



O LightRAG é uma estrutura Python de código aberto desenvolvida por uma equipe da Escola de Ciência de Dados da Universidade de Hong Kong para simplificar e acelerar o processo de criação de aplicativos Retrieval Augmented Generation (RAG). Ela aprimora a qualidade do conteúdo gerado combinando gráficos de conhecimento com técnicas tradicionais de recuperação de vetores para fornecer informações mais precisas e contextualmente relevantes para modelos de linguagem grande (LLMs). O principal recurso da estrutura é seu design leve e modular, que divide o complexo processo RAG em vários componentes independentes, como análise de documentos, construção de índices, recuperação de informações, reorganização de conteúdo e geração de texto. Esse design não apenas reduz o limite para os desenvolvedores, mas também oferece um alto grau de flexibilidade, permitindo que os usuários substituam ou personalizem facilmente diferentes módulos de acordo com suas necessidades específicas, como a integração de diferentes bancos de dados vetoriais, bancos de dados gráficos ou grandes modelos de linguagem. Projetado para cenários em que informações complexas e relacionamentos profundos precisam ser processados, o LightRAG se dedica a resolver o problema de informações de texto fragmentadas e a falta de conexões profundas nos sistemas RAG tradicionais.
Lista de funções
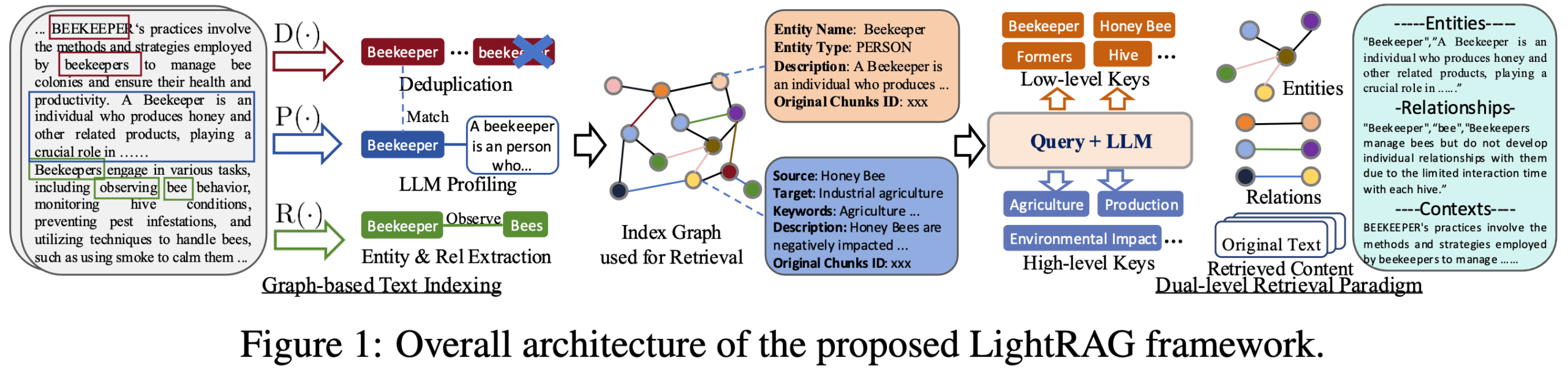
- Design modularDivisão do processo RAG em módulos claros para análise, indexação, recuperação, reformatação e geração de documentos que sejam fáceis de entender e personalizar.
- integração do gráfico de conhecimentoCapacidade de extrair automaticamente entidades e relacionamentos de textos não estruturados e criar gráficos de conhecimento que permitem uma compreensão mais profunda e a correlação de informações.
- mecanismo de pesquisa em duas camadasPesquisa de similaridade baseada em vetores e recuperação de associação baseada em gráficos de conhecimento: combina a pesquisa de similaridade baseada em vetores e a recuperação de associação baseada em gráficos de conhecimento e é capaz de lidar com consultas que visam detalhes específicos (locais) e macroconceitos (globais).
- Opções flexíveis de armazenamentoSuporte a uma variedade de back-ends de armazenamento, incluindo Json, PostgreSQL e Redis para armazenamento de pares de valores-chave; FAISS, Chroma e Milvus para armazenamento de vetores; e Neo4j e PostgreSQL AGE para armazenamento de gráficos.
- Alta compatibilidade de modelosSuporte ao acesso a uma ampla variedade de modelos de linguagem grande (LLMs) e modelos de incorporação, incluindo aqueles fornecidos por plataformas como OpenAI, Hugging Face e Ollama.
- Suporte a vários formatos de arquivoCapacidade de lidar com uma ampla variedade de formatos de documentos, incluindo PDF, DOCX, PPTX, CSV e texto simples.
- Ferramentas de visualizaçãoInterface da Web: fornece uma interface da Web para apoiar a exploração visual de gráficos de conhecimento, permitindo que os usuários visualizem as conexões entre os dados.
- capacidade multimodalCapacidade ampliada de processar conteúdo multimodal, como imagens, tabelas, fórmulas, etc., por meio da integração com o RAG-Anything.
Usando a Ajuda
O LightRAG é uma estrutura avançada e fácil de usar, projetada para ajudar os desenvolvedores a criar rapidamente sistemas inteligentes de perguntas e respostas com base em sua própria base de conhecimento. Seu maior recurso é a combinação de gráficos de conhecimento, tornando os resultados da pesquisa não apenas relevantes, mas também com relações lógicas mais fortes. A seguir, uma descrição detalhada de sua instalação e do uso do processo.
montagem
Começar a usar o LightRAG é muito fácil e pode ser instalado diretamente pelo pip, o gerenciador de pacotes do Python. Recomenda-se instalar a versão completa com API e interface da Web para experimentar toda a funcionalidade, inclusive a visualização do gráfico de conhecimento.
- Instalação via PyPI:
Abra um terminal e execute o seguinte comando:pip install "lightrag-hku[api]"Esse comando instala as bibliotecas principais do LightRAG e as dependências relacionadas exigidas por seus servidores.
- Configuração de variáveis de ambiente:
Após a conclusão da instalação, você precisa configurar o ambiente de tempo de execução. O LightRAG fornece um modelo para o arquivo de ambienteenv.example. Você precisa copiá-lo como.enve modifique a configuração para se adequar à sua situação, principalmente a definição das chaves de API para o Large Language Model (LLM) e o Embedding Model.cp env.example .envEm seguida, abra-o em um editor de texto
.envpreencha seu arquivoOPENAI_API_KEYou outras credenciais de acesso ao modelo. - Início dos serviços:
Quando a configuração estiver concluída, execute o seguinte comando diretamente do terminal para iniciar o serviço LightRAG:lightrag-serverDepois que o serviço é iniciado, você pode acessar a interface da Web que ele fornece por meio de um navegador ou interagir com ele por meio de uma API.
Processo de uso principal
O processo de programação principal da LightRAG segue uma clara RAG Lógica:Alimentação de dados -> Criação de índices -> Geração de consultasA Abaixo está um exemplo simples de código Python que demonstra como implementar um processo completo de Q&A usando o LightRAG Core.
- Inicialização de uma instância do LightRAG
Primeiro, você precisa importar os módulos necessários e criar uma instância do LightRAG. Durante a inicialização, você deve especificar o diretório de trabalho (para dados e cache), as funções incorporadas e as funções LLM.import os import asyncio from lightrag import LightRAG, QueryParam from lightrag.llm.openai import gpt_4o_mini_complete, openai_embed from lightrag.kg.shared_storage import initialize_pipeline_status # 设置工作目录 WORKING_DIR = "./rag_storage" if not os.path.exists(WORKING_DIR): os.mkdir(WORKING_DIR) # 设置你的OpenAI API密钥 os.environ["OPENAI_API_KEY"] = "sk-..." async def initialize_rag(): # 创建LightRAG实例,并注入模型函数 rag = LightRAG( working_dir=WORKING_DIR, embedding_func=openai_embed, llm_model_func=gpt_4o_mini_complete, ) # 重要:必须初始化存储和处理管道 await rag.initialize_storages() await initialize_pipeline_status() return ragtomar nota de:
initialize_storages()和initialize_pipeline_status()Essas duas etapas de inicialização são necessárias, caso contrário, o programa informará um erro. - Dados de alimentação (Inserir)
Quando a inicialização estiver concluída, você poderá adicionar seus dados de texto ao LightRAG.ainsertrecebe uma cadeia de caracteres ou uma lista de cadeias de caracteres.async def feed_data(rag_instance): text_to_insert = "史蒂芬·乔布斯是一位美国商业巨头和发明家。他是苹果公司的联合创始人、董事长和首席执行官。乔布斯被广泛认为是微型计算机革命的先驱。" await rag_instance.ainsert(text_to_insert) print("数据投喂成功!")Nessa etapa, o LightRAG divide automaticamente o texto em partes, extrai entidades e relacionamentos, gera embeddings vetoriais e constrói o gráfico de conhecimento em segundo plano.
- Dados da consulta (Query)
Depois que os dados são alimentados e indexados, eles estão prontos para serem consultados.aqueryrecebe uma pergunta e a passa pelo métodoQueryParampara controlar o comportamento da consulta.async def ask_question(rag_instance): query_text = "谁是苹果公司的联合创始人?" # 使用QueryParam配置查询模式 # "hybrid" 模式结合了向量搜索和图检索,推荐使用 query_params = QueryParam(mode="hybrid") response = await rag_instance.aquery(query_text, param=query_params) print(f"问题: {query_text}") print(f"答案: {response}") - Combinar e executar
Por fim, combinamos as etapas acima em uma função principal e usamos a funçãoasynciopara executar.async def main(): rag = None try: rag = await initialize_rag() await feed_data(rag) await ask_question(rag) except Exception as e: print(f"发生错误: {e}") finally: if rag: # 程序结束时释放存储资源 await rag.finalize_storages() if __name__ == "__main__": asyncio.run(main())
Explicação dos padrões de consulta
O LightRAG oferece vários modos de consulta para atender a diferentes cenários de aplicação:
naivePadrão básico de pesquisa vetorial para testes simples.localFoco nas informações da entidade diretamente relacionadas à consulta e é adequado para cenários que exigem respostas precisas e concretas.globalConhecimento global: concentra-se nos relacionamentos entre entidades e no conhecimento global para cenários que exigem respostas macro e correlacionais.hybrid:: Combinadolocal和globalAs vantagens do modelo são o fato de ser o mais versátil e, geralmente, o mais eficaz.mixIntegração de Knowledge Graph e Vector Retrieval: a integração de Knowledge Graph e Vector Retrieval é o modelo de recomendação na maioria dos casos.
Por meio do uso do QueryParam configurar mode você tem a flexibilidade de alternar entre esses modos para obter os melhores resultados de consulta.
cenário do aplicativo
- Atendimento inteligente ao cliente e sistema de perguntas e respostas
As empresas podem injetar informações internas, como manuais de produtos, arquivos de ajuda e registros históricos de atendimento ao cliente no LightRAG para criar um robô inteligente de atendimento ao cliente que possa responder com precisão e rapidez às perguntas dos clientes. Graças à combinação do gráfico de conhecimento, o sistema pode não apenas encontrar a resposta, mas também compreender as informações relacionadas por trás da pergunta e fornecer uma resposta mais abrangente. Por exemplo, ao responder a uma pergunta sobre a função de um produto, ele pode fornecer dicas relacionadas ou links para perguntas frequentes junto com a resposta. - Gerenciamento de base de conhecimento intraempresarial
Para organizações com uma enorme quantidade de documentos internos (por exemplo, documentos técnicos, relatórios de projetos, regras e regulamentos), o LightRAG pode transformá-los em uma base de conhecimento estruturada e inteligentemente consultável. Os funcionários podem fazer perguntas em linguagem natural, localizar rapidamente as informações de que precisam e até mesmo descobrir conexões ocultas entre diferentes documentos, melhorando consideravelmente a eficiência da recuperação de informações e a utilização do conhecimento. - Pesquisa científica e análise da literatura
Os pesquisadores podem usar o LightRAG para processar um grande número de artigos acadêmicos e relatórios de pesquisa. O sistema é capaz de extrair automaticamente as principais entidades (por exemplo, tecnologias, acadêmicos, experimentos), conceitos e seus relacionamentos, e criá-los em um gráfico de conhecimento. Isso permite que os pesquisadores explorem facilmente o conhecimento em documentos, como a consulta "a aplicação de uma determinada tecnologia em diferentes estudos" ou "a colaboração entre dois acadêmicos", acelerando assim o processo de pesquisa. - Análise de documentos financeiros e jurídicos
Em áreas profissionais como finanças e direito, em que os documentos costumam ser complexos e volumosos, o LightRAG pode ajudar analistas ou advogados a extrair rapidamente informações importantes de documentos como relatórios anuais, prospectos, cláusulas legais, etc., e classificar as relações lógicas entre eles. Por exemplo, é possível identificar rapidamente todas as partes responsáveis em um contrato e suas cláusulas de direitos e responsabilidades correspondentes, ou analisar as descrições do mesmo negócio nos relatórios financeiros de várias empresas para auxiliar na tomada de decisões.
QA
- Qual é a diferença entre o LightRAG e estruturas genéricas como LangChain ou LlamaIndex?
O principal diferencial do LightRAG é seu foco na integração profunda dos gráficos de conhecimento no processo RAG, com o objetivo de resolver o problema da fragmentação das informações tradicionais do RAG. Enquanto o LangChain e o LlamaIndex são estruturas de desenvolvimento de aplicativos LLM com recursos mais amplos e de uso geral, que oferecem uma infinidade de ferramentas e opções de integração, mas também têm curvas de aprendizado relativamente íngremes, o LightRAG é mais leve, com o objetivo de fornecer aos desenvolvedores uma solução RAG simples, rápida e eficiente, com um gráfico de conhecimento integrado. - Há algum requisito especial para que o Large Language Model (LLM) use o LightRAG?
Sim, como o LightRAG precisa usar o LLM para extrair entidades e relacionamentos de documentos para criar um gráfico de conhecimento, isso requer um alto nível de capacidade de acompanhamento de comandos e compreensão contextual do modelo. É oficialmente recomendado usar um modelo com uma contagem de referência de pelo menos 32 bilhões e um comprimento de janela de contexto de pelo menos 32 KB; 64 KB é recomendado para garantir que documentos mais longos possam ser processados e que a tarefa de extração de entidades possa ser feita com precisão. - Quais são os tipos de bancos de dados suportados pelo LightRAG?
A camada de armazenamento do LightRAG é modular e oferece suporte a várias implementações de banco de dados. Para o armazenamento de chave-valor (KV Storage), ele é compatível com arquivos JSON nativos, PostgreSQL, Redis e MongoDB. Para o armazenamento vetorial (Vector Storage), ele é compatível com NanoVectorDB (padrão), FAISS, Chroma, Milvus e outros. Para o Graph Storage, ele oferece suporte ao NetworkX (padrão), Neo4j e PostgreSQL com o plug-in AGE. Esse design permite que os usuários escolham com flexibilidade de acordo com suas necessidades de pilha de tecnologia e desempenho. - Posso usar meus próprios modelos no LightRAG? Por exemplo, modelos implantados no Hugging Face ou no Ollama?
O LightRAG projetou um mecanismo flexível de injeção de modelos que permite aos usuários integrar LLMs personalizados e modelos incorporados. O código de amostra no repositório já fornece acesso ao Hugging Face e ao Ollama exemplo de modelo. Tudo o que você precisa fazer é escrever uma função de chamada que esteja em conformidade com sua especificação de interface e passá-la ao inicializar uma instância do LightRAG, o que permite que ele funcione perfeitamente com todos os tipos de modelos de código aberto ou implantados de forma privada.































