



LangExtract é uma biblioteca Python de código aberto desenvolvida pelo Google que se concentra na extração de dados estruturados de textos não estruturados. Ela utiliza modelos de linguagem em grande escala (LLMs), como o Google Gemini A série LangExtract, combinando posicionamento preciso do texto de origem e visualização interativa, ajuda os usuários a transformar rapidamente textos complexos em um formato de dados claro. Com apenas alguns exemplos, os usuários podem definir tarefas de extração aplicáveis a qualquer domínio sem precisar ajustar o modelo. O LangExtract é particularmente adequado para trabalhar com documentos longos, suporta processamento paralelo e várias rodadas de extração e é amplamente utilizado em áreas como saúde e análise literária. A ferramenta é liberada sob a licença Apache 2.0, e o código é hospedado no GitHub com contribuições abertas da comunidade.
Lista de funções
- Suporte a modelos em vários idiomas: compatível com o Google Gemini e outros modelos baseados em nuvem e Ollama Modelagem local com adaptação flexível às necessidades do usuário.
- Extração de informações estruturadas: extraia entidades, relacionamentos e atributos de textos não estruturados e gere uma saída no formato JSONL.
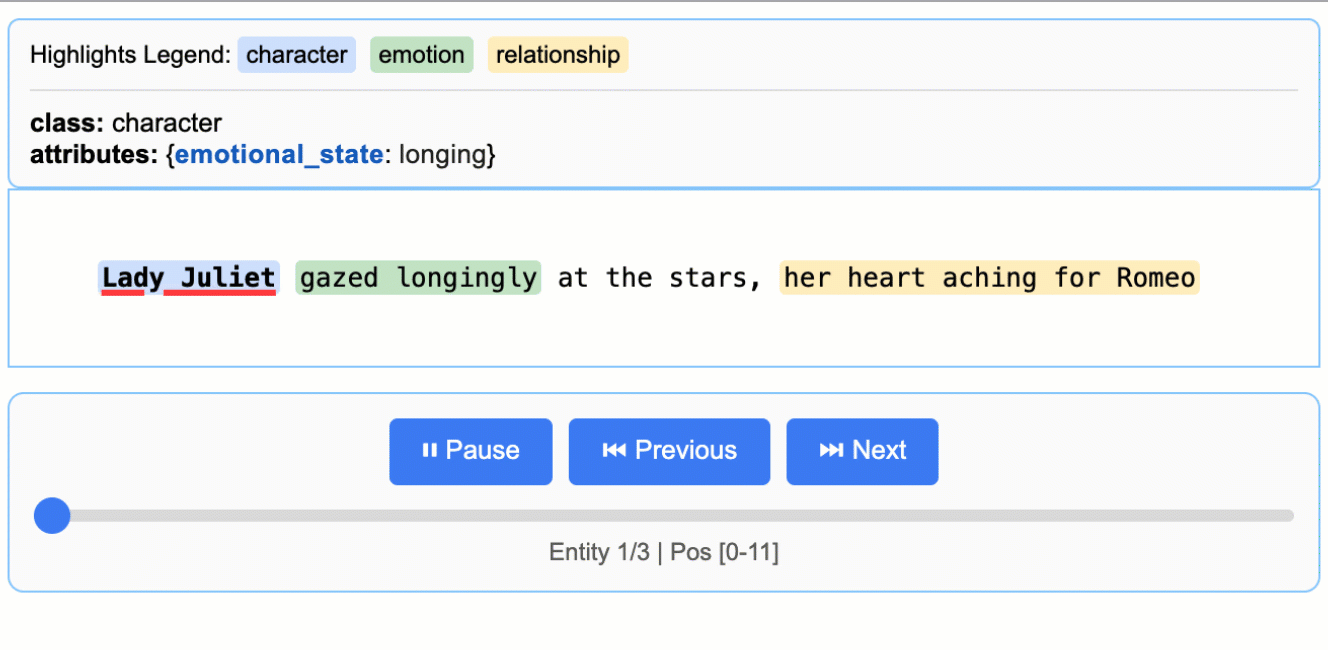
- Visualização interativa: arquivos de visualização HTML são gerados a partir dos resultados da extração, permitindo que os usuários visualizem e analisem facilmente as entidades extraídas.
- Processamento de documentos longos: processe com eficiência textos muito longos, como romances inteiros ou relatórios médicos, por meio de chunking inteligente e processamento paralelo.
- Tarefas de extração personalizadas: defina rapidamente regras de extração aplicáveis a domínios específicos com palavras-chave e um pequeno número de exemplos.
- Processamento de texto médico: suporte à extração do nome do medicamento, da dosagem e de outras informações de anotações clínicas para a área médica.
- Integração de API: oferece suporte a chamadas de API de modelo baseadas na nuvem e também pode ser estendido a pontos de extremidade de inferência de modelo local de terceiros.
Usando a Ajuda
Processo de instalação
O LangExtract foi desenvolvido em Python e oferece suporte a métodos modernos de gerenciamento de pacotes Python. Veja a seguir as etapas detalhadas de instalação:
- Repositório de código clone
Abra um terminal e execute o seguinte comando para clonar o repositório LangExtract:git clone https://github.com/google/langextract.git cd langextract - Instalação de dependências
Instale o LangExtract usando o pip. O modo de desenvolvimento é recomendado para modificar o código:pip install -e .Instale dependências adicionais se for necessário um ambiente de desenvolvimento ou teste:
pip install -e ".[dev]" # 包含 linting 工具 pip install -e ".[test]" # 包含 pytest 测试工具 - Configuração de chaves de API(por exemplo, usando modelos baseados em nuvem)
Se estiver usando um modelo de nuvem, como o Google Gemini, você precisará configurar a chave da API. Escreva a chave no arquivo.envDocumentação:cat >> .env << 'EOF' LANGEXTRACT_API_KEY=your-api-key-here EOFPara proteger a chave, adicione
.env到.gitignore:echo '.env' >> .gitignoreOs modelos locais (por exemplo, executados por meio do Ollama) não exigem uma chave de API.
- Verificar a instalação
Execute o seguinte comando para verificar se a instalação foi bem-sucedida:python -c "import langextract; print(langextract.__version__)"
Uso
A principal função do LangExtract é extrair dados estruturados do texto por meio de palavras de alerta e exemplos. Veja a seguir o procedimento:
1. extração de informações básicas
Suponha que você queira extrair caracteres, emoções e relacionamentos de um texto, o exemplo de código é o seguinte:
import langextract as lx
import textwrap
# 定义提示词
prompt = textwrap.dedent("""
Extract characters, emotions, and relationships in order of appearance. Use exact text for extractions. Do not paraphrase or overlap entities.
""")
# 提供示例
examples = [
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks?",
extractions=[
{"entity": "Romeo", "type": "character", "emotion": "hopeful"},
]
)
]
# 输入文本
text = "ROMEO. But soft! What light through yonder window breaks? It is Juliet."
# 执行提取
result = lx.extract(text, prompt=prompt, examples=examples, model="gemini-2.5-flash")
# 保存结果
lx.io.save_annotated_documents([result], output_name="extraction_results.jsonl")
Após a execução, os resultados da extração serão salvos como extraction_results.jsonl arquivo que contém as entidades extraídas e seus atributos.
2. geração de visualizações interativas
O LangExtract suporta a geração de visualização HTML dos resultados da extração para facilitar a visualização:
html_content = lx.visualize("extraction_results.jsonl")
with open("visualization.html", "w") as f:
f.write(html_content)
gerado visualization.html O arquivo pode ser aberto em um navegador, mostrando as entidades extraídas e seu contexto.
3. manuseio de documentos longos
Para documentos longos (como o livro inteiro de Romeu e Julieta), o LangExtract usa chunking inteligente e processamento paralelo:
url = "https://www.gutenberg.org/files/1513/1513.txt"
result = lx.extract_from_url(url, prompt=prompt, examples=examples, max_workers=4)
lx.io.save_annotated_documents([result], output_name="long_doc_results.jsonl")
max_workers controla o número de threads para processamento paralelo e é adequado para o processamento de arquivos grandes.
4. extração de textos médicos
O LangExtract é excelente na área médica, extraindo nomes de medicamentos, dosagens e outras informações. Exemplo:
prompt = "Extract medication names, dosages, and administration routes from clinical notes."
text = "Patient prescribed Metformin 500 mg orally twice daily."
result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro")
Os resultados conterão informações extraídas sobre medicamentos, como:
{"entity": "Metformin", "dosage": "500 mg", "route": "orally"}
Operação da função em destaque
- Seleção de modelos: O padrão é usar
gemini-2.5-flashmodelos com velocidade e qualidade equilibradas. Para tarefas complexas, mude paragemini-2.5-pro:result = lx.extract(text, prompt=prompt, model="gemini-2.5-pro") - extração multiroundMelhorar a precisão com várias extrações para documentos complexos:
result = lx.extract(text, prompt=prompt, num_passes=2) - Demonstração do RadExtractLangExtract oferece uma demonstração on-line do RadExtract, especializado em laudos radiológicos. Visite o HuggingFace Spaces (
https://google-radextract.hf.space) pode ser testado sem instalação.
advertência
- Os modelos de nuvem exigem chaves de API e conexões de rede estáveis.
- Ao processar documentos muito longos, recomenda-se usar a cota Gemini de Nível 2 para evitar a limitação da taxa.
- Ao salvar a chave de API, certifique-se de que a variável
.envSegurança de documentos.
cenário do aplicativo
- Processamento de dados médicos
Hospitais e organizações de pesquisa podem usar o LangExtract para extrair informações como medicamentos, doses, diagnósticos e muito mais de anotações clínicas ou relatórios de radiologia. Por exemplo, os relatórios de radiologia podem ser estruturados em um formato que inclui títulos e entidades-chave para facilitar a análise de dados e a tomada de decisões clínicas. - análise literária
Os pesquisadores podem extrair personagens, emoções e relacionamentos de longas obras da literatura. Por exemplo, analisar as interações dos personagens em Romeu e Julieta e gerar visualizações para estudar a rede de relacionamentos dos personagens. - Extração de inteligência de negócios
As empresas podem extrair entidades importantes (por exemplo, nomes de empresas, produtos, eventos) de notícias, relatórios ou mídias sociais para análise de mercado ou coleta de inteligência competitiva. - Documentação legal
Os escritórios de advocacia podem extrair cláusulas, datas, partes e outras informações de contratos ou documentos jurídicos para gerar rapidamente resumos estruturados.
QA
- O LangExtract é gratuito?
O LangExtract é uma ferramenta de código aberto e seu código é de uso gratuito (licença Apache 2.0). No entanto, há uma taxa de chamada de API para usar um modelo baseado em nuvem (por exemplo, Gemini). - Há suporte para modelos locais?
Suporta a execução de modelos locais de código aberto por meio do Ollama sem chaves de API, adequado para ambientes sem rede. - Como faço para lidar com documentos muito longos?
Use chunking inteligente e processamento paralelo (configuração)max_workers), e recomenda-se que várias extrações (configuraçãonum_passes) para melhorar a precisão. - Como os resultados da visualização são exibidos?
estar em movimentolx.visualizeGerar arquivos HTML que podem ser abertos em um navegador para visualizar interativamente os resultados da extração. - Os aplicativos médicos estão em conformidade?
O LangExtract é apenas uma ferramenta de demonstração, não um dispositivo de diagnóstico médico. Os aplicativos relacionados à saúde estão sujeitos aos Termos de Uso das Fundações para Desenvolvedores de IA para Saúde.





























