



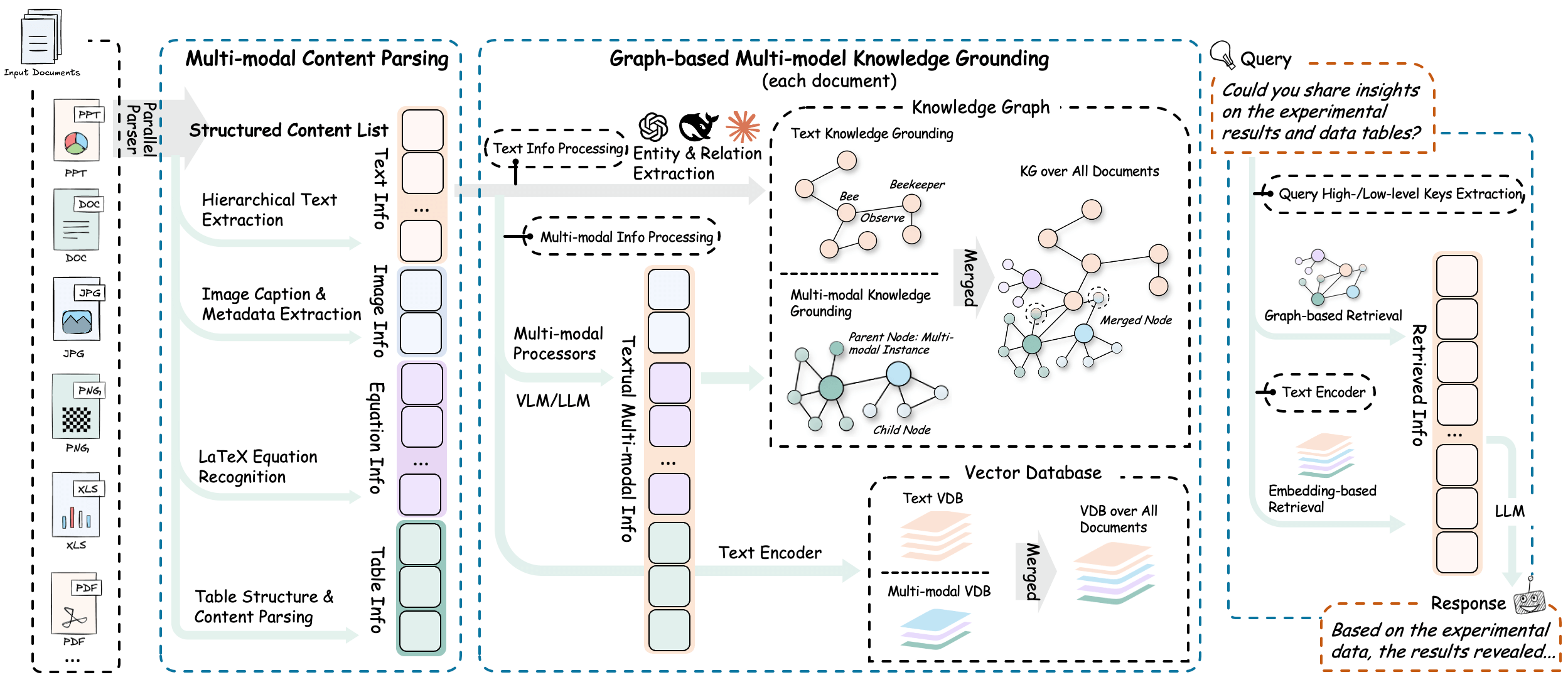
O RAG-Anything é um programa baseado em LightRAG Processamento de documentos multimodais totalmente integrado RAG Sistema. A maioria dos sistemas tradicionais de perguntas e respostas (RAG) só consegue lidar com conteúdo de texto simples, mas os documentos com os quais entramos em contato diariamente, como PDFs, documentos do Word ou apresentações, geralmente contêm vários tipos de conteúdo, como texto, imagens, tabelas, fórmulas etc. Se apenas o texto for extraído, muitas informações importantes serão perdidas. Se apenas o texto for extraído, muitas informações importantes serão perdidas. O RAG-Anything resolve esse problema analisando completamente esses documentos complexos que contêm vários elementos, sejam eles textos, imagens, tabelas ou fórmulas matemáticas, que podem ser reconhecidos e compreendidos com precisão. Ele desmonta e analisa todos os elementos do documento e, em seguida, constrói um gráfico de conhecimento para que, quando você fizer uma pergunta, o sistema não apenas compreenda o texto, mas também leia o conteúdo das imagens e analise os dados da tabela. Dessa forma, ele pode dar uma resposta mais abrangente e precisa com base em todas as informações do documento. Esse sistema é particularmente adequado para lidar com documentos com diversas informações, como artigos acadêmicos, manuais técnicos e relatórios financeiros.
Lista de funções
- Processo de tratamento integradoO processo inteiro, desde o upload do documento, a análise até a pergunta e a resposta inteligente final, é completo e automatizado.
- Suporte a vários formatos de arquivoOs usuários podem fazer upload de PDF, Word, PPT, Excel, imagens e muitos outros formatos comuns para processamento.
- Analisador de conteúdo dedicadoO sistema tem ferramentas integradas projetadas especificamente para reconhecer e compreender diferentes conteúdos, como imagens, tabelas, fórmulas matemáticas e assim por diante.
- Criação de um gráfico de conhecimento multimodalExtrai automaticamente informações importantes de documentos e estabelece links entre textos, imagens, tabelas e outros conteúdos para formar uma rede de conhecimento.
- Modos de processamento flexíveisOs usuários podem optar por deixar o sistema analisar todo o documento automaticamente ou dar ao sistema acesso direto ao que já foi organizado.
- Pesquisa inteligente híbridaQuando estiver procurando respostas, o sistema combina a correspondência de palavras-chave e a compreensão contextual para localizar as informações com mais precisão.
- Consulta aprimorada do modelo de linguagem visualQuando um usuário faz uma pergunta que envolve uma imagem, o sistema invoca automaticamente um modelo visual para analisar o conteúdo da imagem e obter uma resposta gráfica combinada.
Usando a Ajuda
O RAG-Anything é uma ferramenta avançada que analisa documentos contendo texto, imagens, tabelas e muito mais, e permite que você interaja com esses documentos fazendo perguntas. Veja abaixo um procedimento detalhado de instalação e uso.
I. Instalação
Há duas maneiras de instalar o RAG-Anything, sendo que a primeira é recomendada por ser mais simples.
Caminho 1: Instalar diretamente do PyPI (recomendado)
Essa é a maneira mais rápida de instalar. Abra o terminal ou a ferramenta de linha de comando e digite o seguinte comando:
# 基础安装
pip install raganything
Esse comando básico instala apenas a funcionalidade principal. Os documentos modernos vêm em vários formatos e, para que ele possa lidar com mais tipos de arquivos, você pode instalar pacotes de recursos adicionais, conforme necessário.
- Se você quiser que ele manipule todos os tipos de arquivos suportados (recomendado):
pip install 'raganything[all]' - Se você só precisa trabalhar com formatos de imagem (por exemplo, BMP, TIFF, GIF, etc.):
pip install 'raganything[image]' - Se você só precisa trabalhar com arquivos de texto simples (por exemplo, TXT, MD):
pip install 'raganything[text]'
Maneira 2: Instalar a partir do código-fonte
Se você quiser estudar seu código ou fazer um desenvolvimento secundário, esse é o caminho a seguir.
- Primeiro, clone o código do GitHub em seu computador:
git clone https://github.com/HKUDS/RAG-Anything.git - Vá para o catálogo de projetos:
cd RAG-Anything - Em seguida, instale-o via pip:
pip install -e . - Novamente, use esse comando se você precisar oferecer suporte a todos os formatos de arquivo:
pip install -e '.[all]'
II. configuração ambiental
1. instalar o LibreOffice
O RAG-Anything trabalha com documentos do Office (por exemplo, .docx, .pptx, .xlsx) com a ajuda do LibreOffice, um software de escritório gratuito. Primeiro, é necessário instalá-lo em seu sistema operacional.
- Windows: Ir para Site oficial do LibreOfficeFaça o download e instale.
- macOSInstalação: É fácil instalar usando o Homebrew, o comando é
brew install --cask libreoffice。 - Ubuntu/Debian:: Uso de comandos
sudo apt-get install libreoffice。
2) Configurar a chave da API
O RAG-Anything precisa chamar um modelo de linguagem grande (LLM), como a família de modelos GPT da OpenAI, ao compreender o conteúdo e gerar respostas. Você precisa de uma chave de API.
Na pasta do projeto, crie um arquivo chamado .env copie o seguinte e substitua-o por suas próprias informações-chave.
OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxxxxxx"
# 如果你使用代理或者第三方服务,还需要配置这个地址
OPENAI_BASE_URL="https://api.your-proxy.com/v1"
III Métodos de uso
Abaixo, apresentamos um exemplo completo de como processar um documento e fazer perguntas usando o RAG-Anything.
1. trabalho preparatório
Primeiro, verifique se você tem o RAG-Anything instalado e configurado com uma chave de API. Em seguida, prepare um documento com o qual você deseja trabalhar, como um arquivo chamado report.pdf do documento.
2. escrever código
Crie um arquivo Python, por exemplo main.pye, em seguida, copie o código a seguir para ele. Esse código demonstra o processo completo, desde a configuração e o processamento de documentos até a realização de perguntas.
import asyncio
from raganything import RAGAnything, RAGAnythingConfig
from lightrag.llm.openai import openai_complete_if_cache, openai_embed
from lightrag.utils import EmbeddingFunc
# 异步函数是现代Python中处理高并发任务的方式
async def main():
# 1. 设置你的API密钥和代理地址
api_key = "your-api-key" # 替换成你的 OpenAI API Key
base_url = "your-base-url" # 如果有代理,替换成你的代理地址
# 2. 配置 RAG-Anything 的工作方式
config = RAGAnythingConfig(
working_dir="./rag_storage", # 指定一个文件夹,用来存放处理后的数据
parser="mineru", # 使用mineru解析器
parse_method="auto", # 自动判断解析方式
enable_image_processing=True, # 启用图片处理
enable_table_processing=True, # 启用表格处理
)
# 3. 定义与大语言模型交互的函数
# 文本模型,用于生成回答
def llm_model_func(prompt, **kwargs):
return openai_complete_if_cache(
"gpt-4o-mini",
prompt,
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 视觉模型,用于理解图片内容
def vision_model_func(prompt, image_data=None, **kwargs):
return openai_complete_if_cache(
"gpt-4o",
"",
messages=[{"role": "user", "content": [{"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}]}],
api_key=api_key,
base_url=base_url,
**kwargs,
)
# 嵌入模型,用于将文本转换成向量,方便计算机理解和检索
embedding_func = EmbeddingFunc(
embedding_dim=3072,
func=lambda texts: openai_embed(
texts, model="text-embedding-3-large", api_key=api_key, base_url=base_url
),
)
# 4. 初始化 RAG-Anything 系统
rag = RAGAnything(
config=config,
llm_model_func=llm_model_func,
vision_model_func=vision_model_func,
embedding_func=embedding_func,
)
# 5. 处理你的文档
# 将 "path/to/your/document.pdf" 替换成你自己的文件路径
await rag.process_document_complete(
file_path="path/to/your/document.pdf",
output_dir="./output"
)
# 6. 开始提问
print("文档处理完成,现在可以开始提问了。")
# 示例问题:一个纯文本问题
text_result = await rag.aquery(
"请总结一下这份文档的核心观点,并分析图表传达了哪些主要信息?",
mode="hybrid" # hybrid模式会结合多种方式检索,结果更准
)
print("问题的回答:", text_result)
if __name__ == "__main__":
asyncio.run(main())
3. executar o código
Altere o código na seção your-api-key、your-base-url 和 path/to/your/document.pdf Substitua-o por suas próprias informações reais. Em seguida, execute o arquivo no terminal:
python main.py
Primeiro, o programa fará o download dos modelos necessários e, em seguida, começará a analisar os documentos que você especificar. Esse processo pode durar alguns minutos, dependendo do tamanho e da complexidade do documento. Quando o processo for concluído, ele imprimirá as respostas às perguntas que você fez.
Este exemplo mostra o uso principal do RAG-Anything. Ele também oferece suporte a recursos mais avançados, como processamento em lote de pastas inteiras de documentos, transmissão direta de conteúdo analisado ou perguntas sobre imagens ou tabelas específicas, portanto, consulte a documentação oficial para explorar esses usos avançados.
cenário do aplicativo
- pesquisa acadêmica
Quando os pesquisadores leem um grande número de artigos, muitas vezes precisam lidar com arquivos PDF que contêm diagramas complexos, fórmulas matemáticas e texto. O RAG-Anything pode analisar esses artigos completamente, ajudando os pesquisadores a localizar rapidamente as principais informações, entender diagramas de resultados experimentais e comparar dados de diferentes artigos, melhorando muito a eficiência da análise da literatura e da organização dos dados. - Gestão do conhecimento empresarial
Normalmente, as empresas têm um grande número de manuais técnicos, relatórios financeiros, análises de mercado e apresentações internas. Esses documentos estão em diferentes formatos e têm conteúdos variados. O RAG-Anything cria uma base de conhecimento corporativo unificada em que os funcionários podem fazer perguntas diretamente em linguagem natural, como "Verifique o gráfico dos dados de vendas do terceiro trimestre do ano passado" ou "Mostre-me a arquitetura técnica do produto XX", e o sistema encontrará e apresentará as informações relevantes de diferentes documentos. O sistema pode localizar e apresentar com precisão informações relevantes de diferentes documentos. - Profissões financeiras e jurídicas
Os analistas financeiros e advogados precisam ler longos relatórios e documentos contratuais repletos de tabelas de dados, cláusulas e gráficos. O RAG-Anything os ajuda a extrair rapidamente os principais dados, identificar cláusulas específicas em contratos e analisar tabelas em demonstrações financeiras para ajudá-los a tomar decisões mais precisas. - Educação e aprendizado
Alunos e professores podem usar o RAG-Anything para trabalhar com livros didáticos, material didático e materiais de aprendizagem. Os alunos podem carregar um PDF do material didático e fazer perguntas sobre os diagramas e conceitos contidos nele, e o sistema pode fornecer explicações detalhadas. Os professores também podem usá-lo para criar rapidamente materiais de perguntas e respostas ou para reunir recursos de ensino de diferentes fontes.
QA
- Qual é a diferença entre o RAG-Anything e outras ferramentas normais do RAG?
A maior diferença é que o RAG-Anything pode lidar com conteúdo multimodal. As ferramentas RAG comuns geralmente só conseguem extrair e entender o texto simples em um documento, ignorando informações não textuais, como imagens, tabelas, fórmulas e assim por diante. O RAG-Anything, por outro lado, foi especialmente projetado para reconhecer esse tipo de conteúdo, podendo ler imagens e analisar dados de tabelas, o que proporciona uma compreensão mais abrangente de todo o documento e, portanto, fornece respostas mais precisas e completas. - Por que é necessário instalar o LibreOffice ao trabalhar com documentos do Office (Word, PPT)?
O RAG-Anything em si não analisa diretamente a formatação complexa dos documentos do Office, mas, em vez disso, recorre ao LibreOffice, um poderoso software de escritório de código aberto. Ele usa o LibreOffice para converter arquivos como .docx, .pptx etc. em um formato intermediário que é mais padrão e mais fácil de trabalhar antes da extração e análise do conteúdo. Portanto, o LibreOffice é uma dependência de front-end para o processamento desses arquivos. - Essa ferramenta é gratuita? Há algum custo para usá-la?
O projeto RAG-Anything em si é de código aberto e gratuito, e você pode baixar e usar seu código livremente. No entanto, ele precisa chamar APIs para Large Language Models (LLM) e Embedding Models (EMM) durante sua operação, como o GPT-4o da OpenAI. Esses serviços de API geralmente são cobrados por uso. Portanto, seu custo vem principalmente do custo de chamar essas APIs de terceiros. - Se eu tiver fórmulas escritas à mão ou gráficos pouco claros em meu documento, ele poderá lidar com eles?
Os resultados do processamento dependem da clareza do conteúdo. Para fórmulas matemáticas impressas e diagramas claros, ele tem uma alta precisão de reconhecimento. No entanto, se os diagramas estiverem muito borrados ou se as fórmulas estiverem escritas à mão, o módulo de OCR (Optical Character Recognition, reconhecimento óptico de caracteres) do sistema poderá ter dificuldade em reconhecê-las com precisão, o que afetará a compreensão final e os resultados de Q&A.































