



O MedGemma é um conjunto de modelos de IA de código aberto lançado pelo Google na plataforma Hugging Face, com foco na compreensão de textos e imagens na área médica. Ele é baseado em Gemma 3 Desenvolvimento de modelos, projetado para ajudar os desenvolvedores a criar aplicativos de IA relacionados à área de saúde A MedGemma oferece diversas variantes de modelos, incluindo um modelo multimodal de 4B parâmetros e um modelo multimodal e de texto de 27B parâmetros. Esses modelos são especialmente treinados em textos médicos, registros eletrônicos de saúde (EHRs) e uma variedade de imagens médicas, como raios X, imagens de dermatologia, imagens de oftalmologia e lâminas de histopatologia. Os desenvolvedores podem usar esses modelos para acelerar o desenvolvimento de aplicativos de IA médica, como geração de relatórios radiológicos, perguntas e respostas médicas e classificação de imagens, etc. A natureza de código aberto do MedGemma facilita o acesso e é adequado para pesquisadores e desenvolvedores executarem em uma única GPU, reduzindo a barreira de desenvolvimento.
Lista de funções
- Processamento de textos médicos: analisa e gera conteúdo de texto relacionado à medicina, como relatórios médicos, pares de perguntas e respostas e registros eletrônicos de saúde.
- Compreensão de imagens médicas: suporta a análise de uma ampla variedade de imagens médicas, incluindo radiografias de tórax, imagens dermatológicas, imagens oftalmológicas e lâminas histopatológicas.
- Raciocínio multimodal: combinação de dados de texto e imagem para fornecer recursos integrados de raciocínio médico, como a geração de relatórios radiológicos ou a interpretação do conteúdo da imagem.
- Opções de variantes de modelo: modelo multimodal de 4B parâmetros (versão pré-treinada e com ajuste fino de comando) e modelo multimodal e de texto de 27B parâmetros (somente versão com ajuste fino de comando) estão disponíveis.
- Otimização eficiente da inferência: os modelos são otimizados para serem executados em uma única GPU, reduzindo os requisitos de recursos de computação.
- Código aberto e ajustável: o modelo é totalmente de código aberto e os desenvolvedores podem ajustá-lo para melhorar o desempenho de acordo com as necessidades específicas.
Usando a Ajuda
Instalação e implementação
Os modelos MedGemma são hospedados na plataforma Hugging Face e podem ser usados por desenvolvedores sem instalação complicada. Veja como funciona:
- Acesso à página do modelo
show (um ingresso)https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4Esta página contém links para downloads e documentação dos modelos paramétricos 4B e 27B. A página contém links para download e documentação dos modelos paramétricos 4B e 27B. - Preparação ambiental
- Certifique-se de que o Python 3.8 ou posterior esteja instalado.
- Instale a biblioteca Transformers para Hugging Face e execute o seguinte comando:
pip install transformers - Instale o PyTorch ou o TensorFlow (escolha com base nos requisitos do modelo). Por exemplo, instale o PyTorch:
pip install torch - Se você processar dados de imagem, precisará instalar bibliotecas adicionais, como
Pillow:pip install Pillow
- Modelos para download
Na página do modelo Hugging Face, selecione a variante MedGemma desejada (por exemplogoogle/medgemma-4b-it或google/medgemma-27b-multimodal). Use o código a seguir para fazer download e carregar o modelo:from transformers import AutoModel, AutoTokenizer model_name = "google/medgemma-4b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModel.from_pretrained(model_name)O modelo 27B requer mais memória e recomenda-se uma GPU com pelo menos 16 GB de memória de vídeo.
- ambiente operacional
Os modelos MedGemma são suportados em uma única GPU para desenvolvimento local ou implantação na nuvem. Recomendamos o uso do Google Cloud ou do Hugging Face Inference Endpoints para a implantação.https://gke-ai-labs.dev/Diretrizes de implantação.
Funções principais
1. processamento de textos médicos
O MedGemma pode processar textos médicos, como gerar relatórios ou responder a perguntas médicas. O procedimento é o seguinte:
- Preparação de entradaPreparação de texto relevante do ponto de vista médico, como uma parte do registro eletrônico de saúde ou uma pergunta médica.
- exemplo de código:
input_text = "患者胸部 X 光显示肺部阴影,可能是什么原因?" inputs = tokenizer(input_text, return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - no finalO modelo gera possíveis explicações ou recomendações de diagnóstico, com base em seu treinamento em textos médicos.
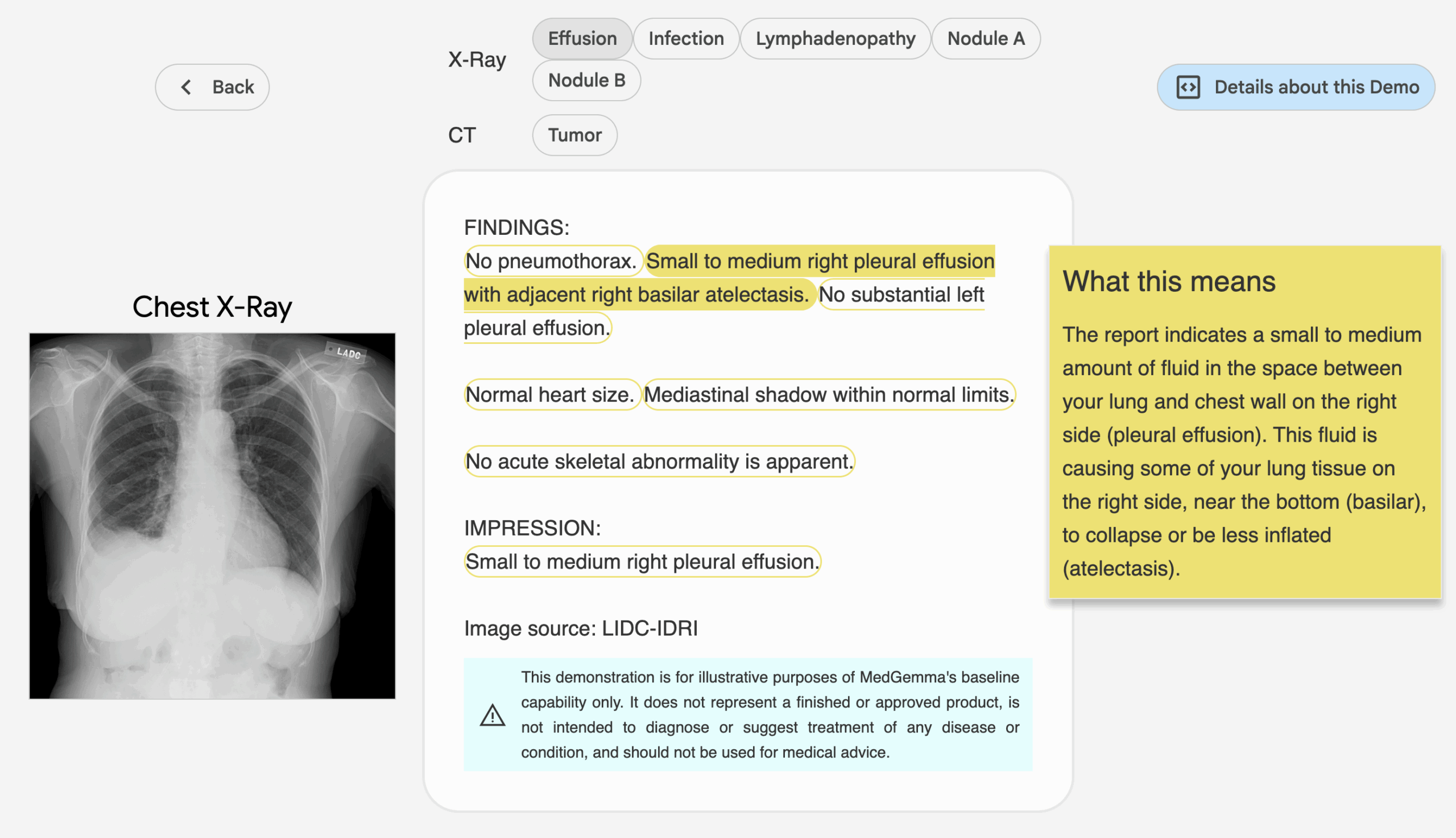
2. compreensão de imagens médicas
O modelo multimodal do MedGemma suporta a análise de imagens médicas (por exemplo, raios X, imagens da pele). Procedimento:
- Pré-processamento de imagensPNG: Converte a imagem em um formato aceitável para o modelo (por exemplo, PNG ou JPEG).
- exemplo de código(modelo multimodal 4B como exemplo):
from PIL import Image import torch image = Image.open("chest_xray.png").convert("RGB") inputs = tokenizer(text="描述这张胸部 X 光图像", images=[image], return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) - no finalO modelo gera descrições de imagens ou sugestões de diagnóstico, como "A imagem mostra uma sombra no lobo inferior do pulmão direito, o que pode indicar pneumonia".
3. raciocínio multimodal
Os modelos multimodais podem processar texto e imagens. Por exemplo, insira uma imagem de raio X e a pergunta "Essa imagem mostra sinais de pneumonia?" e o modelo combinará a imagem e o texto para gerar uma resposta. O modelo combinará a imagem e o texto para gerar uma resposta. A operação é semelhante à descrita acima, exceto pelo fato de que o tokenizer Passe texto e imagens no campo
4. ajuste fino do modelo
O desenvolvedor pode ajustar o modelo para tarefas específicas. As etapas são as seguintes:
- Coleta de conjuntos de dados médicos específicos (por exemplo, imagens ou textos de radiologia personalizados).
- Usando Hugging Face's
TrainerAPI para ajuste fino:from transformers import Trainer, TrainingArguments training_args = TrainingArguments( output_dir="./medgemma_finetuned", per_device_train_batch_size=4, num_train_epochs=3, ) trainer = Trainer(model=model, args=training_args, train_dataset=your_dataset) trainer.train() - Salve o modelo ajustado para uso posterior.
advertência
- Risco de contaminação de dadosO MedGemma pode ter sido exposto a dados médicos disponíveis publicamente durante o pré-treinamento, e os desenvolvedores precisam validar o desempenho do modelo usando conjuntos de dados não publicados para garantir sua capacidade de generalização.
- Uso não clínicoO MedGemma destina-se apenas a pesquisa e desenvolvimento e não deve ser usado para diagnóstico clínico real sem validação.
- Requisitos de hardwareO modelo 4B é adequado para ambientes com poucos recursos, enquanto o modelo 27B requer uma GPU de maior desempenho.
cenário do aplicativo
- Geração de relatórios radiológicos
Os radiologistas podem usar o MedGemma para analisar imagens de raios X ou de tomografia computadorizada e gerar um relatório preliminar para ajudá-los a interpretar rapidamente as imagens. - Sistema de perguntas e respostas médicas
Os desenvolvedores podem criar bots de perguntas e respostas médicas que usam os recursos de processamento de texto da MedGemma para responder a perguntas comuns de pacientes ou estudantes de medicina. - Análise de registros eletrônicos de saúde
As organizações de saúde podem usar o modelo multimodal 27B para analisar dados complexos de EHR, extrair informações importantes e otimizar os processos de tratamento. - Apoio à pesquisa médica
Os pesquisadores podem usar o MedGemma para analisar a literatura médica ou conjuntos de dados de imagens para acelerar o processo de pesquisa, por exemplo, para classificação de imagens dermatológicas ou análise histopatológica.
QA
- O MedGemma pode ser usado para diagnóstico clínico real?
Atualmente, o MedGemma é usado apenas para pesquisa e desenvolvimento e não pode ser usado diretamente para fins de diagnóstico sem validação clínica. Os desenvolvedores precisam validar ainda mais a confiabilidade do modelo em tarefas específicas. - Qual é a diferença entre o modelo 27B e o modelo 4B?
O modelo 4B é adequado para ambientes com poucos recursos e oferece suporte a tarefas multimodais e textuais; o modelo 27B é dividido em versões textuais e multimodais, que são mais eficientes e adequadas para tarefas complexas, mas exigem recursos computacionais mais altos. - Como você lida com a contaminação de dados?
Validar modelos usando conjuntos de dados institucionais internos ou não públicos para evitar que os dados de pré-treinamento afetem os recursos de generalização. - Quais imagens médicas são compatíveis com o MedGemma?
Suporta uma ampla variedade de imagens médicas, como radiografias de tórax, imagens de dermatologia, imagens de oftalmologia e lâminas de histopatologia.
































