

Ao criar aplicativos de base de conhecimento com base no Retrieval Augmented Generation (RAG), o pré-processamento e o fatiamento de documentos (Chunking) são etapas essenciais para determinar os resultados finais da recuperação. Código aberto RAG engine (palavra emprestada) RAGFlow Fornece uma variedade de estratégias de fatiamento, mas sua documentação oficial carece de explicações claras sobre os detalhes dos métodos e casos específicos, o que gera muita confusão para os desenvolvedores.
Por meio de uma série de testes de benchmark, este artigo tem o objetivo de fornecer informações sobre a RAGFlow O mecanismo de funcionamento e as principais diferenças entre os diferentes métodos de fatiamento no sistema de gerenciamento de dados O teste será centrado nas seguintes perguntas comuns:
- Como o índice de capítulos de um documento será tratado quando fatiado? Eles serão tratados como blocos separados ou mesclados com o corpo do texto?
- Como as imagens incorporadas no corpo do texto serão atribuídas quando fatiadas?
MANUAL、BOOK、LAWSQual é a base específica para o fatiamento no método iso-slicing?TABLEComo o método garante que as informações do cabeçalho da tabela sejam mantidas para cada linha de dados ao dividir por linha?QAO método de fatiamento pode serTABLEMétodos de substituição?
RAGFlow Os métodos de fatiamento podem ser amplamente classificados nas seguintes categorias:
- Abordagem genérica (
General)Abrange todos os tipos de arquivos e fatias com base em "comprimento + delimitador", que é amplamente aplicável, mas menos preciso. - Métodos de estruturação de documentos (
MANUAL,BOOK,LAWS)Slices: divide documentos com uma estrutura hierárquica clara (por exemplo, DOCX, PDF) com base em seu índice ou em tags específicas. - Métodos de estruturação de tabelas (
TABLE,QA)Para dados tabulares (por exemplo, XLSX), processamento por linha ou colunas específicas. - Métodos específicos da cena (
ONE,RESUME,PAPER,PRESENTATION)Projetado para fins especiais, como documentos únicos, currículos, ensaios e apresentações.
Esta análise se concentrará nos métodos mais comuns e confusos de estruturação de documentos e tabelas.
Divisão por estrutura de documento: MANUAL, LIVRO, LEIS
Todos os três métodos são adequados para o processamento de documentos estruturados, mas sua lógica de divisão e granularidade são diferentes. Para fazer uma comparação visual, foi escolhido como exemplo o documento "Tax Collection and Management Law of the People's Republic of China.docx", que contém uma estrutura clara de capítulos.
A estrutura original do documento é interceptada abaixo:

Método MANUAL: baseado no estilo "Title" (Título).
MANUAL O método divide o documento estritamente de acordo com o estilo "Título" definido no Word ou PDF (por exemplo, Título 1, Título 2). Ele divide até a granularidade mais fina do nível do cabeçalho. É importante observar que somente o "estilo" é reconhecido, pois o título do texto acionará o corte; o texto comum em negrito ou em fonte ampliada (como o texto do "Artigo 15", "Artigo 16 ") será tratado como corpo do texto.
Uso da documentação de teste MANUAL O resultado do fatiamento do método é mostrado abaixo:

Os resultados da análise mostram que o documento é dividido em um total de 6 partes (partes). Cada bloco herda todos os títulos de seus diretórios principais até o título raiz do documento. Por exemplo, o bloco de conteúdo em "Chapter 2 Tax Administration" conterá dois títulos, "Tax Collection and Administration Law of the People's Republic of China" e "Chapter 2 Tax Administration".
Se houver conteúdo do corpo diretamente anexado sob o cabeçalho de nível superior, ele também será cortado em um bloco separado.

Metodologia do livro: baseada em "catálogo + parágrafo"
BOOK O método usa uma estratégia de divisão semântica mais profunda. Primeiro, ele divide o índice por capítulo e, em seguida, divide o conteúdo do corpo de cada capítulo por semântica (subtópicos ou parágrafos). Isso permite BOOK A granularidade de corte do método é a melhor das três.
fazer uso de BOOK processa o mesmo documento com os seguintes resultados:
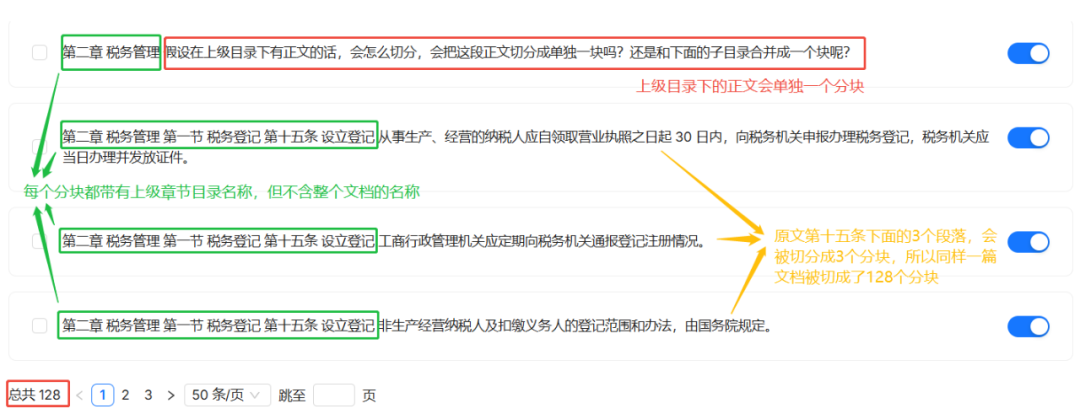
与 MANUAL A principal diferença entre os métodos é que os três parágrafos do "Artigo 15" são finamente cortados em três partes separadas. O documento inteiro acabou sendo cortado em 128 partes.
No contexto da herança contextual, oBOOK Cada bloco do método também conterá o título do diretório pai, mas, diferentemente do método MANUAL Ao contrário desse, ele não contém os cabeçalhos de nível superior do documento. Esse design pode ser mais adequado para focar no conteúdo de uma seção específica em uma pesquisa, em vez do contexto de todo o documento.
Metodologia LAWS: baseada na rotulagem da "cláusula de seção"
LAWS foi projetado para documentos legais ou regulatórios e usa expressões regulares para identificar tokens específicos, como "Capítulo X", "Artigo X" etc., para fatiar e cortar, ignorando o estilo "título" do texto ou o nível do índice do texto.
fazer uso de LAWS processa o documento e divide o resultado em 87 partes.

LAWS As características da metodologia são as seguintes:
- identificador:: Embora "Artigo 15" e "Artigo 16" estejam no estilo de corpo normal do documento, eles são cortados com sucesso porque correspondem à marcação "Artigo".
- paragrafação: com
BOOKDiferente.LAWSNão haverá re-slicing de vários parágrafos em artigos, mas eles serão combinados no mesmo bloco. - contextualização:
LAWSO tratamento do contexto é muito exclusivo. Em vez de incorporar os cabeçalhos do catálogo principal diretamente em cada bloco de artigo, ele agrega os cabeçalhos do catálogo em cada nível em um bloco separado (conforme mostrado pelo wireframe verde na figura acima) para obter uma separação entre o conteúdo e o índice do catálogo.
Resumo da comparação de três métodos de fatiamento de documentos
Com base nos testes acima, as características dos três métodos podem ser resumidas da seguinte forma:
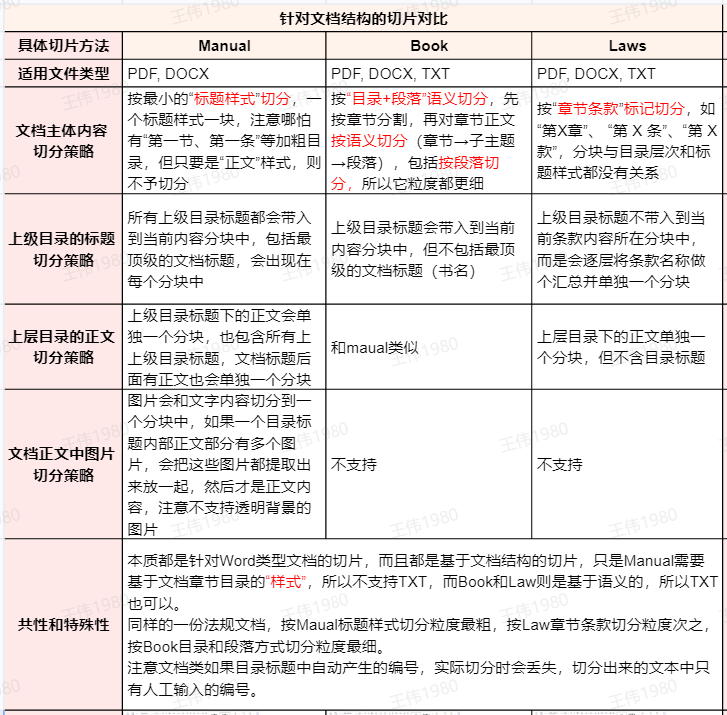
Vale a pena acrescentar queMANUAL A aplicação do método é muito clara, ou seja, manuais de produtos, documentos técnicos e outros documentos com uma hierarquia de estilo "título" padrão. E LAWS Especializado em leis, regulamentos e documentos de políticas.BOOK Por outro lado, com sua segmentação refinada em nível de parágrafo, ele é mais adequado para relatórios longos ou livros que exigem compreensão semântica profunda e perguntas e respostas.
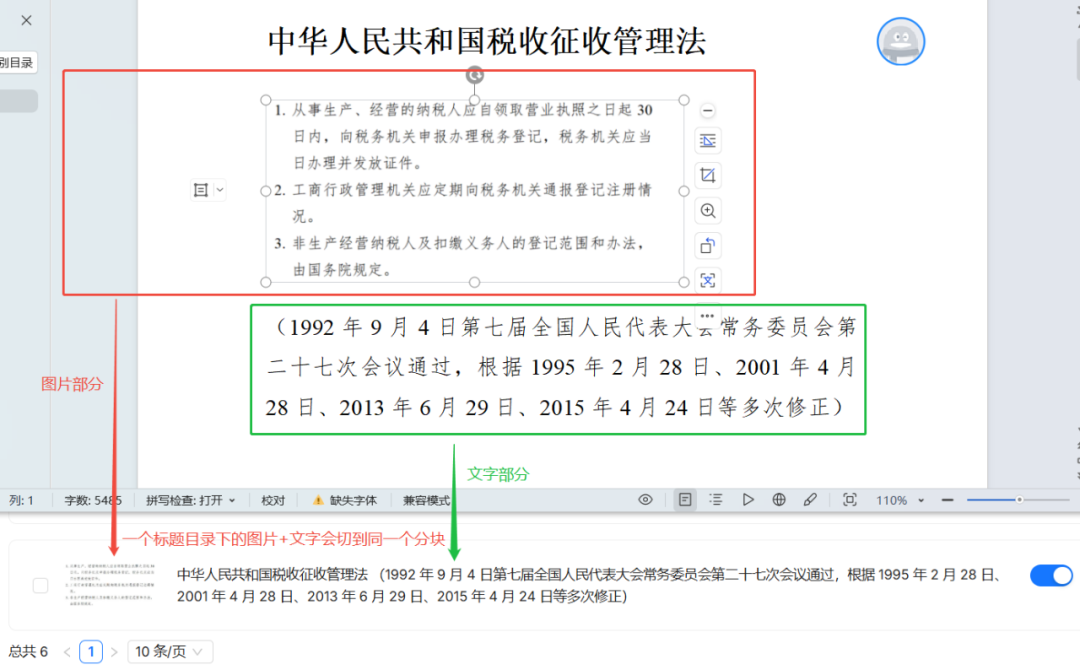
Além disso, o teste constatou que MANUAL O método é capaz de documentar a imagem e o conteúdo de texto adjacente cortado no mesmo bloco, o que é muito útil para o processamento de documentos gráficos.
Fatiamento por estrutura de tabela: TABLE, QA
Em seguida, passamos a validar o método de fatiamento em dados semelhantes a tabelas, como arquivos do Excel.
Método TABLE
O teste usa um formulário de conhecimento de operações que contém campos para produto, região, domínio comercial, descrição do problema, causa e solução.
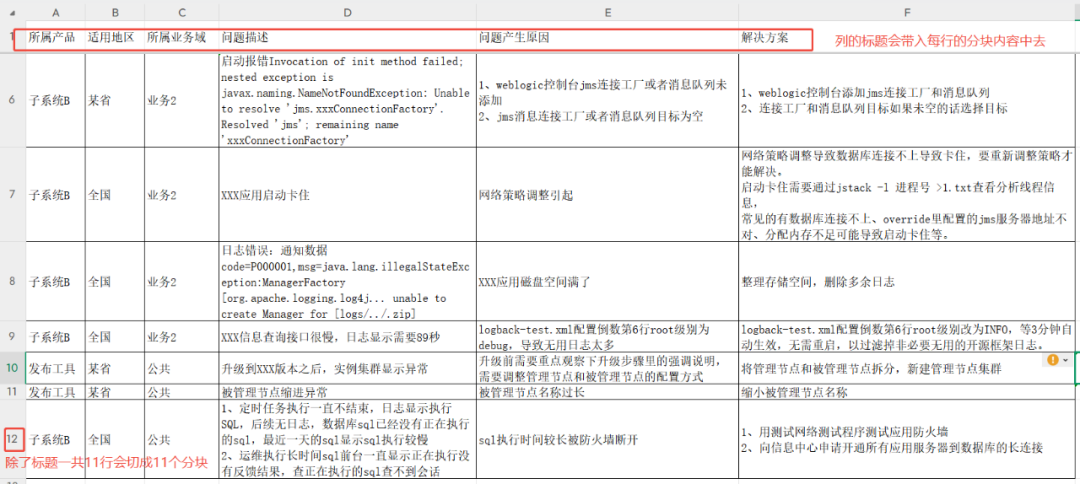
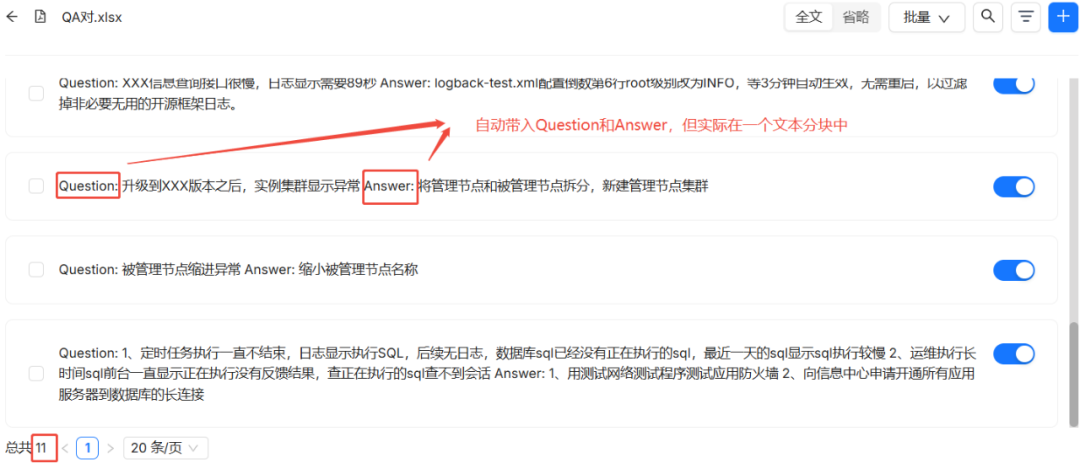
fazer uso de TABLE Ao cortar pelo métodoRAGFlow A primeira linha da tabela é reconhecida como o cabeçalho da coluna. À medida que é processado, ele corta as linhas (exceto as linhas de cabeçalho) e adiciona as informações do cabeçalho da coluna em sua totalidade ao bloco de conteúdo de cada linha, formando um formato "Chave: Valor".
O resultado do fatiamento é o seguinte, em que cada linha se torna um pedaço separado de conhecimento com informações contextuais completas:

Metodologia de controle de qualidade
QA O método é um corte de formulário para fins especiais que reconhece as duas primeiras colunas do formulário como "Pergunta" e "Resposta" por padrão. Se o formulário de conhecimento de O&M anterior for usado diretamente para teste.RAGFlow Somente as colunas "Product" e "Region" serão extraídas, ignorando todo o restante das informações.
Para um teste preciso, preparamos um formulário de formato de controle de qualidade padrão com apenas duas colunas, "Descrição do problema" e "Solução".
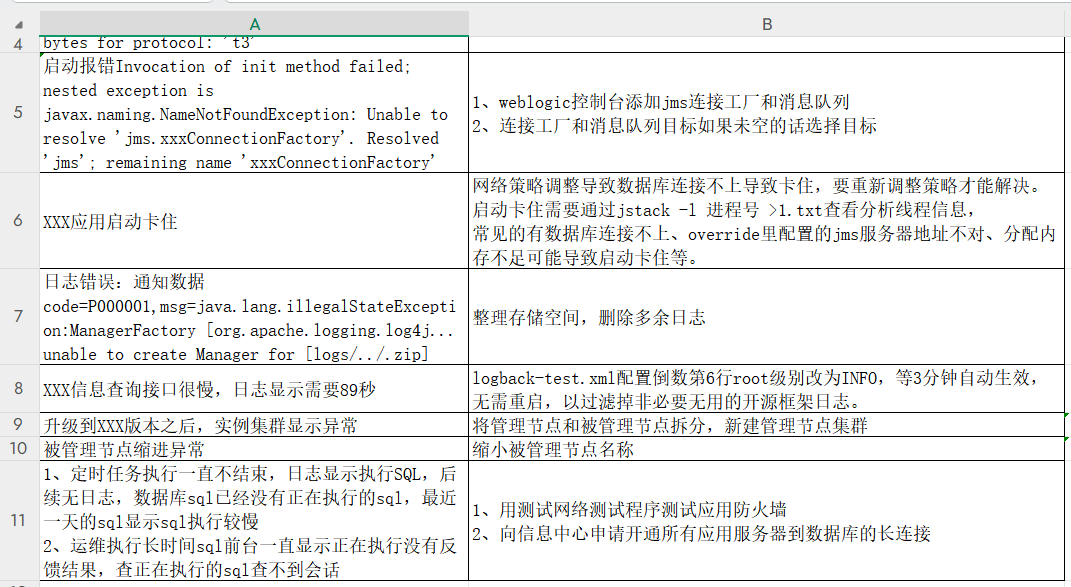
passar por QA Depois que o método é fatiado, cada linha também é fatiada em um bloco e automaticamente prefixada com "Pergunta:" e "Resposta:".
Resumo da comparação de dois métodos de fatiamento de tabelas
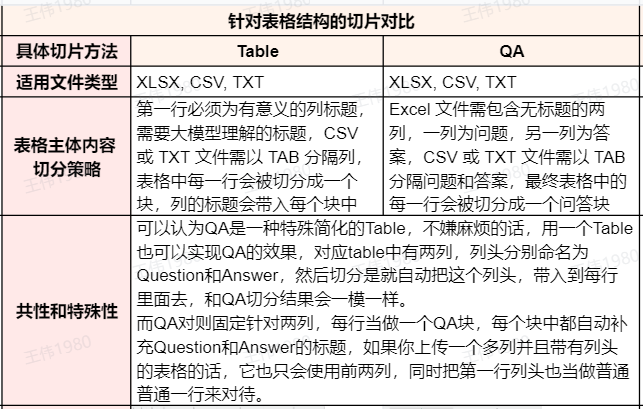
Uma análise mais profunda revela queQA Os métodos são essencialmente TABLE Um caso especial simplificado do método. O usuário tem total liberdade para usar o TABLE implementação do método QA O efeito da tabela é simplesmente nomear as duas colunas como "Pergunta" e "Resposta".
Na prática, se a base de conhecimento exigir a recuperação semântica com base em informações multidimensionais, como descrição do problema, causa, solução etc., oTABLE Essa abordagem é preferível. Se o cenário de pesquisa for estritamente limitado a pares de "pergunta-resposta" e você quiser usar informações de produto, região etc. para uma filtragem precisa, uma arquitetura melhor seria usar o QA O método divide o conteúdo de perguntas e respostas e também armazena informações como produtos, regiões etc. nos metadados (Metadados) do bloco.
No entanto, em RAGFlow Em nossos testes, descobrimos que o sistema foi projetado para oferecer suporte a metadados somente no nível do documento, mas não no nível mais granular do bloco. Ele também parece não ter parâmetros diretos para filtragem baseada em metadados em sua API de recuperação. Essa é uma limitação significativa na criação de sistemas RAG complexos e um dos motivos que levaram a equipe a considerar a criação de sua própria base de conhecimento.
Outros métodos especiais de fatiamento
RAGFlow Também são fornecidos vários métodos de fatiamento específicos do cenário:
- OneNão faz nenhum corte e trata o documento inteiro como um único bloco.
- ResumeAnálise estruturada de currículos para extrair informações importantes.
- PaperExtrair resumos, autores, capítulos, etc. para o formato do documento.
- PresentationPara PPT ou PDF convertido de PPT, converta cada página em um bloco separado contendo capturas de tela da página e conteúdo de texto extraído.
PRESENTATION Os resultados do teste do método são os seguintes:
Além do fatiamento: considerações detalhadas sobre a engenharia de RAG
(go ahead and do it) without hesitating RAGFlow São fornecidas ferramentas avançadas de fatiamento, mas um sistema RAG de nível de produção é muito mais do que isso. A escolha de uma solução de base de conhecimento interna geralmente se baseia em necessidades de engenharia mais profundas:
- Lógica de fatiamento personalizadaCenários de negócios geralmente exigem regras de fatiamento altamente personalizadas, por exemplo, para repositórios de código, dicionários de dados ou conhecimento interno em um formato específico, o que é difícil de cobrir com abordagens no local.
- Gerenciamento de metadados com granularidade finaComo mencionado anteriormente, anexar metadados ricos (por exemplo, versão, fonte, pessoa responsável, tag de negócios) a cada bloco de conhecimento e oferecer suporte a uma filtragem eficiente é fundamental para permitir a recuperação precisa, focar o escopo e melhorar a eficiência.
- Controle de versões e gerenciamento do ciclo de vida das bases de conhecimento:: As bases de conhecimento em ambientes de produção precisam ter fluxos de trabalho bem estabelecidos. Quando o conhecimento é adicionado ou atualizado, ele deve ser testado e validado para garantir que não afete a estabilidade e a precisão do serviço on-line antes de ser finalmente liberado com segurança.
- Aperfeiçoamento e aprimoramento do conhecimentoO sistema RAG também precisa processar o conhecimento original, por exemplo, gerando resumos, construindo relações de gráficos de conhecimento, adicionando extensões de sinônimos etc., e registrar a associação desse conhecimento derivado com o conhecimento original para rastreamento e sincronização eficazes em caso de alterações na fonte.
Juntos, esses complexos desafios de engenharia formam o caminho de um protótipo básico do RAG para um serviço de conhecimento de classe empresarial confiável e de fácil manutenção.


































