



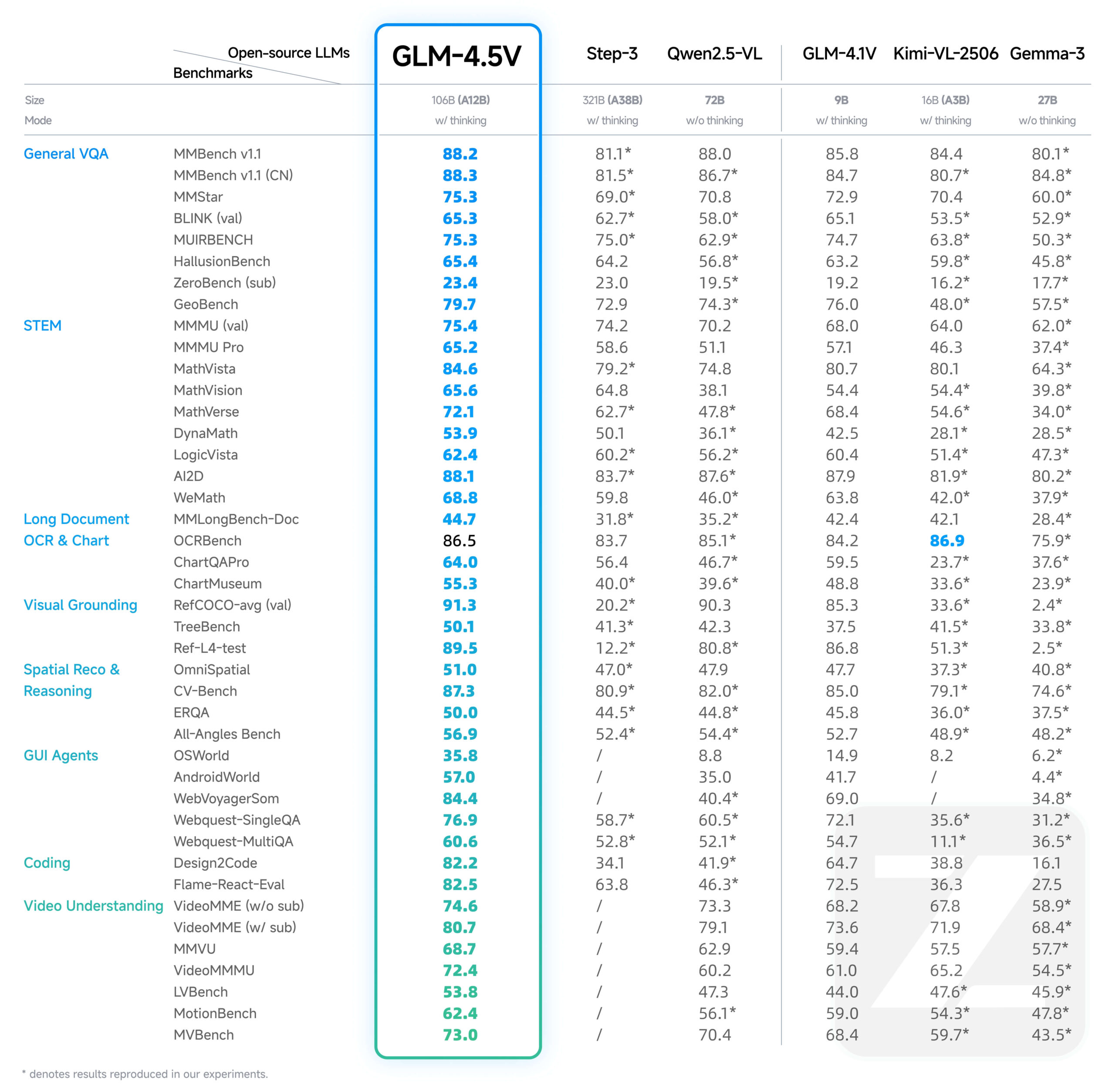
O GLM-4.5V é uma nova geração do Visual Language Megamodel (VLM) desenvolvido pela Zhipu AI (Z.AI). O modelo foi desenvolvido com base no principal modelo de texto GLM-4.5-Air, que adota a arquitetura MOE, com um número total de 106 bilhões de referências, das quais 12 bilhões são parâmetros de ativação. O GLM-4.5V não só lida com imagens e textos, mas também compreende conteúdo de vídeo, e suas principais competências abrangem raciocínio de imagens complexas, compreensão de vídeos longos, análise de conteúdo de documentos e operações de interface gráfica do usuário (GUI), entre outras tarefas. Para equilibrar a eficiência e a eficácia em diferentes cenários, o modelo introduz um interruptor "Thinking Mode" que permite aos usuários alternar entre tarefas que exigem resposta rápida ou raciocínio profundo. O modelo suporta um comprimento máximo de saída de 64 mil tokens e tem código aberto no Hugging Face sob a licença MIT, permitindo que os desenvolvedores o utilizem comercialmente e para desenvolvimento secundário.
Lista de funções
- Geração de código de página da WebAnálise de capturas de tela ou gravações de tela de páginas da Web para entender seu layout e lógica de interação e gerar diretamente códigos HTML e CSS totalmente utilizáveis.
- AterramentoLocalizar e identificar com precisão objetos específicos em uma imagem ou vídeo, e ser capaz de fazê-lo na forma de coordenadas (por exemplo, o que é uma imagem ou um vídeo).
[x1,y1,x2,y2]) retornam ao local de destino para cenários como segurança, controle de qualidade e auditoria de conteúdo. - Inteligência de GUIA capacidade de reconhecer e processar capturas de tela e executar ações como clicar, deslizar e modificar o conteúdo em resposta a comandos oferece suporte para que as inteligências executem tarefas automatizadas.
- Interpretação de documentos longos e complexosAnálise profunda de dezenas de páginas de relatórios gráficos complexos, com suporte a resumos de conteúdo, traduções, extração de gráficos e capacidade de fornecer insights com base no conteúdo do documento.
- Reconhecimento e raciocínio de imagensCapacidade de compreensão de cenas e de raciocínio lógico, capaz de inferir as informações contextuais por trás de uma imagem com base apenas em seu conteúdo, sem depender de pesquisa externa.
- Compreensão de vídeoAnálise de conteúdo de vídeo longo e identificação precisa de tempo, pessoas, eventos e as relações lógicas entre eles no vídeo.
- Perguntas e respostas disciplinaresCapacidade de resolver problemas complexos combinando gráficos e texto, especialmente adequado para resolver e explicar exercícios em cenários de educação K12.
Usando a Ajuda
O GLM-4.5V oferece aos desenvolvedores uma variedade de maneiras de acessá-lo e usá-lo, incluindo a integração rápida por meio da API oficial e a implementação local por meio do Hugging Face.
1. use por meio da API de plataforma aberta do Wisdom Spectrum AI (recomendado)
Usar a API oficial é a maneira mais conveniente para os desenvolvedores que desejam integrar rapidamente os modelos em seus aplicativos. Essa abordagem elimina a necessidade de gerenciar recursos complexos de hardware.
Preços de API
- importação: ¥0,6 / milhão tokens
- exportações: ¥1,8 / milhão de tokens
etapa de invocação
- Obter chave de APIAcesse a plataforma aberta de IA do Smart Spectrum para registrar uma conta e criar uma chave de API.
- Instalação do SDK:
pip install zhipuai - Escreva o código de chamadaExemplo de uma chamada de API usando o Python SDK, demonstrando como enviar uma imagem e um texto para fazer uma pergunta.
from zhipuai import ZhipuAI # 使用你的API Key进行初始化 client = ZhipuAI(api_key="YOUR_API_KEY") # 请替换成你自己的API Key response = client.chat.completions.create( model="glm-4.5v", # 指定使用GLM-4.5V模型 messages=[ { "role": "user", "content": [ { "type": "text", "text": "这张图片里有什么?请详细描述一下。" }, { "type": "image_url", "image_url": { "url": "https://img.alicdn.com/imgextra/i3/O1CN01b22S451o81U5g251b_!!6000000005177-0-tps-1024-1024.jpg" } } ] } ] ) print(response.choices[0].message.content)
Ativação do "Modo de Pensamento"
Para tarefas complexas que exigem um raciocínio mais profundo do modelo (por exemplo, análise de gráficos complexos), você pode adicionar a opçãothinkingpara ativar o "modo pensar".
Abaixo está uma lista das maneiras mais comuns de usar ocURLExemplo oficial de chamada e ativação do Modo de Pensamento:
curl --location 'https://api.z.ai/api/paas/v4/chat/completions' \
--header 'Authorization: Bearer YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "glm-4.5v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://cloudcovert-1305175928.cos.ap-guangzhou.myqcloud.com/%E5%9B%BE%E7%89%87grounding.PNG"
}
},
{
"type": "text",
"text": "桌子上从右数第二瓶啤酒在哪里?请用[[xmin,ymin,xmax,ymax]]格式提供坐标。"
}
]
}
],
"thinking": {
"type":"enabled"
}
}'
2) Implementação local por meio de transformadores Hugging Face
Para pesquisadores e desenvolvedores que precisam de desenvolvimento secundário ou uso off-line, os modelos podem ser baixados do Hugging Face Hub e implantados em seu próprio ambiente.
- Requisitos ambientais: a implementação local requer um forte suporte de hardware, geralmente uma GPU NVIDIA de alto desempenho com grande memória de vídeo (por exemplo, A100/H100).
- Instalação de dependências:
pip install transformers torch accelerate Pillow - Carregar e executar o modelo:
import torch from PIL import Image from transformers import AutoProcessor, AutoModelForCausalLM # Hugging Face上的模型路径 model_path = "zai-org/GLM-4.5V" processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True) # 加载模型 model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, trust_remote_code=True ).to("cuda").eval() # 准备图片和文本提示 image = Image.open("path_to_your_image.jpg").convert("RGB") prompt_text = "请使用HTML和CSS,根据这张网页截图生成一个高质量的UI界面。" prompt = [{"role": "user", "image": image, "content": prompt_text}] # 处理输入并生成回复 inputs = processor.apply_chat_template(prompt, add_generation_prompt=True, tokenize=True, return_tensors="pt", return_dict=True) inputs = {k: v.to("cuda") for k, v in inputs.items()} gen_kwargs = {"max_new_tokens": 4096, "do_sample": True, "top_p": 0.8, "temperature": 0.6} with torch.no_grad(): outputs = model.generate(**inputs, **gen_kwargs) response_ids = outputs[:, inputs['input_ids'].shape[1]:] response_text = processor.decode(response_ids[0]) print(response_text)
cenário do aplicativo
- Automação do desenvolvimento front-end
Os desenvolvedores podem fornecer uma captura de tela de uma página da Web bem projetada, e o GLM-4.5V pode analisar diretamente o layout da interface do usuário, o esquema de cores e os estilos de componentes na captura de tela e gerar automaticamente os códigos HTML e CSS correspondentes, o que melhora muito a eficiência do desenvolvimento, desde o rascunho do design até a página estática. - Segurança e vigilância inteligentes
Em cenários de monitoramento de segurança, o modelo pode analisar fluxos de vídeo em tempo real e marcar com precisão o local do alvo na tela de acordo com comandos (por exemplo, "Localize todas as pessoas de vermelho na imagem"), que podem ser usados para rastreamento de pessoas, detecção de comportamento anormal e assim por diante. - Inteligência de automação de escritório
No software de escritório, os usuários podem concluir operações complexas por meio do modelo de comando de linguagem natural. Por exemplo, o usuário pode dizer "Por favor, altere os dados na primeira linha da tabela na quarta página do PPT para '89', '21', '900'", e o modelo reconhecerá o conteúdo da tela e simulará operações de mouse e teclado para concluir a modificação. "O modelo reconhecerá o conteúdo da tela e simulará operações de mouse e teclado para concluir a modificação. - Pesquisa e análise de documentos financeiros
Um pesquisador ou analista pode carregar dezenas de páginas de relatórios financeiros ou de pesquisa em formato PDF e solicitar ao modelo que "resuma os pontos principais do relatório e converta os principais dados do Capítulo 3 em uma tabela Markdown". O modelo lê detalhadamente e extrai as informações, gerando resumos e gráficos estruturados. - Aconselhamento educacional K12
Os alunos podem tirar uma foto de um problema de aplicação de matemática ou física (contendo diagramas e texto) e fazer perguntas ao modelo. O modelo não apenas fornece a resposta correta, mas também atua como um professor, explicando passo a passo as ideias e fórmulas usadas para resolver o problema e fornecendo um processo de solução detalhado.
QA
- Qual é a relação entre GLM-4.5V e GLM-4.1V?
O GLM-4.5V é uma continuação e uma atualização iterativa da linha de tecnologia GLM-4.1V-Thinking. Ele foi desenvolvido com base no modelo carro-chefe de texto simples mais potente, o GLM-4.5-Air, e, com base na herança dos recursos do modelo predecessor, aprimora de forma abrangente o desempenho em todos os tipos de tarefas multimodais visuais. - Qual é o custo de usar a API GLM-4.5V?
A taxa de faturamento para usar o modelo por meio da API oficial do Wisdom Spectrum AI é de RMB 0,6 por milhão de tokens no lado da entrada e RMB 1,8 por milhão de tokens no lado da saída. - O que exatamente o "Modo de pensar" (Thinking Mode) faz?
"O Thinking Mode foi projetado para tarefas complexas que exigem raciocínio profundo. Quando ativado, o modelo passa mais tempo pensando logicamente e integrando informações para produzir respostas mais precisas e de melhor qualidade, mas com tempos de resposta mais longos. Ele é adequado para cenários como a análise de diagramas complexos, a criação de códigos ou a interpretação de documentos longos. Para perguntas e respostas simples, pode ser usado um modelo de resposta mais rápida e sem raciocínio.



























