



O Kitten-TTS-Server é um projeto de código aberto que fornece uma solução leve de KittenTTS O modelo fornece um servidor com funcionalidade aprimorada. Os próprios usuários podem criar um serviço de conversão de texto em fala (TTS) com esse projeto. Os principais pontos fortes desse projeto são o fato de que ele se baseia no modelo original, acrescentando uma interface de usuário intuitiva na Web, processamento de texto longo para audiolivros e aceleração de GPU para melhorias significativas de desempenho. O modelo subjacente do servidor é muito pequeno, com menos de 25 MB, mas gera vozes humanas realistas e com som natural. O projeto simplificou o processo de instalação e execução do modelo, fornecendo um servidor com todos os recursos que é fácil de usar para usuários sem experiência. O servidor vem com 8 vozes predefinidas integradas (4 masculinas e 4 femininas) e oferece suporte à implantação via Docker, reduzindo muito a complexidade da configuração e da manutenção.
Lista de funções
- modelo leveO núcleo usa o modelo KittenTTS ONNX, que tem menos de 25 MB de tamanho e ocupa poucos recursos.
- Aceleração de GPU: através da otimização de
onnxruntime-gpuTecnologia de vinculação de pipeline e E/S com suporte total para aceleração NVIDIA (CUDA) para geração de fala significativamente mais rápida. - Geração de textos longos e audiolivrosA capacidade de processar automaticamente textos longos, quebrando frases de forma inteligente, processando-as em partes e, em seguida, unindo o áudio sem problemas, é ideal para gerar audiolivros completos.
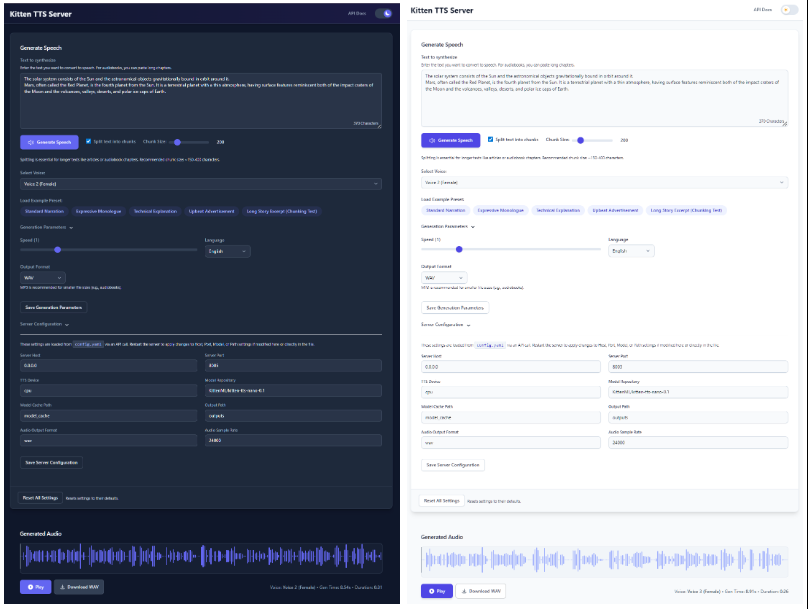
- Interface da Web modernizadaA UI da Web oferece uma interface intuitiva que permite aos usuários inserir texto, selecionar a fala, ajustar a taxa de fala e ver as formas de onda do áudio gerado em tempo real, tudo diretamente no navegador.
- Voz múltipla integradaVoz: Integra as 8 vozes (4 masculinas e 4 femininas) que vêm com o modelo KittenTTS e podem ser selecionadas diretamente na interface.
- Interface API duplaFornece um sistema totalmente funcional
/ttse uma estrutura de API TTS da OpenAI compatível com a interface/v1/audio/speechinterfaces para facilitar a integração com os fluxos de trabalho existentes. - Configuração simplesTodas as configurações são definidas por meio de um único
config.yamlA documentação é gerenciada. - memória de estadoA interface da Web lembra o último texto usado, a voz e as configurações relacionadas para simplificar o processo de operação.
- Suporte ao DockerDocker Compose: fornece arquivos Docker Compose pré-configurados para ambientes de CPU e GPU, permitindo a implantação em contêineres com um clique.
Usando a Ajuda
O projeto Kitten-TTS-Server fornece um processo claro de instalação e uso para garantir que os usuários possam colocá-lo em funcionamento em seu próprio hardware sem problemas.
Preparação do ambiente do sistema
Antes da instalação, você precisa preparar o ambiente a seguir:
- sistema operacionalWindows 10/11 (64 bits) ou Linux (recomendado Debian/Ubuntu).
- Python3.10 ou posterior.
- GitUsado para clonar o código do projeto do GitHub.
- eSpeak NGDependência necessária para a fonetização de texto.
- WindowsDownload e instalação na página de lançamento do eSpeak NG
espeak-ng-X.XX-x64.msi. O terminal de linha de comando precisa ser reiniciado após a instalação. - LinuxExecute o comando no terminal
sudo apt install espeak-ng。
- WindowsDownload e instalação na página de lançamento do eSpeak NG
- (A aceleração da GPU é opcional):
- Uma placa de vídeo NVIDIA habilitada para CUDA.
- (somente Linux): requer a instalação do
libsndfile1和ffmpeg. Isso pode ser feito com o comandosudo apt install libsndfile1 ffmpegpara instalar.
Etapas de instalação
Todo o processo de instalação foi projetado para ser "um clique", com diferentes caminhos de instalação, dependendo do seu hardware.
Etapa 1: clonar o repositório de código
Abra seu terminal (PowerShell no Windows, Bash no Linux) e execute o seguinte comando:
git clone https://github.com/devnen/Kitten-TTS-Server.git
cd Kitten-TTS-Server
Etapa 2: Criar e ativar um ambiente virtual Python
Para evitar conflitos com bibliotecas dependentes de outros projetos, é altamente recomendável criar um ambiente virtual separado.
- Windows (PowerShell):
python -m venv venv .\venv\Scripts\activate - Linux (Bash):
python3 -m venv venv source venv/bin/activate
Após a ativação bem-sucedida, o prompt da linha de comando será precedido por (venv) Palavras.
Etapa 3: Instalar as dependências do Python
Dependendo do fato de seu computador estar ou não equipado com uma placa de vídeo NVIDIA, escolha um dos seguintes métodos de instalação.
- Opção 1: instalação somente da CPU (mais fácil)
Isso funciona para todos os computadores.pip install --upgrade pip pip install -r requirements.txt - Opção 2: Instalação com GPU NVIDIA (mais desempenho)
Essa abordagem instala todas as bibliotecas CUDA necessárias para permitir que o programa seja executado na placa de vídeo.pip install --upgrade pip # 安装支持GPU的ONNX Runtime pip install onnxruntime-gpu # 安装支持CUDA的PyTorch,它会一并安装onnxruntime-gpu所需的驱动文件 pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # 安装其余的依赖 pip install -r requirements-nvidia.txtApós a conclusão da instalação, você pode executar o seguinte comando para verificar se o PyTorch reconhece sua placa de vídeo corretamente:
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"Se a saída for
CUDA available: TrueA seguir, um exemplo de uma configuração bem-sucedida do ambiente de GPU.
Servidor de operações
tomar nota deO servidor será iniciado pela primeira vez e baixará automaticamente o arquivo do modelo KittenTTS do Hugging Face, que tem cerca de 25 MB. Esse processo só precisa ser feito uma vez e as inicializações subsequentes serão muito rápidas.
- Certifique-se de que você ativou o ambiente virtual (linha de comando precedida por
(venv))。 - Execute o servidor em um terminal:
python server.py - Quando o servidor é iniciado, ele abre automaticamente a interface da Web em seu navegador padrão.
- Endereço da interface da Web.
http://localhost:8005 - Endereço da documentação da API.
http://localhost:8005/docs
- Endereço da interface da Web.
Para parar o servidor, basta pressionar na janela do terminal que está executando o servidor CTRL+C。
Métodos de instalação do Docker
Se você estiver familiarizado com o Docker, poderá usar o Docker Compose para a implantação, que é mais simples e permite um melhor gerenciamento dos aplicativos.
- Preparação ambiental:
- Instale o Docker e o Docker Compose.
- (Usuários de GPU) Instale o NVIDIA Container Toolkit.
- Repositório de código clone (Se não tiver sido feito antes).
git clone https://github.com/devnen/Kitten-TTS-Server.git cd Kitten-TTS-Server - Lançamento de contêineres (Escolha os comandos de acordo com seu hardware).
- Usuários de GPU NVIDIA:
docker compose up -d --build - Somente usuários de CPU:
docker compose -f docker-compose-cpu.yml up -d --build
- Usuários de GPU NVIDIA:
- Acesso e gerenciamento:
- Interface da Web.
http://localhost:8005 - Ver Diário.
docker compose logs -f - Contêineres de parada.
docker compose down
- Interface da Web.
Operação da função
- Gerar fala normal:
- Inicie o servidor e abra o arquivo
http://localhost:8005。 - Digite o texto que deseja converter na caixa de texto.
- Selecione um som favorito no menu suspenso.
- Você pode arrastar o controle deslizante para ajustar a velocidade da fala.
- Clique no botão "Generate Speech" (Gerar discurso) e o áudio será reproduzido automaticamente com um link para download.
- Inicie o servidor e abra o arquivo
- Gerar audiolivros:
- Copie o livro inteiro ou um capítulo em texto simples.
- Cole-o na caixa de texto da página da Web.
- Certifique-se de que a opção "Split text into chunks" (Dividir o texto em partes) esteja marcada.
- Para tornar as pausas mais naturais, é recomendável definir um tamanho de bloco entre 300 e 500 caracteres.
- Clique no botão "Generate Speech" (Gerar fala) e o servidor cortará automaticamente o texto longo, gerará a fala e, por fim, a unirá em um arquivo de áudio completo para download.
cenário do aplicativo
- Produção de audiolivros
Para usuários ou criadores de conteúdo que gostam de ouvir livros, essa ferramenta pode ser usada para converter eBooks, artigos longos ou romances da Web em audiolivros. Seu recurso de processamento de texto longo pode fazer automaticamente o corte e a emenda para gerar arquivos de áudio completos. - Assistentes pessoais de voz
Os desenvolvedores podem integrar suas APIs em seus aplicativos para adicionar anúncios de voz a eles, como a leitura de notícias, previsões do tempo ou mensagens de notificação. - Dublagem de conteúdo de vídeo
Os criadores de mídia própria podem usá-lo para gerar uma narração ou voice-over ao fazer vídeos. É mais eficiente e menos dispendioso do que as gravações ao vivo, e você pode alterar a cópia e gerar novamente a narração a qualquer momento. - Recursos de aprendizagem
Os alunos de idiomas podem inserir palavras ou frases e gerar pronúncia padronizada para imitação. Os materiais didáticos também podem ser convertidos em áudio para serem ouvidos durante o trajeto para o trabalho ou exercícios.
QA
- Qual é a diferença entre esse projeto e o uso direto do modelo KittenTTS?
Este projeto é um invólucro com "serviços" em torno do modelo KittenTTS, que resolve os problemas de configuração complexa do ambiente, falta de uma interface de usuário e falta de aceleração de GPU ao usar o modelo diretamente. Ele resolve os problemas de configuração complexa do ambiente, falta de interface com o usuário, incapacidade de lidar com textos longos e falta de suporte para aceleração de GPU ao usar o modelo diretamente. O Kitten-TTS-Server fornece uma interface da Web e serviços de API prontos para uso, facilitando a utilização pelo usuário comum. - O que devo fazer se encontrar erros relacionados ao eSpeak durante a instalação?
Esse é o problema mais comum. Certifique-se de ter instalado o eSpeak NG corretamente para o seu sistema operacional e de ter reiniciado o terminal de linha de comando após a instalação. Se o problema persistir, verifique se o eSpeak NG está instalado em um caminho padrão em seu sistema. - Como posso confirmar que a aceleração da GPU está em vigor?
Primeiro, certifique-se de que você instalou todas as dependências da forma como elas são para as GPUs NVIDIA. Em seguida, você pode executarpython -c "import torch; print(torch.cuda.is_available())"se ele retornarTrueindicando que o ambiente está configurado corretamente. Enquanto o servidor estiver em execução, você também pode configurar o ambiente por meio do Gerenciador de tarefas ou donvidia-smipara visualizar o uso da GPU. - O que devo fazer se o servidor for iniciado com a mensagem "A porta está ocupada"?
Isso significa que já existem outros programas em seu computador que ocupam a porta 8005. Você pode modificar aconfig.yamlarquivo, que iráserver.portpara outro número de porta desocupado (por exemplo8006) e, em seguida, reinicie o servidor.



























