



Reconhecimento inteligente de documentos do Guava (intelligent_document_recognition) é um software de desktop de código aberto desenvolvido pelo desenvolvedor jiangnanboy, hospedado no GitHub, com foco no reconhecimento inteligente de documentos e formulários para processamento off-line. O software integra o reconhecimento óptico de caracteres (OCR) e o reconhecimento da estrutura de formulários, e não requer conexão com a Internet para ser executado, a fim de garantir a privacidade e a segurança dos dados. Os usuários podem extrair textos e tabelas de imagens ou PDFs e salvá-los nos formatos txt, html ou excel. O software é compatível com interfaces em inglês e chinês e a versão mais recente, v2.1, adiciona reconhecimento de captura de tela e exclusão de lista de imagens para facilitar a operação. O Guava Intelligent Document Recognition é adequado para usuários pessoais, comerciais ou educacionais que lidam com documentos, especialmente em cenários em que os dados precisam ser organizados de forma eficiente.
Lista de funções
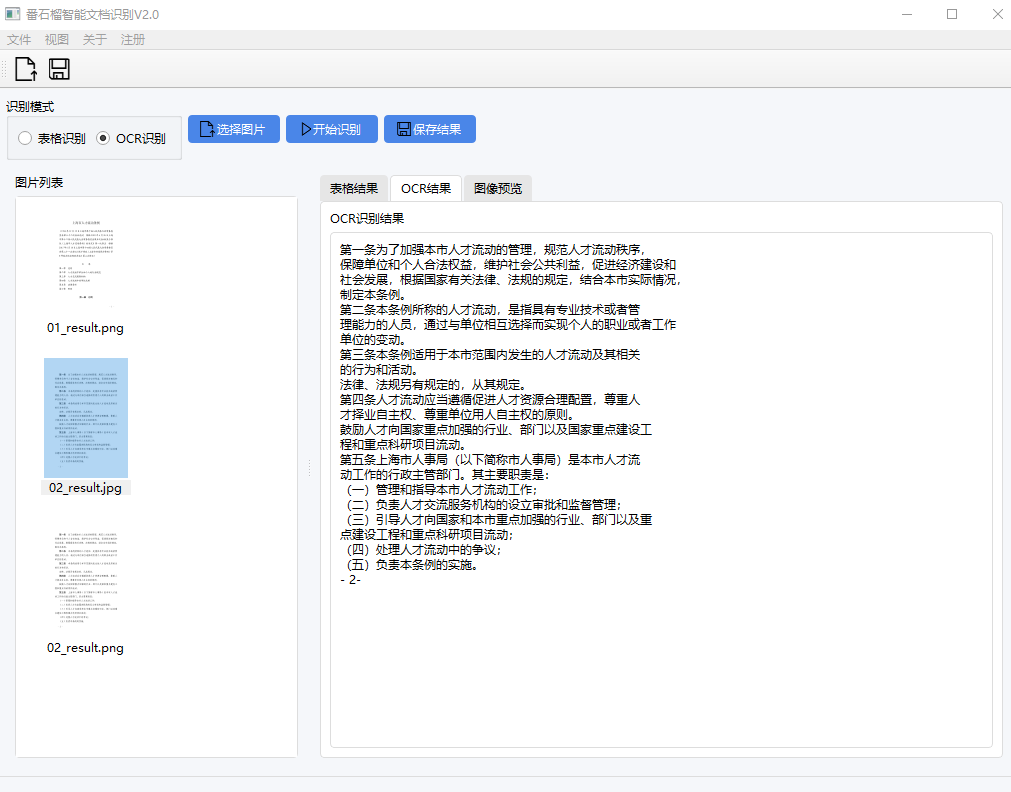
- Reconhecimento de OCR off-line: extraia texto de imagens ou PDFs sem conexão com a Internet.
- Reconhecimento da estrutura do formulário: analisa automaticamente o conteúdo do formulário e o produz em formato html ou excel.
- Reconhecimento de capturas de tela (v2.1): coloque o mouse sobre o conteúdo da tela e extraia o texto em tempo real.
- Gerenciamento da lista de imagens: suporte para exclusão de arquivos de imagem na barra lateral esquerda.
- Saída em vários formatos: os resultados do reconhecimento podem ser salvos como arquivos txt, html ou excel.
- Interface em chinês e inglês: estão disponíveis versões em chinês e inglês, com interface de operação amigável.
Usando a Ajuda
Processo de instalação
O Guava Smart Document Recognition é um software de desktop que precisa ser baixado e instalado em seu dispositivo local. Veja a seguir as etapas detalhadas de instalação:
- Download de software
Os pacotes de instalação estão disponíveis em chinês e inglês. O download da versão mais recente (v2.1) pode ser feito nos seguintes canais:- Versão em chinês :
- Baidu.com:
https://pan.baidu.com/s/1owzG74DLPxq6czEQC7ZNwQ(Código de extração: nt3z) - Cara de abraço:
https://huggingface.co/jiangnanboy/intelligent_document_recognition
- Baidu.com:
- Versão em inglês :
- Baidu.com:
https://pan.baidu.com/s/1Cv-hG6fMDUhj9dd3Et1RuA(Código do extrato: rkrd) - Cara de abraço:
https://huggingface.co/jiangnanboy/intelligent_document_recognition
Após o download, extraia o zip em um diretório local, por exemploC:\guava_document_recognition。
- Baidu.com:
- Versão em chinês :
- Instalação do Tesseract OCR
O software conta com o mecanismo de OCR do Tesseract para reconhecimento de texto. As etapas de instalação são as seguintes:- Windows Faça o download do instalador do GitHub do Tesseract e instale-o.
- Linux Executar comando
sudo apt-get install tesseract-ocr。 - Mac Executar comando
brew install tesseract。
Após a conclusão da instalação, certifique-se de que o caminho para o executável do Tesseract tenha sido adicionado às variáveis de ambiente do sistema (os usuários do Windows precisarão configurar isso manualmente).
- software operacional
Depois de descompactar o pacote, clique duas vezes para executarintelligent_document_recognition.exe(Windows) ou o executável correspondente. A primeira execução carregará o modelo de OCR, o que pode levar alguns segundos. Depois que o software for iniciado, selecione a interface em chinês ou inglês (dependendo da versão baixada).
Uso
O Guava Intelligent Document Recognition oferece uma interface gráfica intuitiva que suporta a operação das seguintes funções:
- Reconhecimento de OCR off-line
- Abra o software e clique no botão "File Upload" para importar imagens (JPG, PNG) ou arquivos PDF.
- Clique no botão "OCR Recognition" (Reconhecimento de OCR) e o software extrairá automaticamente o texto do arquivo.
- Os resultados do reconhecimento são exibidos na caixa de texto à direita e podem ser editados ou salvos pelo usuário como
txt或htmlFormato:- Clique no botão "Save" (Salvar) para selecionar o formato de saída e o caminho de salvamento.
- Exemplo: Faça upload de uma imagem das atas, o software extrai o texto e o salva como
notes.txt。
- Identificação da estrutura do formulário
- Faça upload de uma imagem ou arquivo PDF contendo o formulário.
- Selecione a opção "Form Recognition" (Reconhecimento de formulário) e o software analisará automaticamente o conteúdo do formulário.
- Os resultados podem ser salvos como
html或excelFormato:- Clique no botão "Export Table" (Exportar tabela), selecione o formato e salve-o.
- Exemplo: Carregar PDF de demonstrativo financeiro, gerado por software
report.xlsxque contém os dados completos da tabela.
- Reconhecimento de capturas de tela (Novo na v2.1)
- Clique no botão "Screenshot" (Captura de tela) e a interface do software será ocultada automaticamente.
- Use o mouse para enquadrar uma área-alvo na tela (por exemplo, uma página da Web ou o conteúdo de um documento).
- Depois de soltar o mouse, o software reconhece o texto na área em caixa e o exibe na caixa de texto.
- O usuário pode editar ou salvar os resultados como
txt或html。 - Exemplo: Coloque o cronograma do curso na tela, o software extrai o texto e o salva como
schedule.txt。
- Gerenciamento da lista de imagens
- A coluna esquerda do software exibe uma lista das imagens carregadas.
- Selecione as imagens indesejadas e clique no botão "Delete" (Excluir) ou pressione o botão
Deletepara removê-la. - Essa função é adequada para o processamento em lote para limpar arquivos inúteis.
- Troca de interface em chinês e inglês
- O software exibe uma interface em chinês ou inglês, dependendo da versão baixada, com a mesma lógica operacional.
- Por exemplo, a versão em chinês mostra "File Upload" e a versão em inglês mostra "Upload File".
- Os usuários podem escolher a versão de idioma apropriada de acordo com suas necessidades.
- arquivo de lote
- Coloque várias imagens ou PDFs em uma pasta especificada no software (por exemplo
input(pasta). - Selecione a função "Batch Recognition" (Reconhecimento em lote), o software processa automaticamente todos os arquivos e salva os resultados.
- O arquivo de saída é salvo por padrão na pasta
outputvocê pode alterar o caminho nas configurações.
- Coloque várias imagens ou PDFs em uma pasta especificada no software (por exemplo
Configuração e otimização
- Ajuste do formato de saída Editar o diretório raiz do software
config.inidefina o formato de saída padrão ou o caminho de salvamento:
[Output]
default_format = txt
save_path = ./output
- Maior precisão na identificação Imagem de alta resolução (pelo menos 300 DPI) funciona melhor. Arquivos difusos ou de baixa qualidade podem resultar em erros de reconhecimento.
- depuração de registros Se o resultado da identificação for impreciso, verifique o
logsarquivo de registro na pasta para analisar a causa do erro. - otimização do desempenho Quando estiver processando arquivos grandes, feche outros programas que consomem muitos recursos para aumentar a velocidade de processamento.
advertência
- Qualidade dos documentos Imagens ou PDFs carregados precisam ser nítidos e evitar borrões ou distorções para garantir um reconhecimento preciso.
- Compatibilidade do sistema O software é compatível com Windows, Linux e Mac e requer que o Tesseract OCR seja instalado corretamente.
- segurança de dados O software é executado totalmente off-line e os dados não são carregados na nuvem, o que o torna adequado para o manuseio de informações confidenciais.
- Software atualizado Observação: Basta verificar regularmente o Baidu.com ou o Hugging Face para baixar a versão mais recente e substituir a pasta da versão antiga.
- Suporte de contato Se tiver alguma dúvida, entre em contato com o desenvolvedor por meio do número público "Guava AI" no WeChat.
cenário do aplicativo
- Gerenciamento de documentos corporativos
Os usuários corporativos fazem upload de contratos, faturas ou declarações digitalizadas, extraem texto e tabelas e geram rapidamente documentos editáveis para aumentar a eficiência do escritório. - Suporte à pesquisa acadêmica
Os pesquisadores processam PDFs de artigos acadêmicos, extraem textos ou tabelas importantes e os organizam em arquivos txt ou excel para facilitar a análise de dados. - Coleta de recursos educacionais
Os professores carregam cópias digitalizadas de provas ou livros didáticos, extraem tópicos ou conteúdos de tabelas, organizam materiais didáticos e oferecem suporte à operação off-line. - Melhoria da eficiência pessoal
Os usuários usam a função de captura de tela para extrair rapidamente o texto da tela, como atas de reuniões ou conteúdo da Web, e salvá-lo como um arquivo editável.
QA
- O Guava Intelligent Document Recognition requer uma conexão com a Internet?
O software é executado totalmente off-line e o processamento de dados é feito localmente para proteger a privacidade e a segurança. - Quais formatos de arquivo são suportados?
JPG, PNG, PDF e outros formatos são suportados. Arquivos de alta resolução são recomendados para melhorar o reconhecimento. - Como faço para lidar com texto reconhecido incorretamente?
Verifique a clareza do arquivo de entrada ou ajuste a sensibilidade do OCR nas configurações do software. Se o problema não for resolvido, entre em contato com o desenvolvedor para obter feedback. - O reconhecimento de formulários é compatível com formulários complexos?
Suporte para tabelas regulares, tabelas aninhadas complexas podem exigir o pré-processamento de imagens para melhorar a precisão. - Como faço para atualizar para a versão mais recente?
Faça o download da versão 2.1 em Baidu.com ou Hugging Face, descompacte-a e substitua a pasta da versão antiga.































