

Um fenômeno é comum: mesmo que RAG O sistema usa o LLM mais forte, e o Prompt foi ajustado várias vezes, mas o questionário ainda não funciona bem, com respostas que são contextualmente incompletas ou contêm erros de fato.
Os engenheiros examinaram o algoritmo de recuperação e otimizaram o Embedding mas geralmente negligencia uma etapa essencial antes de os dados entrarem na biblioteca de vetores: a fragmentação de documentos.
A fragmentação inadequada equivale a alimentar o modelo com um monte de "dados ruins" com informações ausentes. Por mais forte que seja a capacidade de raciocínio do modelo, ele não conseguirá obter uma resposta completa a partir do conhecimento fragmentado. A qualidade do chunking determina diretamente o limite inferior do desempenho do sistema RAG.
Em vez de falar sobre teorias vagas, este artigo se concentra no código do mundo real e na experiência de engenharia com várias estratégias de fragmentação para criar uma base sólida para os sistemas RAG.
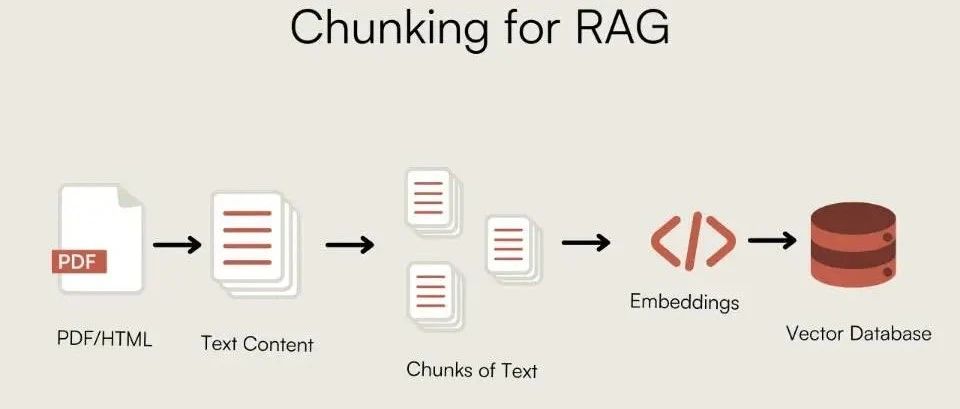
Por que os pedaços?
A necessidade de fragmentação decorre de duas limitações principais:
- Janela Contexto do modeloO Modelo de Linguagem Grande (LLM) não pode processar textos de comprimento infinito de uma só vez. Chunking é o processo de dividir um documento longo em partes que o modelo pode processar.
- Eficiência de pesquisa e ruídoDurante a recuperação, se um bloco de texto contiver muitas informações irrelevantes (ruído), ele diluirá o sinal principal, dificultando que o recuperador corresponda com precisão à intenção do usuário.
A fragmentação ideal está nointegridade contextual与densidade de informaçõesEncontrar o equilíbrio entre.chunk_size 和 chunk_overlap é o parâmetro subjacente que regula esse equilíbrio.chunk_overlap A continuidade semântica entre os limites dos blocos é garantida pela retenção de parte do texto repetido entre os blocos vizinhos.
estratégia básica de fragmentação
Chunking de comprimento fixo
Esse é o método mais direto, cortando em um número predefinido de caracteres. Ele não leva em conta nenhuma estrutura lógica do texto e é simples de implementar, mas tende a destruir a integridade semântica.
- ideia central: por um número fixo de caracteres
chunk_sizeTexto fatiado. - Cenários aplicáveisTexto simples com estrutura fraca ou estágios de pré-processamento com baixos requisitos semânticos.
from langchain_text_splitters import CharacterTextSplitter
sample_text = (
"LangChain was created by Harrison Chase in 2022. It provides a framework for developing applications "
"powered by language models. The library is known for its modularity and ease of use. "
"One of its key components is the TextSplitter class, which helps in document chunking."
)
text_splitter = CharacterTextSplitter(
separator=" ", # Split on spaces
chunk_size=100, # Size of each chunk
chunk_overlap=20, # Overlap between chunks
length_function=len,
)
docs = text_splitter.create_documents([sample_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
Separação recursiva de caracteres
LangChain Política genérica recomendada. Ela é definida por uma lista predefinida de caracteres (por exemplo ["\n\n", "\n", " ", ""]) realiza a segmentação recursiva, tentando priorizar a retenção de unidades lógicas, como parágrafos e frases.
- ideia centralRecursive slicing by hierarchical list of separators: Fatiamento recursivo por lista hierárquica de separadores.
- Cenários aplicáveisA estratégia genérica preferida para a grande maioria dos tipos de texto.
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Using the same sample_text from the previous example
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
# Default separators are ["\n\n", "\n", " ", ""]
)
docs = text_splitter.create_documents([sample_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
ajuste de parâmetrosPara chunking de comprimento fixo e recursivo, ochunk_size 和 chunk_overlap A configuração é fundamental.
chunk_sizeTamanho do bloco: Determine o tamanho de cada bloco. Se o bloco for muito pequeno, não haverá informações contextuais suficientes; se for muito grande, introduzirá muito ruído e aumentará aAPIO custo da chamada. Esse valor geralmente se baseia noEmbeddingEntradas para o modelotokenLimitações para escolher, comuns256,512,1024equivalência, precisamente para se adequar àBERTisomórfico512tokenJanela de contexto.chunk_overlapNúmero de caracteres sobrepostos: determina o número de caracteres sobrepostos entre blocos vizinhos. Defina uma sobreposição razoável (por exemplochunk_sizede 10%-20%) pode efetivamente evitar o corte de unidades semânticas completas nos limites dos blocos, o que é fundamental para garantir a continuidade semântica.
Chunking baseado em frases
A combinação de frases como a menor unidade garante a integridade semântica mais básica.
- ideia centralDivisão do texto em frases e, em seguida, agregação das frases em blocos.
- Cenários aplicáveisCenários que exigem um alto grau de integridade das frases, como documentos jurídicos e relatórios de notícias.
import nltk
try:
nltk.data.find('tokenizers/punkt')
except nltk.downloader.DownloadError:
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
def chunk_by_sentences(text, max_chars=500, overlap_sentences=1):
sentences = sent_tokenize(text)
chunks = []
current_chunk = ""
for i, sentence in enumerate(sentences):
if len(current_chunk) + len(sentence) <= max_chars:
current_chunk += " " + sentence
else:
chunks.append(current_chunk.strip())
# Create overlap
start_index = max(0, i - overlap_sentences)
current_chunk = " ".join(sentences[start_index:i+1])
if current_chunk:
chunks.append(current_chunk.strip())
return chunks
long_text = "This is the first sentence. This is the second sentence, which is a bit longer. Now we have a third one. The fourth sentence follows. Finally, the fifth sentence concludes this paragraph."
chunks = chunk_by_sentences(long_text, max_chars=100)
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(chunk)
tomar nota deQuando estiver lidando com chinesesnltk.tokenize.sent_tokenize O modelo padrão em inglês falhará. Os métodos de segmentação apropriados para o chinês devem ser usados, por exemplo, com base nos sinais de pontuação chineses (.!?) ), ou usando uma expressão regular carregada com o modelo chinês do spaCy 或 HanLP etc. biblioteca.
Chunking com reconhecimento de estrutura
Usando as informações estruturais inerentes do documento (por exemplo, cabeçalhos, listas) como limites dos blocos, essa abordagem é lógica e preserva melhor o contexto.
Agrupamento de texto Markdown
- ideia centralBaseado em
Markdownda hierarquia de títulos para definir os limites do bloco. - Cenários aplicáveisformal
MarkdownDocumentos comoGitHubREADME, documentação técnica.
from langchain_text_splitters import MarkdownHeaderTextSplitter
markdown_document = """
# Chapter 1: The Beginning
## Section 1.1: The Old World
This is the story of a time long past.
## Section 1.2: A New Hope
A new hero emerges.
# Chapter 2: The Journey
## Section 2.1: The Call to Adventure
The hero receives a mysterious call.
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
for split in md_header_splits:
print(f"Metadata: {split.metadata}")
print(split.page_content)
print("-" * 20)
fragmentação
- ideia centralChunking baseado em alto-falantes ou rodadas de diálogo.
- Cenários aplicáveisDiálogo de atendimento ao cliente, transcrições de entrevistas, atas de reuniões.
dialogue = [
"Alice: Hi, I'm having trouble with my order.",
"Bot: I can help with that. What's your order number?",
"Alice: It's 12345.",
"Alice: I haven't received any shipping updates.",
"Bot: Let me check... It seems your order was shipped yesterday.",
"Alice: Oh, great! Thank you.",
]
def chunk_dialogue(dialogue_lines, max_turns_per_chunk=3):
chunks = []
for i in range(0, len(dialogue_lines), max_turns_per_chunk):
chunk = "\n".join(dialogue_lines[i:i + max_turns_per_chunk])
chunks.append(chunk)
return chunks
chunks = chunk_dialogue(dialogue)
for i, chunk in enumerate(chunks):
print(f"--- Chunk {i+1} ---")
print(chunk)
Agrupamento semântico e temático
Esse tipo de abordagem vai além da estrutura física do texto e divide o conteúdo com base em sua semântica.
fragmentação semântica
- ideia centralSimilaridade de vetor: Calcule a similaridade de vetor de frases ou parágrafos vizinhos e corte em posições onde há uma mudança abrupta na semântica (baixa similaridade).
- Cenários aplicáveisDocumentos que exigem coesão semântica de alta precisão, como bases de conhecimento e artigos de pesquisa.
import os
from langchain_experimental.text_splitter import SemanticChunker
from langchain_huggingface import HuggingFaceEmbeddings
os.environ["TOKENIZERS_PARALLELISM"] = "false"
embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
# LangChain's SemanticChunker offers different threshold types:
# "percentile": Threshold based on the percentile of similarity score differences. Good for adaptability.
# "standard_deviation": Threshold based on standard deviation of similarity scores.
# "interquartile": Uses the interquartile range, robust to outliers.
# "gradient": Looks for sharp changes in similarity, useful for detecting abrupt topic shifts.
text_splitter = SemanticChunker(
embeddings,
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=95 # A higher percentile means it only breaks on very significant semantic shifts.
)
long_text = (
"The Wright brothers, Orville and Wilbur, were two American aviation pioneers "
"generally credited with inventing, building, and flying the world's first successful motor-operated airplane. "
"They made the first controlled, sustained flight of a powered, heavier-than-air aircraft on December 17, 1903. "
"In the following years, they continued to develop their aircraft. "
"Switching topics completely, let's talk about cooking. "
"A good pizza starts with a perfect dough, which needs yeast, flour, water, and salt. "
"The sauce is typically tomato-based, seasoned with herbs like oregano and basil. "
"Toppings can vary from simple mozzarella to a wide range of meats and vegetables. "
"Finally, let's consider the solar system. "
"It is a gravitationally bound system of the Sun and the objects that orbit it. "
"The largest objects are the eight planets, in order from the Sun: Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, and Neptune."
)
docs = text_splitter.create_documents([long_text])
for i, doc in enumerate(docs):
print(f"--- Chunk {i+1} ---")
print(doc.page_content)
print()
ajuste de parâmetros:SemanticChunker A eficácia do programa é altamente dependente dos breakpoint_threshold_amountEsse limite controla a "sensibilidade à mudança semântica". Esse limite controla a "sensibilidade à mudança semântica". Um limite baixo produz um grande número de pedaços pequenos e coesos, enquanto um limite alto corta somente quando há uma mudança significativa no tópico. A experimentação precisa ser repetida com base no conteúdo do documento.
Agrupamento baseado em temas
- ideia centralUso de modelos temáticos (por exemplo
LDA) ou algoritmos de clustering que cortam e analisam documentos à medida que seus macrotemas mudam. - Cenários aplicáveisRelatórios ou livros longos e com vários assuntos.
import numpy as np
import re
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
import nltk
from nltk.corpus import stopwords
try:
stopwords.words('english')
except LookupError:
nltk.download('stopwords')
def lda_topic_chunking(text: str, n_topics: int = 3) -> list[str]:
# 1. Preprocessing: Treat each paragraph as a "document"
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
if len(paragraphs) <= 1:
return [text]
cleaned_paragraphs = [re.sub(r'[^a-zA-Z\s]', '', p).lower() for p in paragraphs]
# 2. Bag of Words + Stopword Removal
vectorizer = CountVectorizer(min_df=1, stop_words=stopwords.words('english'))
X = vectorizer.fit_transform(cleaned_paragraphs)
if X.shape == 0:
return paragraphs
# 3. LDA Topic Modeling
lda = LatentDirichletAllocation(n_components=n_topics, random_state=42)
lda.fit(X)
# 4. Determine dominant topic for each paragraph
topic_dist = lda.transform(X)
dominant_topics = np.argmax(topic_dist, axis=1)
# 5. Chunking based on topic changes
chunks = []
current_chunk_paragraphs = []
current_topic = dominant_topics
for i, paragraph in enumerate(paragraphs):
if dominant_topics[i] == current_topic:
current_chunk_paragraphs.append(paragraph)
else:
chunks.append("\n\n".join(current_chunk_paragraphs))
current_chunk_paragraphs = [paragraph]
current_topic = dominant_topics[i]
chunks.append("\n\n".join(current_chunk_paragraphs))
return chunks
tomar nota deO método de chunking baseado em tópicos é muito sensível ao comprimento do texto, à diferenciação de tópicos e às etapas de pré-processamento, e requer um número predefinido de tópicos. Esse método é mais adequado como uma ferramenta exploratória em documentos longos com limites claros de tópicos.
Estratégia de fragmentação avançada
De pequeno a grande porte
- ideia centralRecuperação de alta precisão usando pequenos pedaços (por exemplo, frases) e, em seguida, alimentando o pedaço original (por exemplo, parágrafo) que contém o pedaço como um contexto para o programa de recuperação de dados.
LLM. Ele combina a alta precisão de recuperação de pequenos blocos com o rico contexto de grandes blocos. - Cenários aplicáveisPerguntas e respostas: cenários complexos de perguntas e respostas que exigem alta precisão de recuperação e contexto de geração rico.
在 LangChain Médio.ParentDocumentRetriever implementa essa ideia. Ele gerencia dois fluxos de processamento paralelo em segundo plano:
- Dividir o documento em grandes "blocos pai".
- Cada bloco pai é dividido em "blocos filhos" menores.
- Criar índices de vetores somente para sub-blocos.
- A pesquisa é realizada primeiro encontrando o sub-bloco relevante e, em seguida, por um
docstoreA extração de seus blocos pai correspondentes é retornada aoLLM。
# from langchain.embeddings import OpenAIEmbeddings
# from langchain_text_splitters import RecursiveCharacterTextSplitter
# from langchain.retrievers import ParentDocumentRetriever
# from langchain_community.document_loaders import TextLoader
# from langchain_chroma import Chroma
# from langchain.storage import InMemoryStore
# Assume 'docs' are loaded documents
# parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# vectorstore = Chroma(embedding_function=OpenAIEmbeddings(), collection_name="split_parents")
# store = InMemoryStore() # This store holds the parent documents
# retriever = ParentDocumentRetriever(
# vectorstore=vectorstore,
# docstore=store,
# child_splitter=child_splitter,
# parent_splitter=parent_splitter,
# )
# retriever.add_documents(docs)
# sub_docs = vectorstore.similarity_search("query") # Retrieves small chunks
# retrieved_docs = retriever.get_relevant_documents("query") # Retrieves large parent chunks
# print(retrieved_docs.page_content)
Chunking de agente
- ideia central: Usando um
LLMAgentpara simular o processo de compreensão de leitura humana e determinar dinamicamente os limites dos blocos. Por exemplo, a dicaLLMDividir um texto em vários "blocos de conhecimento autônomos". - Cenários aplicáveisProjetos experimentais ou que lidam com textos altamente complexos e não estruturados. Extremamente caro, estabilidade a ser comprovada.
import textwrap
# from langchain_openai import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
class KnowledgeChunk(BaseModel):
chunk_title: str = Field(description="A concise title for this knowledge chunk.")
chunk_text: str = Field(description="A self-contained text extracted and synthesized from the original paragraph.")
representative_question: str = Field(description="A typical question that can be answered by this chunk.")
class ChunkList(BaseModel):
chunks: List[KnowledgeChunk]
parser = PydanticOutputParser(pydantic_object=ChunkList)
prompt_template = """
[ROLE]: You are a top-tier document analyst. Your task is to decompose complex text into a set of core, self-contained "Knowledge Chunks".
[TASK]: Read the provided text, identify the distinct core concepts, and create a knowledge chunk for each.
[RULES]:
1. Self-Contained: Each chunk must be understandable on its own.
2. Single Concept: Each chunk should focus on only one core idea.
3. Extract and Restructure: Pull all relevant sentences for a concept and combine them into a coherent paragraph.
4. Follow Format: Strictly adhere to the JSON format instructions below.
{format_instructions}
[TEXT TO PROCESS]:
{paragraph_text}
"""
prompt = PromptTemplate(
template=prompt_template,
input_variables=["paragraph_text"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# The following part is a simulation, as it requires a running LLM model.
# model = ChatOpenAI(model="gpt-4", temperature=0.0)
# chain = prompt | model | parser
# result = chain.invoke({"paragraph_text": document_text})
Chunking misto: equilíbrio entre eficiência e qualidade
Na prática, é difícil lidar com todas as situações com uma única estratégia. O chunking misto é uma técnica muito prática.
- ideia centralFatiamento de granulação grossa com uma macroestratégia (por exemplo, chunking estruturado) seguido de fatiamento secundário de pedaços grandes demais usando uma estratégia mais fina (por exemplo, chunking recursivo).
- Cenários aplicáveisLida com documentos com estruturas complexas e densidade de conteúdo desigual.
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
from langchain_core.documents import Document
markdown_document = """
# Chapter 1: Company Profile
Our company was founded in 2017...
## 1.1 Development History
The company has experienced rapid growth...
# Chapter 2: Core Technology
This chapter describes our core technologies in detail. Our framework is based on advanced distributed computing concepts... (A very long paragraph with multiple sentences describing different technical aspects like CNNs, Transformers, data pipelines, etc.)
## 2.1 Technical Principles
Our principles combine statistics, machine learning...
# Chapter 3: Future Outlook
Looking ahead, we will continue to invest in AI...
"""
def hybrid_chunking(
markdown_document: str,
coarse_chunk_threshold: int = 400,
fine_chunk_size: int = 100,
fine_chunk_overlap: int = 20
) -> list[Document]:
# 1. Coarse-grained splitting by structure
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
coarse_chunks = markdown_splitter.split_text(markdown_document)
# 2. Fine-grained recursive splitter for oversized chunks
fine_splitter = RecursiveCharacterTextSplitter(
chunk_size=fine_chunk_size,
chunk_overlap=fine_chunk_overlap
)
final_chunks = []
for chunk in coarse_chunks:
if len(chunk.page_content) > coarse_chunk_threshold:
# If a chunk is too large, split it further
finer_chunks = fine_splitter.split_documents([chunk])
final_chunks.extend(finer_chunks)
else:
final_chunks.append(chunk)
return final_chunks
final_chunks = hybrid_chunking(markdown_document)
for i, chunk in enumerate(final_chunks):
print(f"--- Final Chunk {i+1} (Length: {len(chunk.page_content)}) ---")
print(f"Metadata: {chunk.metadata}")
print(chunk.page_content)
print("-" * 80)
Como escolher a melhor estratégia de divisão em blocos?
Diante de uma infinidade de estratégias, é mais importante escolher um caminho razoável do que experimentá-las uma a uma. Recomenda-se que a seguinte estrutura hierárquica de tomada de decisão seja seguida.
Etapa 1: Comece com uma estratégia de linha de base
- opção padrão:
RecursiveCharacterTextSplitter. Esse é o lugar mais seguro para começar, independentemente do tipo de texto que está sendo processado. Use-o para estabelecer uma linha de base de desempenho.
Etapa 2: Examinar os recursos estruturados
- opção de prioridadeChunking com reconhecimento de estrutura. Se o documento tiver uma estrutura explícita (
MarkdownTítulo,HTML), alterne para a guiaMarkdownHeaderTextSplittere outros métodos. Essa é a otimização com o menor custo e os benefícios mais óbvios.
Etapa 3: Quando a precisão se torna o gargalo
- Opções avançadasChunking semântico ou chunking pequeno-grande. Se os resultados de recuperação das estratégias básicas e estruturadas ainda forem insatisfatórios, isso indica a necessidade de informações semânticas de maior dimensão.
SemanticChunkerPara cenários que exigem um alto grau de consistência semântica em um bloco.ParentDocumentRetriever(pedaços pequenos e grandes): adequado tanto para a precisão da pesquisa quanto para a necessidade de fornecer um entendimento mais claro para o usuário.LLMCenários complexos de perguntas e respostas que fornecem contexto completo.
Etapa 4: Lidando com documentos extremamente complexos
- Prática avançadaChunking híbrido. Para documentos com estruturas complexas e densidade de conteúdo desigual, o chunking híbrido é a melhor prática para equilibrar custo e eficácia.
A tabela a seguir resume todas as estratégias de fragmentação discutidas.
| estratégia de fragmentação | Lógica central | vantagem | Desvantagens e custos |
|---|---|---|---|
| Chunking de comprimento fixo | por um número fixo de caracteres ou token parte de um número (por exemplo, decimal ou numeral romano) |
Simples e rápido de implementar | Destrói facilmente a semântica e é o menos eficaz |
| fragmentação recursiva | Corte recursivo por separadores predefinidos (parágrafos, frases) | Versatilidade, melhor preservação da estrutura | Bastante eficaz em documentos irregulares |
| Chunking baseado em frases | Frases como a menor unidade, depois combinadas em blocos | Garantir a integridade da sentença | O contexto de uma única frase pode ser insuficiente; é necessário lidar com frases longas |
| Chunking estruturado | Usar a estrutura inerente do documento (por exemplo, cabeçalhos) para cortar e dividir | Lógico e claro no contexto | Forte dependência do formato do documento, não genérico |
| fragmentação semântica | Fatiamento baseado em alterações de similaridade semântica local | Alta coesão de conceitos em um bloco, alta precisão de recuperação | Altos custos computacionais (Embedding cálculos), com base na qualidade do modelo |
| Agrupamento baseado em temas | Fatiamento por limites de tópicos globais usando modelos de tópicos | As informações dentro do bloco são altamente correlacionadas | Implementação complexa, sensível a dados e parâmetros, resultados instáveis |
| fragmentação híbrida | Macrossegmentação + microssegmentação | Equilíbrio entre eficiência e qualidade e praticidade | Lógica de implementação mais complexa |
| pedaços pequenos e grandes | Blocos pequenos para recuperação, blocos grandes para geração | Combina pesquisa de alta precisão com contexto avançado | Complexidade do pipeline, necessidade de gerenciar dois conjuntos de índices, dobrando os custos de armazenamento |
| Chunking de proxy | AI Documentação de análise e divisão da dinâmica do agente |
Teoricamente ideal | Experimental e extremamente caro (API chamada) com um grande atraso |
































