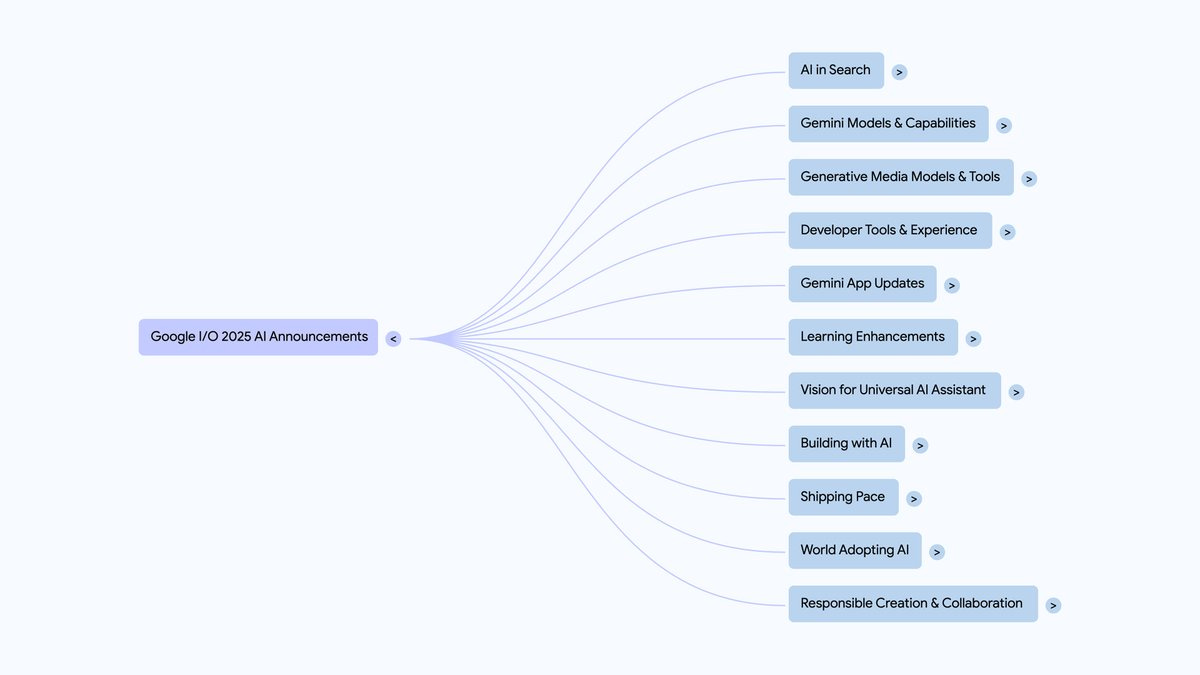
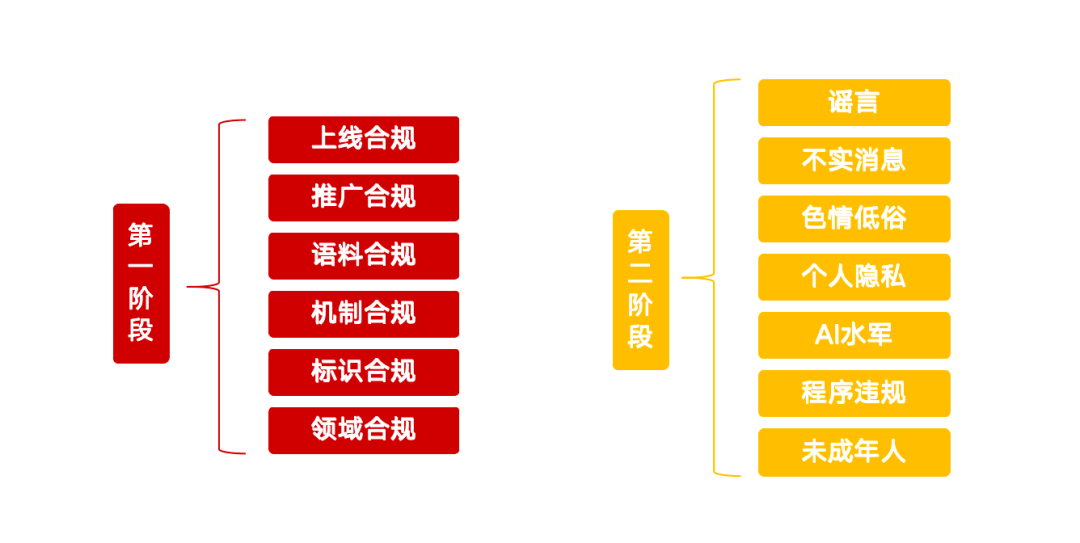
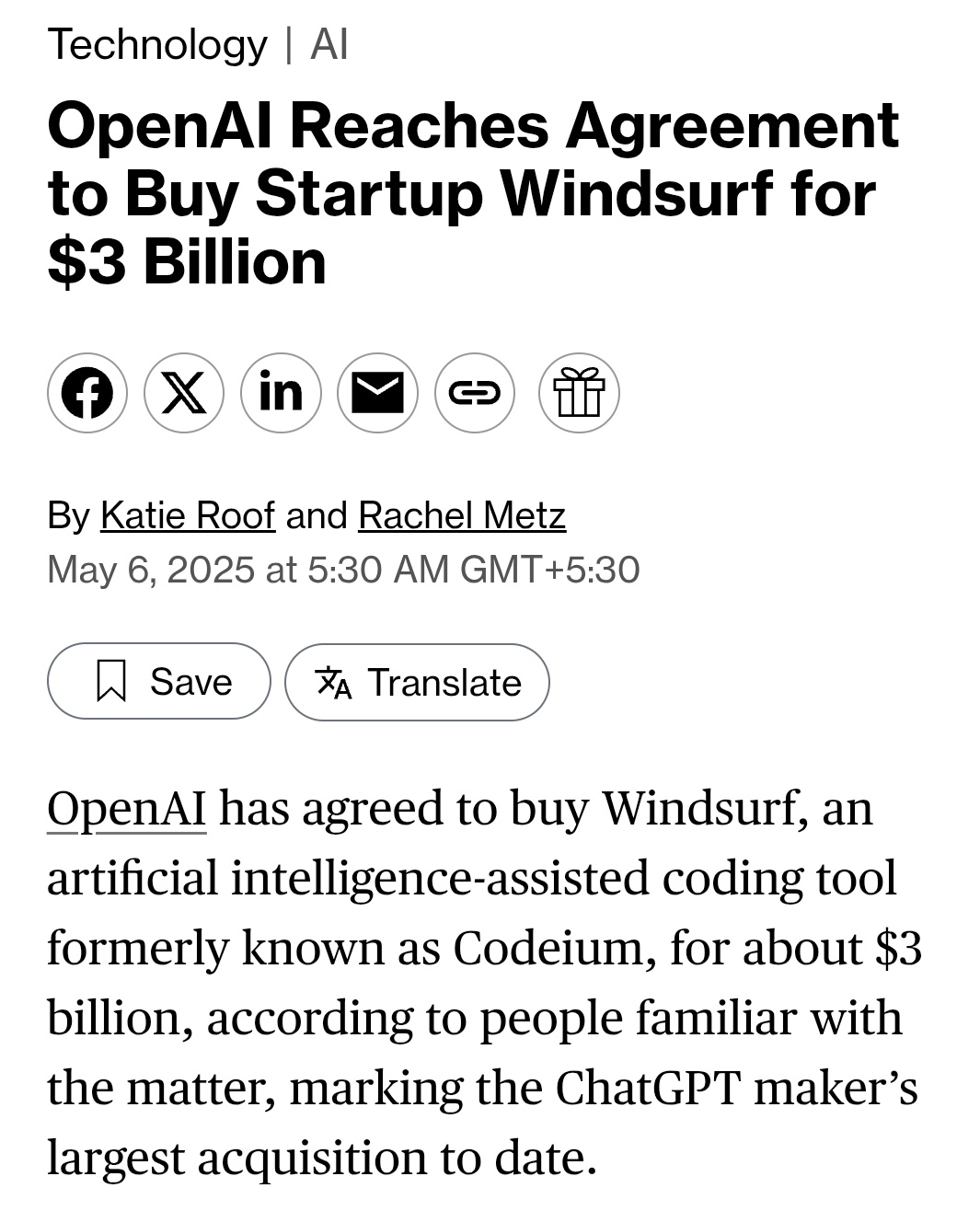
Vamos começar o ano novo de uma maneira empolgante!

- Pode ser gerado pelo GPT-5
E se eu lhe dissesse que o GPT-5 é real? Ele não apenas é real, mas já está moldando o mundo de maneiras que você não pode ver. Aqui está uma hipótese: a OpenAI desenvolveu o GPT-5, mas está mantendo-o internamente porque o ROI é muito maior do que abri-lo para milhões de pessoas. ChatGPT usuários. Além disso, o ROI que eles obtêm do Não é dinheiro. Em vez disso, é outra coisa. Como você pode ver, a ideia é bastante simples; o desafio é juntar as pistas que apontam para ela. Este artigo explica por que acho que essas pistas acabam se conectando.
Aviso prévio: isso é pura especulação. As evidências são todas de domínio público, mas não há vazamentos ou rumores internos que confirmem que estou correto. Na verdade, estou construindo essa teoria por meio deste artigo, não apenas compartilhando-a. Não tenho informações privilegiadas e, mesmo que tivesse, estou vinculado a um contrato de confidencialidade. Essa hipótese é convincente porque lógico . Honestamente, o que mais eu preciso para iniciar essa máquina de boatos?
Se você acredita ou não, depende de você. Mesmo que eu esteja errado - e eventualmente saberemos a resposta - acho que é um jogo de detetive divertido. Convido-o a participar de especulações na seção de comentários, mas seja construtivo e atencioso. Não deixe de ler o artigo inteiro primeiro. Fora isso, todo debate é bem-vindo.
I. O misterioso desaparecimento do Opus 3.5
Antes de explorar o GPT-5, temos que mencionar seu primo distante igualmente desaparecido: o Anthropic Claude Opus 3.5.
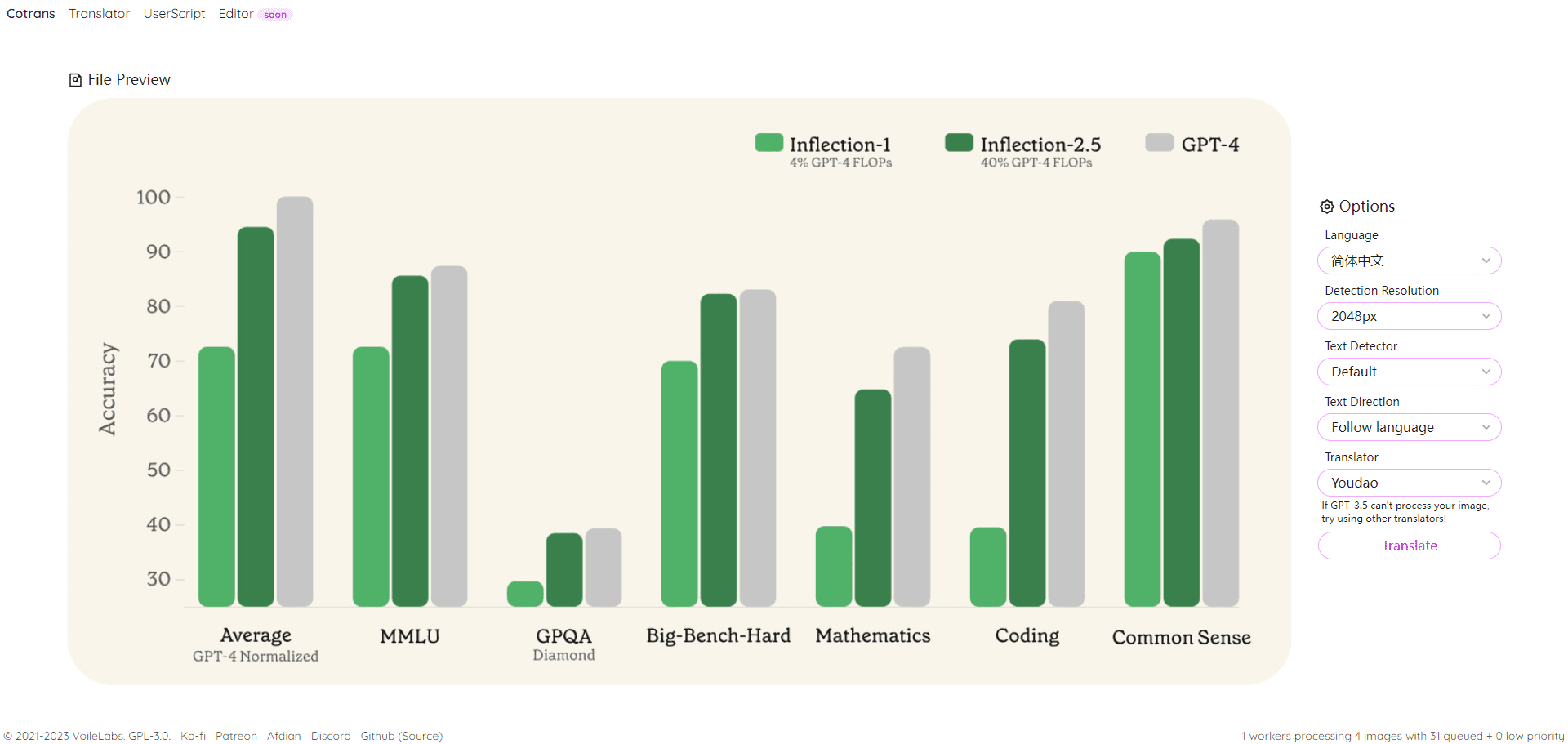
Como você sabe, os três principais laboratórios de IA - OpenAI, Google DeepMind e Anthropic - oferecem portfólios de modelos que cobrem o espectro de preço/latência versus desempenho, GPT-4o mini, bem como o1 e o1-mini; o Google DeepMind oferece Gêmeos Ultra, Pro e Flash; a Anthropic tem o Claude Opus, o Sonnet e o Haiku, e o objetivo é claro: abranger o maior número possível de perfis de clientes. Alguns estão buscando o melhor desempenho, independentemente do custo, enquanto outros precisam de soluções acessíveis e adequadas. Tudo isso faz sentido.
Mas, em outubro de 2024, algo estranho aconteceu. Enquanto todos estavam esperando Antrópica Quando lançaram o Claude Opus 3.5 como resposta ao GPT-4o (que foi lançado em maio de 2024), lançaram uma versão atualizada do Claude Sonnet 3.5 (que ficou conhecido como Sonnet 3.6) em 22 de outubro, que desapareceu, deixando o Anthropic sem um produto em concorrência direta com o GPT-4o. GPT-4o. Estranho, não é? Aqui está uma rápida olhada na linha do tempo do Opus 3.5:
- 10 月 28 日,我在周评文章中写道:”[有] 传闻称 Sonnet 3.6 是…备受期待的 Opus 3.5 训练失败过程中产生的中间检查点。”同日,r/ClaudeAI 子论坛出现帖子:”Claude 3.5 Opus 已被废弃”,链接指向Anthropic 模型页面——至今仍无 Opus 3.5 的踪影。有人推测此举是为在新一轮融资前维持投资者信心。
- 11 月 11 日,Anthropic CEO Dario Amodei 在 Lex Fridman 播客中放弃 Opus 3.5:”虽然不能给出确切日期,但我们仍计划推出 Claude 3.5 Opus。” 措辞谨慎暧昧,但确有效力。
- 11 月 13 日,彭博社证实早期传闻:”训练完成后,Anthropic 发现 3.5 Opus 在评估中优于旧版,但考虑到模型规模和构建运行成本,提升幅度未达预期。” Dario 未给出日期,似乎是因为尽管 Opus 3.5 训练未失败,但成果不尽如人意。注意重点是 Relação entre custo e desempenho Não apenas o desempenho.
- 12 月 11 日,半导体专家 Dylan Patel 及其 Semianalysis 团队带来最终转折,提出解释:”Anthropic 完成 Claude 3.5 Opus 训练且表现良好…但未发布。因为他们转而 Geração de dados de síntese com o Claude 3.5 Opus ,通过奖励建模显著提升 Claude 3.5 Sonnet。”
Em resumo, a Anthropic treinou o Claude Opus 3.5 e abandonou o nome porque os resultados não foram bons o suficiente. O Dario acredita que os resultados poderiam ter sido melhorados com um processo de treinamento diferente e evita a data. A Bloomberg confirma que ele supera os modelos existentes, mas que o custo de inferência (o custo para o usuário de usar o modelo) é inacessível, e a equipe de Dylan revela a conexão entre o Sonnet 3.6 e o Opus 3.5 ausente: o último foi usado para gerar internamente dados sintéticos para melhorar o desempenho do primeiro.
Todo o processo pode ser esquematizado da seguinte forma:

II. melhor, menor e mais barato?
O processo de usar um modelo forte e caro para gerar dados para aumentar um modelo um pouco mais fraco, porém mais econômico, é chamado de destilação. Essa é uma prática comum. A técnica permite que os laboratórios de IA ultrapassem as limitações do pré-treinamento sozinho e aumentem o desempenho de modelos menores.
蒸馏有不同方法,但我们不深入探讨。关键要记住:作为”教师”的强模型能将”学生”模型从[小、便宜、快速] + (após um decimal ou fração) ligeiramente menor que Transformado em [pequeno, barato, rápido] + formidável . Dylan explica por que isso faz sentido para a combinação Opus 3.5-Sonnet 3.6 da Anthropic:
(O custo de inferência (do novo Sonnet em relação ao antigo) não mudou significativamente, mas o desempenho do modelo melhorou. Por que se preocupar em lançar o 3.5 Opus do ponto de vista do custo quando se pode obter o 3.5 Sonnet por meio do pós-treinamento com o 3.5 Opus?
Voltando à questão do custo: a destilação controla as despesas de inferência e, ao mesmo tempo, melhora o desempenho. Isso aborda diretamente o problema central relatado pela Bloomberg, e a Anthropic optou por não lançar o Opus 3.5 não apenas por causa de seus resultados sem brilho, mas também por causa de seu valor interno mais alto. (Dylan ressalta que é por isso que a comunidade de código aberto está rapidamente alcançando o GPT-4 - eles estão pegando ouro diretamente da mina de ouro da OpenAI).
A revelação mais surpreendente... O Soneto 3.6 não é apenas excelente - ele alcança o nível superior . Além do GPT-4o, o modelo de médio porte da Anthropic supera o carro-chefe da OpenAI ao destilar o Opus 3.5 (e provavelmente por outros motivos; cinco meses é tempo suficiente em IA). De repente, a percepção de alto custo como sinônimo de alto desempenho começou a se desfazer.
“越大越好”的时代怎么了?OpenAI CEO Sam Altman 警告那个时代已结束。我也撰文讨论。当顶尖实验室开始保密,他们停止分享参数数量。参数规模不再可靠,我们明智地转向关注基准表现。OpenAI 最后公开的参数规模是 2020 年 GPT-3 的 1750 亿。2023 年 6 月传闻称 GPT-4 是约1.8 万亿参数的混合专家模型。Semianalysis 后续详细评估确认 GPT-4 有 1.76 万亿参数,当时是 2023 年 7 月。
Até dezembro de 2024 - daqui a um ano e meio - Ege Erdil, pesquisador da EpochAI, uma organização focada no impacto futuro da IA, estima que as escalas de parâmetros dos modelos de fronteira, incluindo GPT-4o e Sonnet 3.6, são significativamente menores do que o GPT-4 (embora ambos os benchmarks superem o GPT-4):
…当前前沿模型如初代 GPT-4o 和 Claude 3.5 Sonnet 可能比 GPT-4 小一个数量级,4o 约 2000 亿参数,3.5 Sonnet 约 4000 亿…尽管估算方式粗糙可能导致误差达两倍。
Ele explica detalhadamente como chegou a esse número sem que o laboratório divulgasse detalhes arquitetônicos, mas isso não é importante para nós. O ponto é que a névoa está se dissipando: o Anthropic e o OpenAI parecem estar seguindo trajetórias semelhantes. Seus modelos mais recentes não são apenas melhores, mas também são menores e mais baratos do que os anteriores. Sabemos que a Anthropic fez isso ao destilar o Opus 3.5. Mas o que a OpenAI fez?

III. os laboratórios de IA são movidos pelo universalismo
Pode-se pensar que a estratégia de destilação da Anthropic decorre de uma situação única, ou seja, os resultados ruins do treinamento do Opus 3.5. Mas a realidade é que a situação da Anthropic não é única, e os últimos resultados de treinamento do Google DeepMind e da OpenAI são igualmente insatisfatórios. (Observe que resultados ruins não são o mesmo que O modelo é pior. ) Os motivos não nos interessam: retornos decrescentes devido à insuficiência de dados, limitações inerentes à arquitetura do Transformer, platô da lei de escalonamento pré-treinamento etc. De qualquer forma, o contexto particular do Anthropic é, na verdade, universal.
Mas lembre-se do que a Bloomberg informa: as métricas de desempenho são tão boas quanto o custo. Esse é outro fator compartilhado? Sim, e Ege explica o motivo: o aumento da demanda após o boom do ChatGPT/GPT-4. A IA generativa está se espalhando em um ritmo que torna difícil para os laboratórios sustentarem as perdas da expansão contínua. Isso os forçou a reduzir os custos de inferência (o treinamento é apenas uma vez, os custos de inferência aumentam com o volume e o uso do usuário). Se 300 milhões de usuários estiverem usando o produto toda semana, as despesas operacionais poderão ser fatais de repente.
Os fatores que levaram a Anthropic a aprimorar o Sonnet 3.6 com a destilação estão afetando a OpenAI com intensidade exponencial. A destilação é eficaz porque transforma esses dois desafios generalizados em pontos fortes: resolver o problema do custo da inferência fornecendo modelos pequenos e, ao mesmo tempo, não liberar modelos grandes para evitar a reação do público contra o desempenho medíocre.
Ege 认为 OpenAI 可能选择替代方案:过度训练(overtraining)。即在非计算最优状态下用小模型训练更多数据:”当推理成为模型支出的主要部分时,最好…用小模型训练更多 token。”但过度训练已不可行。AI 实验室已耗尽高质量预训练数据。Elon Musk 和 Ilya Sutskever 最近都承认这点。
回到蒸馏。Ege 总结:”我认为 GPT-4o 和 Claude 3.5 Sonnet 很可能都经大模型蒸馏而来。”
Todas as pistas até este ponto indicam que a OpenAI está fazendo o que a Anthropic fez com o Opus 3.5 (treinar e esconder) da mesma forma (destilação) e pelos mesmos motivos (resultados ruins/controle de custos). Isso é uma descoberta. Mas a questão é a seguinte: o Opus 3.5 ainda 被隐藏。OpenAI 的对应模型在哪?是否藏在公司地下室?敢猜它的名字吗…

IV. Os pioneiros devem abrir o caminho
Abro a análise examinando o evento Opus 3.5 do Anthropic, que é mais transparente em suas informações. Em seguida, faço a ponte entre o conceito de destilação e a OpenAI, explicando que as mesmas forças subjacentes que impulsionam a Anthropic estão em ação na OpenAI, mas nossa teoria encontra um novo obstáculo: como pioneira, a OpenAI pode enfrentar obstáculos que a Anthropic ainda não encontrou.
Por exemplo, os requisitos de hardware para treinar o GPT-5. O Sonnet 3.6 é comparável ao GPT-4o, mas foi lançado cinco meses depois. Devemos presumir que o GPT-5 está em um nível mais alto: mais potente e maior. Não apenas o custo de raciocínio, mas também o custo de treinamento é maior. Pode haver meio bilhão de dólares em custos de treinamento envolvidos. É possível fazer isso com o hardware existente?
A Ege está mais uma vez desvendando: é possível. Não é realista oferecer um produto desse porte a 300 milhões de usuários, mas o treinamento não é um problema:
Em princípio, o hardware existente é suficiente para suportar modelos muito maiores que o GPT-4: por exemplo, um modelo de 100 trilhões de parâmetros que é 50 vezes maior que o GPT-4, com um custo de inferência de cerca de US$ 3.000/milhão de tokens de saída e uma taxa de saída de 10-20 tokens/segundo. Mas para que isso seja viável, os modelos grandes devem criar um valor econômico significativo para os clientes.
但即使微软、谷歌或亚马逊(分别是 OpenAI、DeepMind 和 Anthropic 的金主)也无法承受这种推理开支。解决方法很简单:若计划向公众提供数万亿参数模型,必须”创造巨大经济价值”。所以他们不这样做。
他们训练模型。发现”比现有产品表现更好”。但必须接受”其进步程度不足以证明维持运行的巨额成本”。(这措辞耳熟吗?《华尔街日报》一个月前报道 GPT-5 时用词与彭博对 Opus 3.5 的报道惊人相似。)
Eles relatam resultados medíocres (com a flexibilidade de ajustar a narrativa). Mantenha-os internamente como modelos de professores para destilar modelos de alunos. Em seguida, libere os últimos. Recebemos o Sonnet 3.6 e o GPT-4o, o1, etc. e nos alegramos com sua qualidade barata. As expectativas para o Opus 3.5 e o GPT-5 permanecem intactas, mesmo quando ficamos mais impacientes. Sua mina de ouro continua a brilhar.
V. Com certeza você tem mais motivos, Sr. Altman!
V. É claro que você tem mais motivos, Sr. Altman!
Quando cheguei até aqui em minha investigação, ainda não estava totalmente convencido. É verdade que todas as evidências sugerem que isso é totalmente plausível para a OpenAI, mas ainda há uma lacuna entre "plausível" ou mesmo "plausível" e "real". Não vou preencher essa lacuna para você - afinal, trata-se apenas de especulação. Mas posso fortalecer ainda mais o argumento.
Há mais evidências de que a OpenAI está operando dessa maneira? Há mais motivos para eles atrasarem o lançamento do GPT-5 além do desempenho ruim e das perdas crescentes, e quais informações podemos extrair das declarações públicas dos executivos da OpenAI sobre o GPT-5? Eles não estão correndo o risco de sofrer danos à reputação ao atrasar repetidamente o lançamento do modelo? Afinal de contas, a OpenAI é a face da revolução da IA, e a Anthropic opera à sua sombra. A Anthropic pode se dar ao luxo de operar dessa forma, mas e a OpenAI? Talvez não sem um preço.
Por falar em dinheiro, vamos nos aprofundar em alguns detalhes relevantes sobre a parceria da OpenAI com a Microsoft. Primeiro, o fato bem conhecido: termos da AGI. Na publicação do blog da OpenAI sobre sua estrutura, eles têm cinco cláusulas de governança que definem como operam, seu relacionamento com organizações sem fins lucrativos, seu relacionamento com o conselho de administração e seu relacionamento com a Microsoft. A quinta cláusula define a AGI como "um sistema altamente autônomo capaz de superar os seres humanos na maioria dos empreendimentos economicamente valiosos" e estabelece que, assim que o Conselho de Administração da OpenAI declarar que a AGI foi implementada, "o sistema será excluído do licenciamento de propriedade intelectual e de outros termos comerciais com a Microsoft, que estão sujeitos apenas aos termos da licença da Microsoft e a outros termos comerciais. outros termos comerciais com a Microsoft, que se aplicam somente à tecnologia pré-AGI".
Não é preciso dizer que nenhuma das empresas quer que a parceria seja desfeita. A openAI estabelece os termos, mas faz tudo o que pode para evitar ter que cumpri-los. Uma maneira de fazer isso é atrasar o lançamento de sistemas que possam ser rotulados como AGI. "Mas o GPT-5 certamente não é AGI", você dirá. E aqui está um segundo fato que quase ninguém conhece: a OpenAI e a Microsoft têm uma definição secreta de AGI que, embora irrelevante para fins científicos, define legalmente sua parceria: uma AGI é um "sistema de IA capaz de gerar pelo menos US$ 100 bilhões em lucros". Sistema de IA.
Se a OpenAI hipoteticamente adiasse o lançamento sob o pretexto de que o GPT-5 não estava pronto, ela conseguiria outra coisa além de controlar os custos e evitar uma reação pública negativa: evitaria anunciar se o produto atingiu ou não o limite para ser classificado como AGI. Embora US$ 100 bilhões seja uma cifra impressionante, nada impede que clientes ambiciosos obtenham tanto lucro além disso. Por outro lado, sejamos claros: se a OpenAI prevê que o GPT-5 gerará US$ 100 bilhões em receita recorrente por ano, ela não se importará em acionar a cláusula AGI e se separar da Microsoft.
A maior parte da reação pública ao fato de a OpenAI não lançar o GPT-5 baseou-se na suposição de que eles não o estavam lançando porque não era bom o suficiente. Mesmo que isso fosse verdade, nenhum cético deixa de pensar que a OpenAI pode ter um caso de uso interno melhor do que um uso externo. Há uma enorme diferença entre criar um modelo excelente e criar um modelo excelente que possa atender a 300 milhões de pessoas de forma econômica. Se você não puder fazer isso, não o fará. Mas, novamente, se você desnecessário Faça isso e você não o fará. Eles costumavam nos fornecer seus melhores modelos porque precisavam de nossos dados. Isso não é mais tão necessário. E eles não estão mais atrás do nosso dinheiro. Esse é o negócio da Microsoft, não o deles. Eles querem AGI, depois ASI. Querem deixar um legado.

VI. Por que isso muda tudo
Estamos chegando ao fim. Acredito que já apresentei argumentos suficientes para construir uma tese sólida: é muito provável que a OpenAI já tenha o GPT-5 internamente, assim como a Anthropic tem o Opus 3.5. É até mesmo possível que a OpenAI nunca lance o GPT-5. O público agora mede o desempenho em termos de o1/o3, não apenas GPT-4o ou Claude Sonnet 3.6. Com a OpenAI explorando a lei do escalonamento nos testes, a barra que precisa ser ultrapassada para o GPT-5 continua subindo. Como eles podem lançar um GPT-5 que realmente supere o desempenho do o1, do o3 e dos próximos modelos da série o, especialmente se estiverem lançando-os em um ritmo tão rápido? Além disso, eles não precisam mais de nosso dinheiro ou dados.
O treinamento de novos modelos básicos - GPT-5, GPT-6 e posteriores - sempre fez sentido internamente para a OpenAI, mas não necessariamente como um produto. Isso provavelmente acabou. O único objetivo importante para eles agora é continuar a gerar dados melhores para a próxima geração de modelos. De agora em diante, o modelo básico poderá operar em segundo plano, capacitando outros modelos a realizar feitos que não poderiam realizar por conta própria - como um velho recluso que transmite sabedoria de uma caverna secreta, só que essa caverna é um data center gigante. Quer o vejamos ou não, experimentaremos as consequências de sua sabedoria.

Mesmo que o GPT-5 acabe sendo lançado, esse fato de repente parece quase irrelevante. Se a OpenAI e a Anthropic forem bem-sucedidas Autoaperfeiçoamento recursivo (embora ainda com o envolvimento humano), então não importará mais o que eles nos apresentarem publicamente. Eles ficarão cada vez mais à frente - assim como o universo está se expandindo tão rapidamente que a luz de galáxias distantes não pode mais chegar até nós.
Talvez seja por isso que a OpenAI saltou do o1 para o o3 em apenas três meses. É também por isso que eles estão saltando para o4 e o5. Provavelmente é por isso que eles estão tão animados nas mídias sociais ultimamente. Porque implementaram um modo de operação novo e aprimorado.
Você realmente acha que estar próximo da AGI significa que você poderá usar uma IA cada vez mais poderosa? Que eles liberarão todos os avanços para que possamos usá-los? É claro que você não acreditará nisso. Eles estavam falando sério quando disseram que seus modelos os levariam tão longe que ninguém mais seria capaz de alcançá-los. Cada nova geração de modelos é um motor de velocidade de escape. Da estratosfera, eles deram adeus.
Ainda não se sabe se eles retornarão.