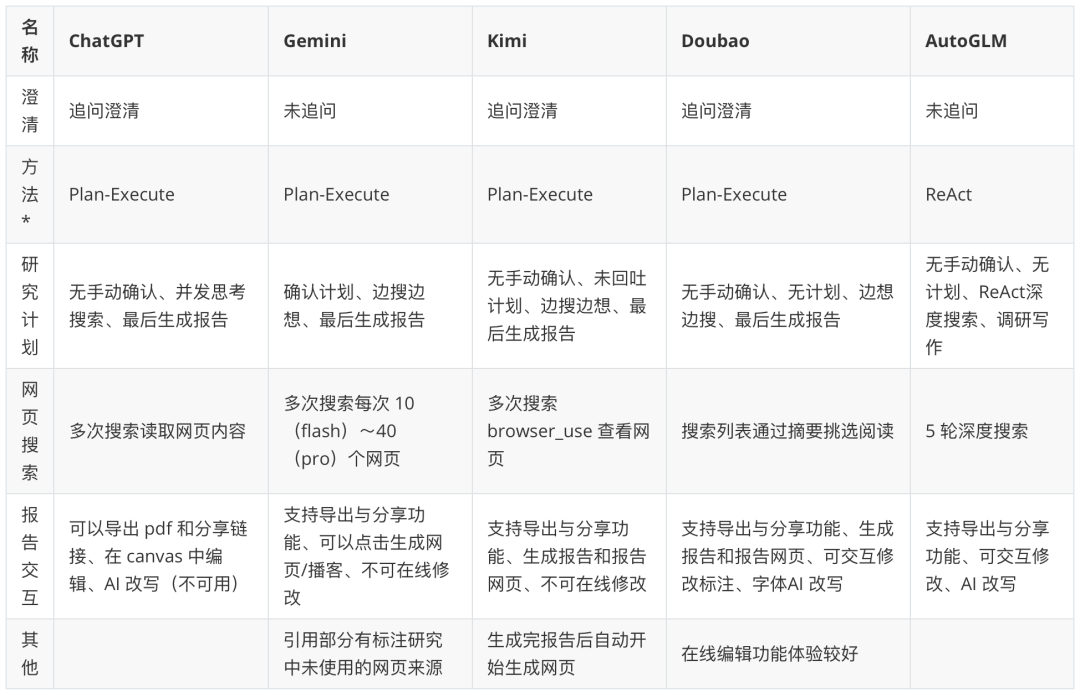
Observação: O "Intelligent Body Paradigm" (paradigma do corpo inteligente) na tabela é uma especulação baseada no comportamento do produto. Para mais pesquisas aprofundadas sobre inteligências: https://www.kdjingpai.com/ai-learning/research-assistant/
Enquanto as estruturas de código aberto expõem o "mecanismo", os produtos comerciais ocultam elegantemente o "mecanismo" em um belo "cockpit". Pegue Kimi Por exemplo, ele lida com problemas de pesquisa profunda sem que o usuário tenha que se preocupar com as etapas de planejamento, execução e síntese nos bastidores. O usuário faz uma pergunta complexa eKimi Automatiza o processo interno de pesquisa: planejamento de termos de pesquisa, acesso simultâneo a várias fontes da Web, digestão e integração de informações em tempo real usando sua janela contextual de vários milhões de palavras e, finalmente, apresentando uma resposta abrangente com fontes citadas em um diálogo fluido.
Outros produtos, como ChatGPT、Gemini etc., também estão sendo aprovadas CoT (Cadeia de pensamento),Tree of Thoughts ou processos de inteligência múltipla integrados internamente que melhoram continuamente sua capacidade de realizar tarefas de pesquisa complexas. Os produtos comerciais competem na precisão e na natureza em tempo real dos resultados de pesquisa, na profundidade e na percepção da integração das informações e na interatividade do relatório final (por exemplo, citações clicáveis, geração de gráficos, sugestões de acompanhamento etc.). Eles pegam a arquitetura complexa do mundo de código aberto e a empacotam em recursos poderosos que estão ao alcance do usuário comum.




























