


De Paris. Mistral AI Mais uma vez, com sua estratégia de código aberto característica, ela lançou uma peça importante no espaço de IA - oVoxtral Modelagem de áudio. A família, que é considerada como OpenAI O mais forte concorrente na Europa, o lançamento do Voxtral Em vez de ser uma mera ferramenta de transcrição de fala, ele estende seus poderosos recursos de modelagem de linguagem para o domínio do áudio, com o objetivo de fornecer uma solução de processamento de fala pronta para uso e econômica para aplicativos comerciais.
Voxtral Ao oferecer duas versões muito diferentes do modelo, essa estratégia revela claramente suas ambições de mercado. Uma é composta por 24B composição de parâmetros de uma versão pesada projetada para ambientes de produção que precisam lidar com grandes quantidades de dados; outra 3B paramétrico Mini visando cenários de computação local e de borda com restrição de recursos. Ambas as versões estão disponíveis em Apache 2.0 Aberto sob licença, o que significa que as empresas e os desenvolvedores não apenas podem fazer download, modificar e implementar, mas também elimina as preocupações associadas ao uso comercial.
Mais do que ouvir: compreensão integrada e vantagens multilíngues
与 OpenAI 的 Whisper Diferentemente dos modelos focados na transcrição de fala (ASR) de alta precisão, como oVoxtral é o principal ponto forte do software de inteligência artificial da Microsoft, com seus recursos de NLU (Natural Language Understanding) integrados nativamente. Ele é baseado em Mistral Small 3.1 O modelo de linguagem é construído de forma a herdar recursos avançados de processamento de texto. Isso significa que os usuários não precisam mais criar links complexos de processamento de fala para texto e para modelos de linguagem, e podem fazer perguntas diretamente, gerar resumos ou extrair informações estruturadas de arquivos de áudio. Por exemploVoxtral A capacidade de lidar com até 30 minutos de transcrição de áudio ou 40 minutos de tarefas de compreensão de áudio é possível graças ao seu 32k A janela de contexto do token é fundamental para lidar com cenários como gravações de conferências e entrevistas longas.
Na área de suporte multilíngue.Voxtral Ele também se destaca, especialmente em idiomas europeus, onde os benchmarks oficiais mostram que ele suporta inglês, francês, alemão, espanhol e italiano. Esse recurso lhe dá uma vantagem natural ao lidar com dados de áudio para negócios internacionais.
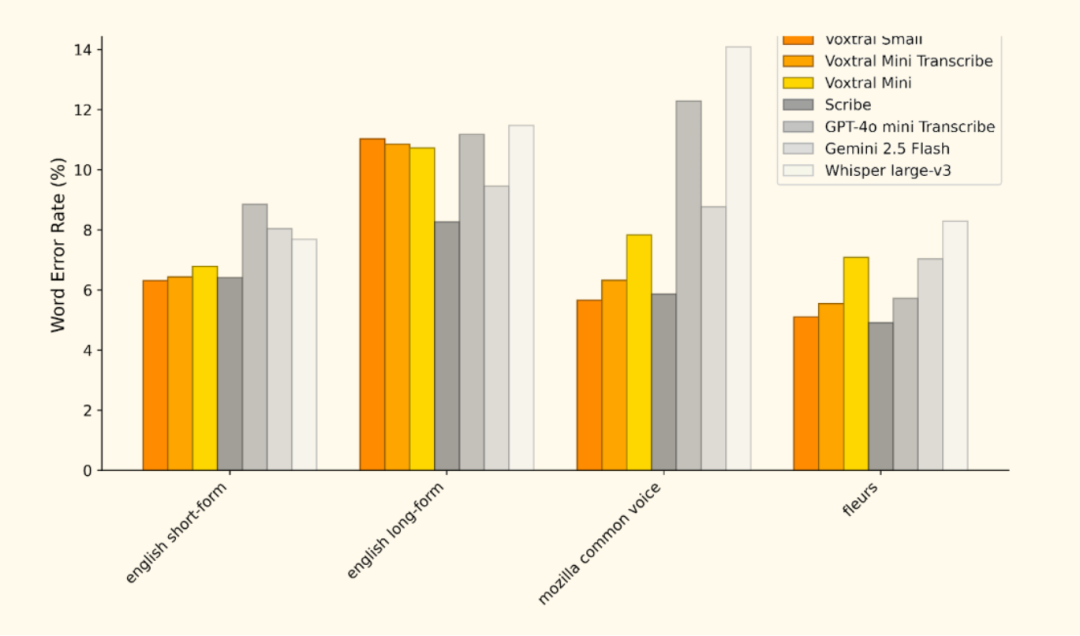
Cenários de aplicativos: da nuvem à borda
Voxtral O potencial de aplicação abrange uma ampla gama de cenários, desde a nuvem até a borda:
- atendimento ao clienteTranscrição automática de chamadas de atendimento ao cliente e geração direta de ordens de serviço ou resumos para aumentar a eficiência da resposta.
- criação de conteúdoTransforme rapidamente podcasts e entrevistas em transcrições com a capacidade de destilar as ideias principais imediatamente.
- Análise das reuniõesRegistre e gere atas de reuniões em tempo real, extraindo as principais decisões e tarefas.
- Inteligência de bordaImplementação em dispositivos de IoT, como casas inteligentes e sistemas em veículos
Voxtral MiniA mais nova adição à lista é uma nova interface de voz, que permite a interação local por voz sem a necessidade de uma conexão com a Internet.
Guia de início rápido
Mistral AI Oferece a capacidade de se conectar à Internet por meio da nuvem API ou implantado localmente usando ambos Voxtral。
(i) Adoção Mistral AI fig. no alto das nuvens API
Para os desenvolvedores que buscam uma integração rápida, você pode usar o aplicativo oficial API. Em primeiro lugar, em Mistral AI Registre-se na plataforma e obtenha API e, em seguida, passe a chave mistralai Os clientes Python podem chamá-lo.
(ii) Implantação local (vLLM (Recomendado)
Para cenários que exigem privacidade de dados ou operação off-line, a implantação local é a melhor opção. Oficialmente recomendado vLLM pois ele fornece uma estrutura para a Voxtral O suporte à inferência de alto desempenho é fornecido.
1. ambiente de instalação
Em primeiro lugar, verifique se você instalou o Python e, em seguida, passe o pip montagem vLLM e dependências relacionadas.
uv pip install -U "vllm
" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly
2. iniciar serviços locais
Use o seguinte comando no Hugging Face Faça o download do modelo e inicie um aplicativo com o comando OpenAI Serviços locais compatíveis.
python -m vllm.entrypoints.openai.api_server \
--model mistralai/Voxtral-Mini-3B-v0.1 \
--tokenizer-id mistralai/Mistral-7B-Instruct-v0.3 \
--enable-chunked-prefill
3. chamar serviços locais
Depois que o serviço for iniciado, você poderá usar o comando OpenAI ou a biblioteca do cliente curl com a execução local do Voxtral modelos para interagir. A seguir, uma descrição do uso do Python Exemplos de transcrição e compreensão de fala.
- transcrição de voz
from openai import OpenAI
from huggingface_hub import hf_hub_download
# 配置客户端指向本地vLLM服务
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="vllm" # 本地服务不需要真实密钥
)
# 下载示例音频
audio_file_path = hf_hub_download(
repo_id="patrickvonplaten/audio_samples",
filename="obama.mp3",
repo_type="dataset"
)
# 发起转录请求
with open(audio_file_path, "rb") as audio_file:
transcription = client.audio.transcriptions.create(
model="mistralai/Voxtral-Mini-3B-v0.1",
file=audio_file,
language="en"
)
print(transcription.text)
- Compreensão da fala (Q&A)
from openai import OpenAI
from huggingface_hub import hf_hub_download
import base64
# 配置客户端
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="vllm"
)
# 下载并编码音频文件
def encode_audio_to_base64(filepath):
with open(filepath, 'rb') as audio_file:
return base64.b64encode(audio_file.read()).decode('utf-8')
obama_file = hf_hub_download("patrickvonplaten/audio_samples", "obama.mp3", repo_type="dataset")
bcn_file = hf_hub_download("patrickvonplaten/audio_samples", "bcn_weather.mp3", repo_type="dataset")
obama_base64 = encode_audio_to_base64(obama_file)
bcn_base64 = encode_audio_to_base64(bcn_file)
# 构建包含音频和文本的多模态消息
response = client.chat.completions.create(
model="mistralai/Voxtral-Mini-3B-v0.1",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "这是两段音频。第一段是一位著名人物的演讲,第二段是天气预报。请问,哪一段演讲更有启发性?为什么?"},
{"type": "image_url", "image_url": {"url": f"data:audio/mpeg;base64,{obama_base64}"}},
{"type": "image_url", "image_url": {"url": f"data:audio/mpeg;base64,{bcn_base64}"}}
]
}
],
temperature=0.2
)
print(response.choices.message.content)
Recursos do projeto
- Blog oficial: https://mistral.ai/news/voxtral/
- Download do modelo: https://huggingface.co/mistralai/Voxtral-Mini-3B-2507





































