



O ShareGPT-4o-Image é um grande conjunto de dados de geração de imagens multimodais de código aberto da equipe do FreedomIntelligence no GitHub, contendo 91 mil amostras de alta qualidade criadas com base nos recursos de geração de imagens do GPT-4o. O conjunto de dados é dividido em 45 mil amostras de texto para imagem e 46 mil amostras de texto mais imagem para imagem, e foi projetado para ajudar o modelo multimodal de código aberto a se alinhar com os recursos de geração de imagens do GPT-4o. A equipe também desenvolveu o modelo Janus-4o com base nesse conjunto de dados, que oferece suporte a recursos de edição de texto para imagem e imagem e supera o desempenho de seu antecessor, o Janus-Pro. O projeto é dedicado ao avanço da comunidade de IA multimodal por meio de dados e modelos de código aberto e ao fornecimento de recursos de alta qualidade para pesquisa e desenvolvimento.
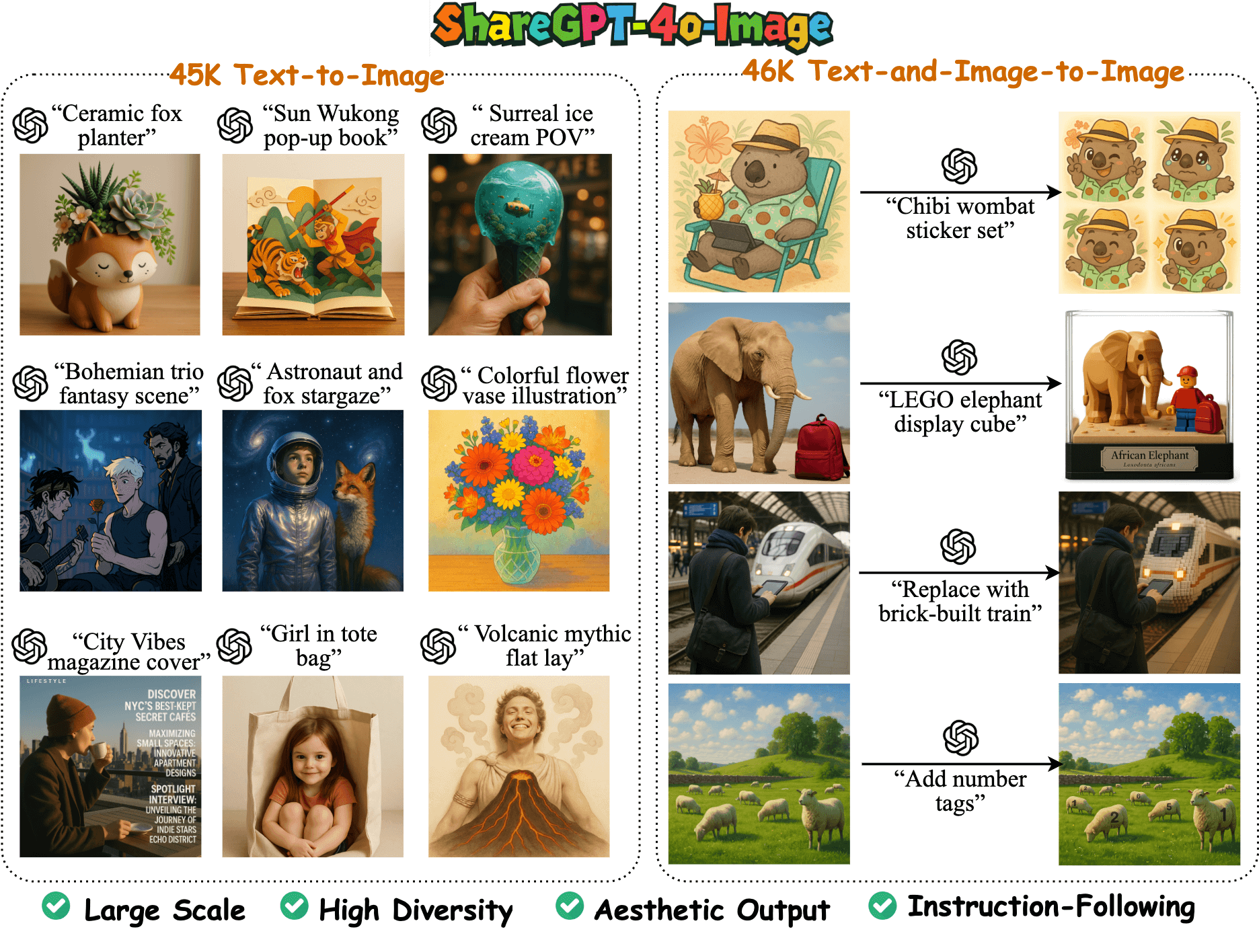
Lista de funções
- Fornece 91 mil amostras de geração de imagens de alta qualidade, incluindo 45 mil amostras de texto para imagem e 46 mil amostras de texto e imagem para imagem.
- Oferece suporte ao treinamento e à otimização de modelos multimodais de código aberto para aprimorar a geração e a edição de imagens.
- Inclui o modelo Janus-4o com suporte para geração de texto para imagem e edição de texto mais imagem para imagem.
- O conjunto de dados está disponível para download no Hugging Face no formato de um arquivo Parquet, que tem aproximadamente 20,7 MB de tamanho e contém 92.256 linhas de dados.
- São fornecidos documentação detalhada e exemplos de código para ajudar os desenvolvedores a se familiarizarem rapidamente com conjuntos de dados e modelos.
- O código-fonte aberto e os modelos estão hospedados no GitHub e no Hugging Face para facilitar a contribuição e a extensão da comunidade.
Usando a Ajuda
Aquisição e instalação de conjuntos de dados
O conjunto de dados ShareGPT-4o-Image está disponível gratuitamente no Hugging Face ou no GitHub. Aqui estão as etapas exatas:
- Acesso a conjuntos de dados:
- Abra a página do Hugging Face: https://huggingface.co/datasets/FreedomIntelligence/ShareGPT-4o-Image.
- Ou visite o repositório do GitHub em https://github.com/FreedomIntelligence/ShareGPT-4o-Image.
- O conjunto de dados é armazenado no formato Parquet e tem aproximadamente 20,7 MB de tamanho, contendo 92.256 linhas de dados.
- Baixar conjunto de dados:
- Na página do Hugging Face, clique no botão "Download" para fazer o download direto do arquivo Parquet.
- Ou use o comando Git para clonar seu repositório do GitHub:
git clone https://github.com/FreedomIntelligence/ShareGPT-4o-Image.git - Após o download, descompacte o arquivo (se necessário) e verifique se o arquivo Parquet pode ser lido pelo ambiente Python.
- Preparação ambiental:
- Instale o Python 3.7 ou posterior.
- Instale as bibliotecas de dependência necessárias, por exemplo
pandas和datasetspara carregar e processar arquivos Parquet:pip install pandas datasets - Se estiver usando o modelo Janus-4o, você precisará instalar o
torch和transformers:pip install torch transformers
- Carregando conjuntos de dados:
- Usando a função
datasetsA biblioteca carrega o conjunto de dados:from datasets import load_dataset dataset = load_dataset("FreedomIntelligence/ShareGPT-4o-Image") print(dataset) - O conjunto de dados contém correspondências entre dicas textuais e imagens geradas que podem ser usadas diretamente para treinamento ou análise de modelos.
- Usando a função
Usando o modelo Janus-4o
O Janus-4o é um modelo multimodal ajustado com base no conjunto de dados ShareGPT-4o-Image que oferece suporte à geração de texto para imagem e à edição de imagens. As etapas específicas são as seguintes:
- Modelos de carregamento:
- Faça o download do modelo Janus-4o-7B da Hugging Face:
from transformers import AutoModelForCausalLM, VLChatProcessor model_path = "FreedomIntelligence/Janus-4o-7B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained( model_path, trust_remote_code=True, torch_dtype=torch.bfloat16 ).cuda().eval() - Certifique-se de que seu dispositivo seja compatível com GPUs e tenha CUDA instalado; caso contrário, use uma CPU (desempenho mais lento). [](https://huggingface.co/FreedomIntelligence/Janus-4o-7B)
- Faça o download do modelo Janus-4o-7B da Hugging Face:
- Geração de texto para imagem:
- Use o
text_to_image_generategera a imagem:def text_to_image_generate(input_prompt, output_path, vl_chat_processor, vl_gpt, temperature=1.0, parallel_size=2, cfg_weight=5): torch.cuda.empty_cache() conversation = [{"role": "<|User|>", "content": input_prompt}, {"role": "<|Assistant|>", "content": ""}] sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts( conversations=conversation, sft_format=vl_chat_processor.sft_format, system_prompt="" ) prompt = sft_format + vl_chat_processor.image_start_tag # 后续生成步骤参考 GitHub 文档 - Digite exemplos de prompts, como "A picture of a beach at sunset with coconut trees on the sand and a sailboat in the distance" (Uma foto de uma praia ao pôr do sol com coqueiros na areia e um veleiro à distância).
- A imagem gerada será salva na pasta
output_path。
- Use o
- Texto e edição de imagem para imagem:
- O Janus-4o oferece suporte à edição de imagens com base em imagens de entrada e avisos de texto. Por exemplo, insira uma imagem de paisagem e o prompt "Replace sky with stars" (Substitua o céu por estrelas).
- O processo é semelhante ao de texto para imagem, mas você precisa fornecer o caminho para a imagem; consulte o repositório do GitHub para obter o código.
- Ver documento:
- Visite o arquivo README no repositório do GitHub para obter parâmetros detalhados do modelo e instruções sobre como gerar a configuração.
- A página do Hugging Face também fornece uma prévia da estrutura do conjunto de dados e amostras para facilitar a compreensão do formato dos dados.
advertência
- Os conjuntos de dados e modelos requerem um ambiente de Internet estável para serem baixados.
- Inferência de modelo acelerada usando a GPU; recomenda-se pelo menos 16 GB de memória gráfica.
- Se você encontrar problemas para carregar ou gerar modelos, consulte a página de problemas do GitHub ou envie feedback sobre o problema.
- O conjunto de dados e o modelo são de código aberto, e a comunidade incentiva contribuições de código ou melhorias no conjunto de dados.
cenário do aplicativo
- Desenvolvimento de modelos multimodais
Os desenvolvedores podem usar o conjunto de dados ShareGPT-4o-Image para treinar ou ajustar seus próprios modelos multimodais para aprimorar a geração de texto para imagem ou a edição de imagens em cenários como a geração de trabalhos artísticos, esboços de design e muito mais. - pesquisa acadêmica
Os pesquisadores podem usar o conjunto de dados para analisar os padrões de geração de imagens do GPT-4o e explorar o alinhamento semântico e a qualidade de geração do modelo multimodal, o que é adequado para pesquisas acadêmicas no campo da Inteligência Artificial e da Visão Computacional. - Geração de conteúdo criativo
Designers ou criadores de conteúdo podem usar os modelos Janus-4o para gerar rapidamente imagens de alta qualidade com base em descrições textuais ou para editar estilisticamente imagens existentes para aplicações em publicidade, jogos ou produção de filmes. - Educação e ensino
Professores e alunos podem usar os conjuntos de dados e modelos para experimentar lições de IA, aprender como funcionam os modelos multimodais e praticar tarefas de geração de texto para imagem e edição de imagens.
QA
- O conjunto de dados ShareGPT-4o-Image é gratuito?
Sim, o conjunto de dados é totalmente de código aberto, disponível gratuitamente para download e uso no Hugging Face e no GitHub, sob a licença Apache-2.0. - Como o modelo Janus-4o se compara ao GPT-4o?
O Janus-4o é um modelo de código aberto ajustado com base no conjunto de dados ShareGPT-4o-Image, que oferece suporte à conversão de texto em imagem e à edição de imagens, mas ainda é ligeiramente inferior ao GPT-4o em termos de desempenho geral. - Que hardware é necessário para executar o Janus-4o?
As GPUs habilitadas para CUDA (pelo menos 16 GB de RAM) são recomendadas para obter o melhor desempenho; as CPUs podem executá-lo, mas em uma velocidade mais lenta. - Como posso contribuir com o projeto?
As Pull Requests podem ser enviadas ao repositório do GitHub para contribuir com código, otimizar modelos ou complementar conjuntos de dados, conforme descrito nas diretrizes de contribuição do repositório.































