

Muitos usuários fazem upload de dados importantes (como arquivos de imagem simples ou documentos PDF digitalizados) para a plataforma de desenvolvimento de aplicativos do LLM. Dify Um problema complicado é frequentemente encontrado quando a base de conhecimento doDify Não é possível ler e analisar esses formatos não textuais diretamente. Isso se deve principalmente ao Dify A funcionalidade nativa da base de conhecimento do Google está mais concentrada no processamento e na compreensão de dados de texto simples. Para superar essa limitação, é possível introduzir MinerU-API ferramenta que capacita Dify Os poderosos recursos de reconhecimento óptico de caracteres (OCR) da Knowledge Base. Em seguida, serão fornecidos detalhes sobre como criar um fluxo de trabalho que permita o Dify A Base de Conhecimento é capaz de analisar com eficiência informações de texto em imagens e documentos digitalizados. Este tutorial é baseado no Dify Versão 1.3.1.
preparação preliminar
Há duas preparações importantes que precisam ser concluídas antes que você possa começar a criar um fluxo de trabalho: a implantação do MinerU-API Serviço e criação Dify Base de conhecimento.
Implantação da MinerU-API
MinerU-API é uma ferramenta que oferece suporte à análise de documentos em vários formatos (inclusive OCR). Para obter uma introdução detalhada e as etapas para obter o código, consulte os dois artigos relacionados "Extracting PDF with MinerU in Dify" e "MinerU-API | Supporting Multi-Format Parsing to Further Enhance Dify's Document Capabilities". Isso pressupõe que o usuário tenha obtido MinerU-API e descreva brevemente seu código Docker Ordens de implantação.
docker run -d --gpus all --network docker_ssrf_proxy_network --name mineru-api -v minerupaddleocr:/root/.paddleocr mineru-api:v0.3
Esse comando iniciará um comando em segundo plano chamado mineru-api 的 Docker e aloca os recursos da GPU (se disponíveis) enquanto o conecta à rede especificada e monta um volume de dados para o persistente PaddleOCR de dados relevantes.
Criação de uma base de conhecimento Dify
Em primeiro lugar, em Dify Uma nova base de conhecimento é criada na plataforma. O processo de criação envolve a configuração do modelo de incorporação subjacente, que é responsável por transformar os dados de texto em vetores de alta dimensão para compreensão semântica e cálculo de similaridade pela máquina, e o modelo de classificação, que é usado para classificar novamente os resultados de recuperação iniciais para melhorar a precisão e a relevância das respostas finais.

Figura 1: Interface da base de conhecimento Create Dify
Depois que a base de conhecimento tiver sido criada, abra-a com o botãobarra de endereçosEssa ID é um parâmetro importante para chamadas de API subsequentes.

Figura 2: Obtendo o ID da base de conhecimento na barra de endereços do navegador
Em seguida, navegue atéBase de dados de conhecimento -> API Tela de configurações para gerar uma nova chave de API. Essa chave será usada para autorizar as várias operações que o fluxo de trabalho executa na base de conhecimento.
Figura 3: Interface da chave da API da Base de Conhecimento
Criando fluxos de trabalho da base de conhecimento do MinerU
Visão geral do fluxo de trabalho
O fluxo de trabalho construído consiste em três nós principais de execução de código que trabalham em conjunto para analisar e criar bibliotecas de imagens ou documentos digitalizados.
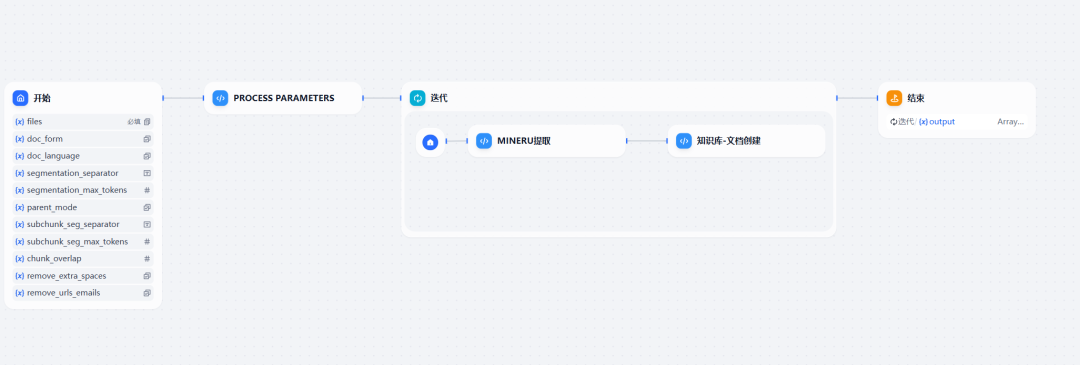
Figura 4: Visão geral do fluxo de trabalho da base de conhecimento do MinerU
As funções de cada um dos três blocos de código são as seguintes:
- Process ParametersEsse nó é responsável principalmente pelo tratamento de chamadas para
DifyCriar uma interface de documento (/datasets/{dataset_id}/document/create-by-text) com os parâmetros necessários. - Extração do MinerUA tarefa principal desse nó é chamar
MinerU-APIUm serviço que converte arquivos PDF ou de imagem recebidos em conteúdo de texto simples no formato Markdown usando a tecnologia OCR. - Knowledge Base - Criação de documentosEsse nó é criado chamando a função
Difycom teto plano/datasets/{dataset_id}/document/create-by-textInterface da API, que será definida na etapa anterior peloMinerUO conteúdo do texto extraído é criado como um novo documento na base de conhecimento. A seguir, um exemplo de código Python para esse nó:
import requests
def main(api_key, file_name, content, api_params, dataset_id):
headers = {
'Authorization': f'Bearer {api_key}',
'Content-Type': 'application/json',
}
# 更新API参数,加入文件名和提取的文本内容
api_params.update({
"name": file_name,
"text": content,
})
# 构建Dify API的请求URL
# 注意:实际部署时,'http://api:5001' 可能需要根据Dify服务的实际地址和端口进行调整
url = f'http://api:5001/v1/datasets/{dataset_id}/document/create-by-text'
response = requests.post(
url,
headers=headers,
json=api_params,
)
return {"result": response.text}
Teste de eficácia
Para verificar a eficácia do fluxo de trabalho, pegue um documento PDF impresso diretamente de uma página da Web como exemplo e compare-o com um documento PDF carregado diretamente no Dify A base de conhecimento é igual à base de conhecimento criada por meio do recém-criado MinerU Eficácia do processamento do fluxo de trabalho.
O efeito do upload direto de uma base de conhecimento:
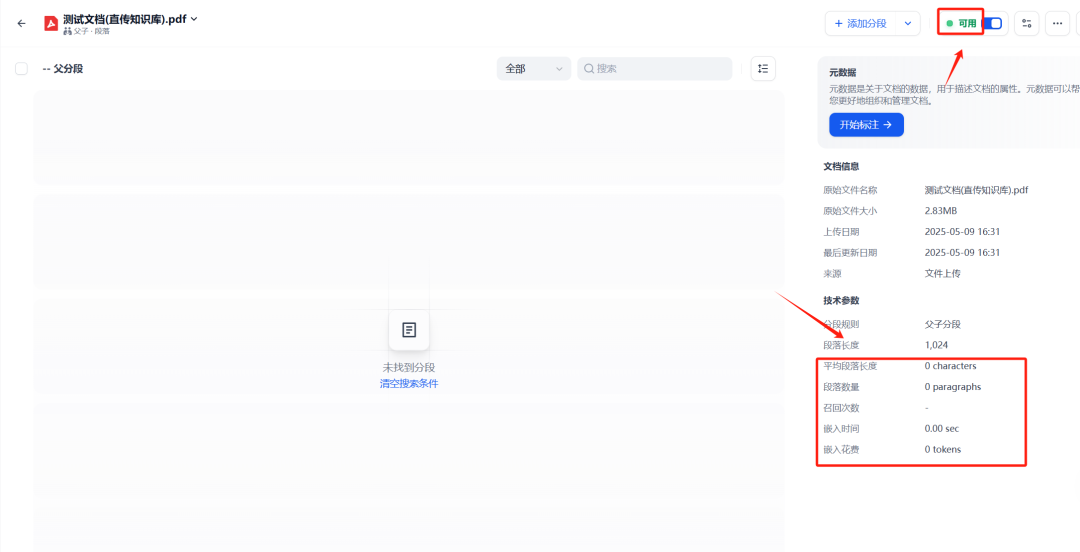
Figura 5: Faça o upload direto de documentos PDF para a base de conhecimento da Dify depois que o estado da
Como você pode ver na imagem acima, mesmo que o documento tenha sido carregado com sucesso, o Dify Os recursos nativos da base de conhecimento não conseguiram analisar nenhum texto do PDF digitalizado, deixando o documento praticamente em branco na base de conhecimento.
O efeito da criação de um documento por meio de um fluxo de trabalho do MinerU:
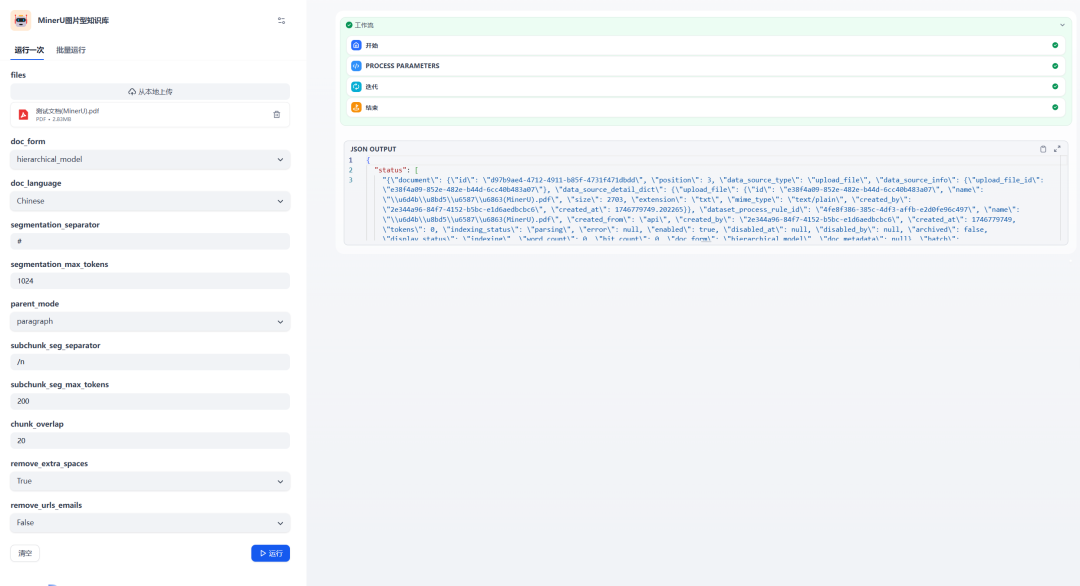
Figura 6: Resultados da execução do processamento e da criação de documentos por meio do fluxo de trabalho do MinerU
O gráfico acima mostra queMinerU O fluxo de trabalho foi executado com êxito e a chamada de interface retornou um resultado bem-sucedido. Nesse momento, você pode ir para a Base de Conhecimento para visualizar o documento recém-criado.
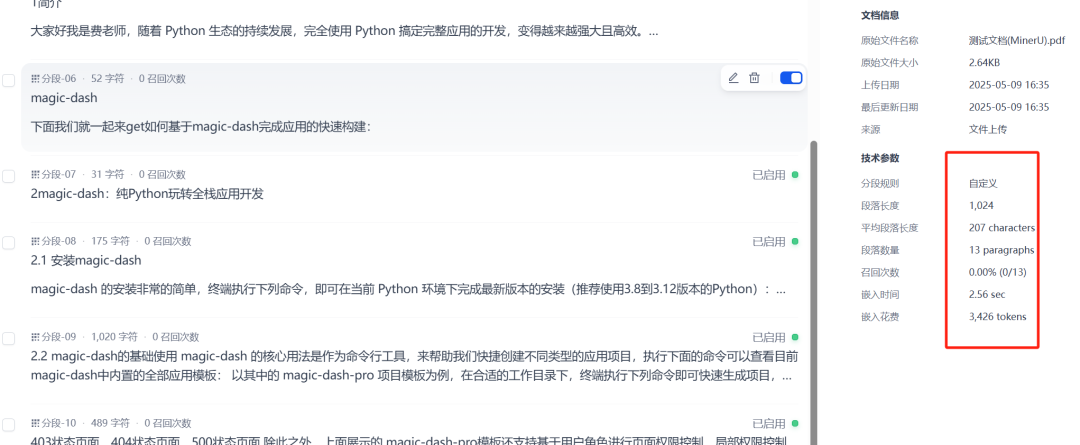
Figura 7: Visualização de um documento criado por um fluxo de trabalho do MinerU na Base de Conhecimento da Dify
Depois que um documento é criado por meio de um fluxo de trabalho e importado para a base de conhecimento, oDify Ela será processada automaticamente para indexação. Depois de aguardar a conclusão da indexação, um teste de recuperação pode ser realizado para verificar se a base de conhecimento é capaz de realizar uma recuperação eficaz de perguntas e respostas ou de informações com base no conteúdo textual das imagens.
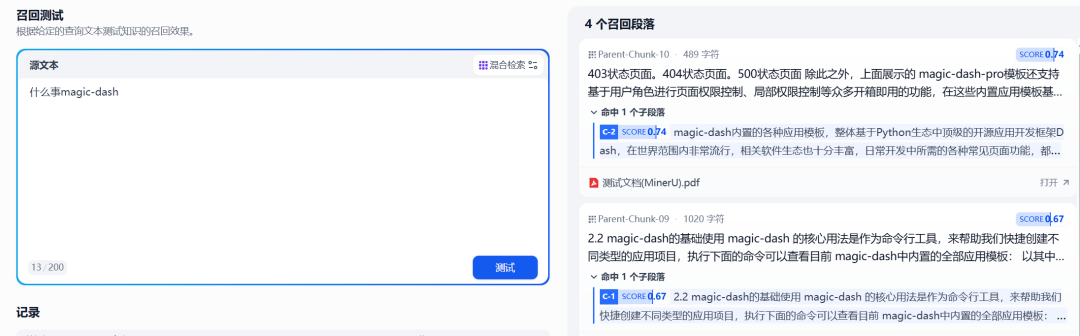
Figura 8: Teste de recuperação em documentos processados e armazenados pelo MinerU
Os resultados do teste mostram que, ao MinerU Documentos processados por fluxo de trabalho que contêm conteúdo textual que foi extraído e indexado com sucesso, permitindo a Dify A base de conhecimento é capaz de entender e responder a perguntas baseadas nessas informações de formato de imagem originalmente colocadas. Isso aprimora significativamente a Dify A capacidade da base de conhecimento de lidar com diversos tipos de documentos.

































