

Ao criar aplicativos de consulta à base de conhecimento com base em modelos de linguagem ampla (LLMs), os desenvolvedores geralmente empregam técnicas de geração aumentada de recuperação (RAG). No entanto, a eficácia prática da RAG geralmente é limitada por um paradoxo central: como equilibrar a recuperação deprecisãocontextualcompletudeSe o trecho de texto for muito pequeno, ele poderá responder com precisão à consulta do usuário, mas não fornecerá contexto suficiente para o LLM, levando a uma diminuição na qualidade da resposta. Se a fatia de texto (Chunk) for muito pequena, embora possa responder com precisão à consulta do usuário, o contexto fornecido ao LLM é insuficiente, o que leva a uma diminuição da qualidade da resposta; se a fatia for muito grande, embora o contexto esteja completo, pode haver muito ruído, o que, por sua vez, reduz a precisão da recuperação.
Para enfrentar esse desafio. Dify Introduzido na versão 1.9.0 como um novo recurso chamado Parent-child-HQ Um modelo de pipeline de processamento de conhecimento incorporado. O modelo adota a estratégia "Parent-Child Chunking" (fragmentação pai-filho), por meio de um método inteligente de fragmentação hierárquica, tentando obter o peixe e a pata do urso ao mesmo tempo. Neste artigo, analisaremos esse recurso a partir do conceito central, da configuração prática e da implementação do código-fonte em três níveis.
Conceito central: estratégia de fragmentação entre pai e filho
A ideia central da estratégia de "chunking pai-filho" é estruturar as informações de texto em dois níveis para processamento, de modo a desacoplar os diferentes requisitos de granularidade de texto entre a correspondência de recuperação e a geração de conteúdo.
- Pedaços filhos para correspondência exataSub-arranjos: O documento original é dividido em uma série de "sub-arranjos" finos e altamente concentrados. Esses subconjuntos são geralmente uma frase ou um parágrafo curto e são usados exclusivamente para o cálculo da similaridade semântica com o vetor de consulta do usuário. Devido à sua pequena granularidade, é possível obter correspondências muito precisas.
- Os Parent Chunks são usados para fornecer o contexto completoCada subunidade pertence a um "pai" maior, que pode ser um parágrafo completo, uma seção ou até mesmo um documento inteiro. Depois que o sistema seleciona as correspondências mais relevantes por meio dos pedaços filhos, é o "pedaço pai" completo, que contém os pedaços filhos, que é de fato alimentado no LLM para a geração de conteúdo.
Esse mecanismo garante que o LLM "leia" o contexto original mais completo no qual as informações correspondentes estão localizadas ao responder a uma pergunta, gerando assim uma resposta logicamente coerente e informativa.
Essa estratégia avançada se baseia na recuperação de vetores para calcular a similaridade semântica e, portanto, só é compatível com a base de conhecimento Dify no HQ (alta qualidade) Modo de indexação. O modo de alta qualidade vetoriza o texto por meio do modelo Embedding, oferecendo suporte à recuperação de vetores e à recuperação híbrida, enquanto o modo econômico constrói apenas o índice invertido com base em palavras-chave, o que não pode atender aos requisitos de operação de chunking pai-filho.

Guia prático: Configuração da base de conhecimento do Parent-Child-HQ
Para usar esse recurso na Dify, primeiro você precisa instalar o Parent-child-HQ Esta base de conhecimento lida com modelos de processos.
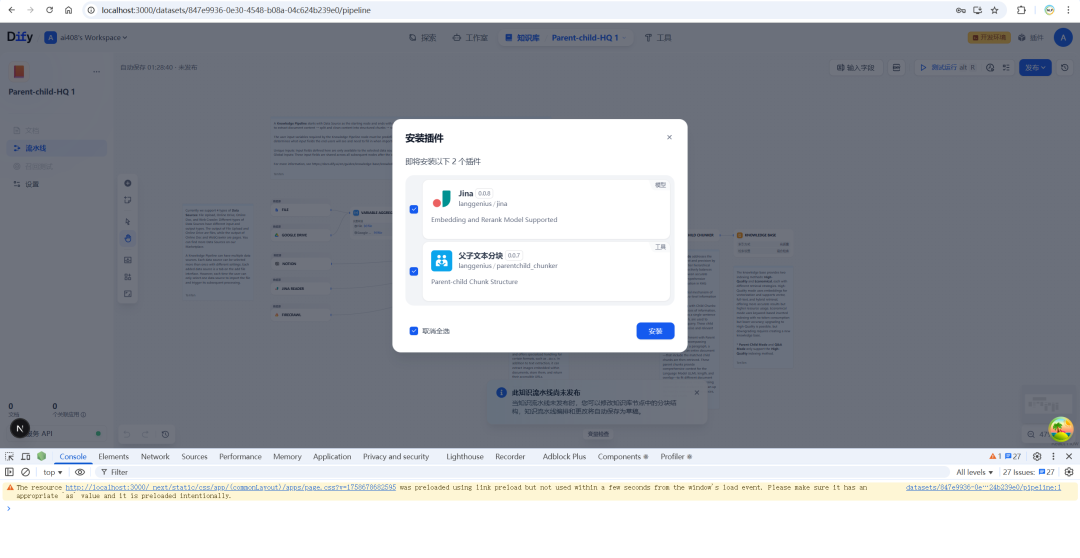
Após a instalação, o nó mais central do pipeline é o "bloco de texto pai-filho".
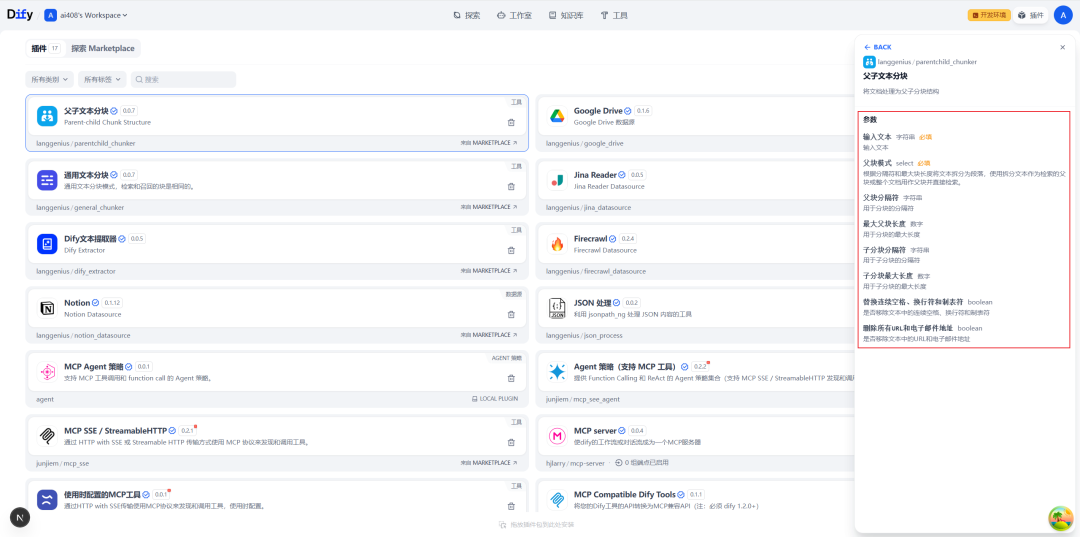
Configuração do nó de chunking
Na tela de configurações desse nó, é possível definir detalhadamente as regras de divisão dos blocos pai e filho.
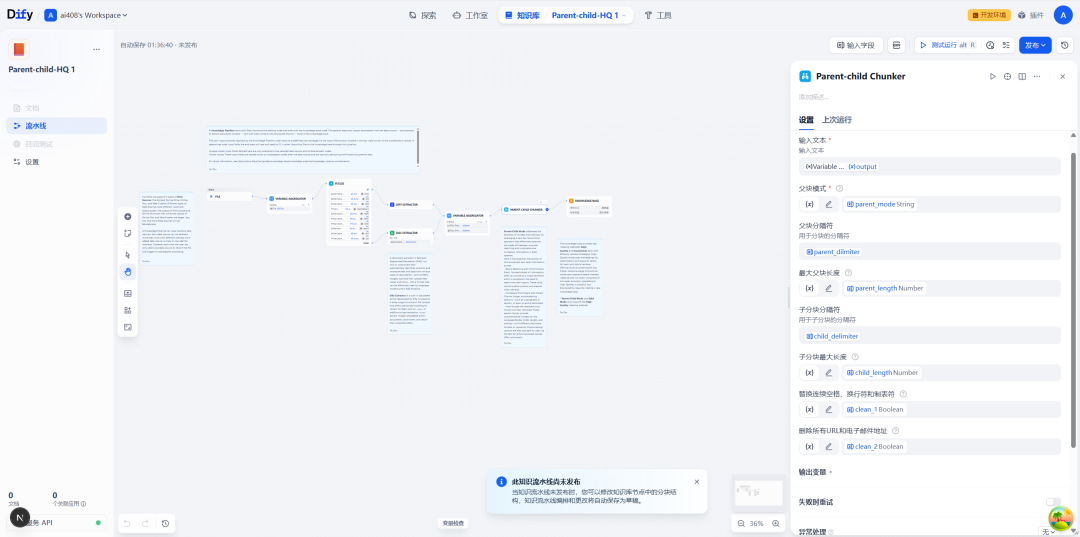
| item de configuração | instruções |
|---|---|
| separador de bloco pai | Define como cortar o bloco pai. Isso geralmente é feito usando a função \n\n(duas quebras de linha) para dividir por parágrafo. |
| Comprimento máximo do bloco pai | Limite máximo de caracteres para um único bloco pai. |
| separador de subchunk | Define como fatiar ainda mais os sub-blocos dentro do bloco pai. Isso pode ser feito usando a função \n(caractere de nova linha simples) Dividir por linha. |
| Comprimento máximo do subchunk | Limite máximo de caracteres para um único sub-bloco. |
| modelo de bloco pai | Definir o escopo do bloco pai, fornecer paragraph(parágrafos) e full_doc(documentação completa) dois modos. |
Nesse caso, o "padrão de bloco pai" determina o limite de macro do contexto:
- Padrões de parágrafo (
paragraph mode)Separação de texto em partes principais por separador (por exemplo, parágrafo). Esse é o modo mais comumente usado e atinge um bom equilíbrio entre precisão e escopo contextual. - Modo de texto completo (
full_doc mode): trata o documento inteiro como um bloco pai enorme (mais de 10.000) tokens (a parte que será truncada). Esse modo é adequado para cenários específicos em que é necessário um contexto global.
Além disso, as opções de pré-processamento permitem a remoção de espaços extras, URLs e endereços de e-mail do texto para melhorar a qualidade dos dados.
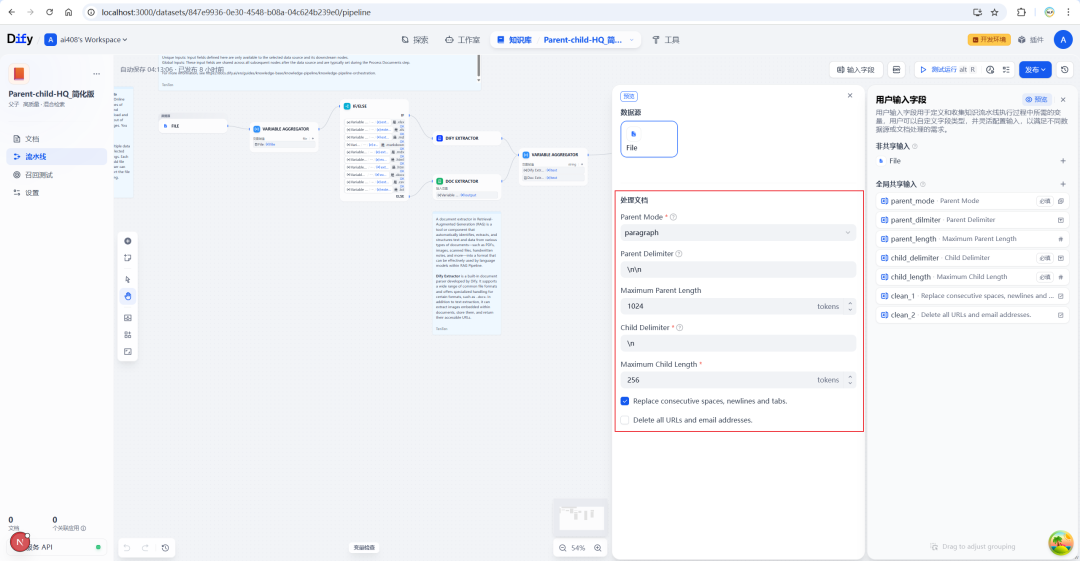
Configuração de um índice de alta qualidade
Conforme mencionado anteriormente.Parent-Child O modelo deve ser usado em conjunto com o índice HQ. Portanto, você precisa configurar o modelo Embedding e o modelo Rerank nas configurações da Base de Conhecimento.
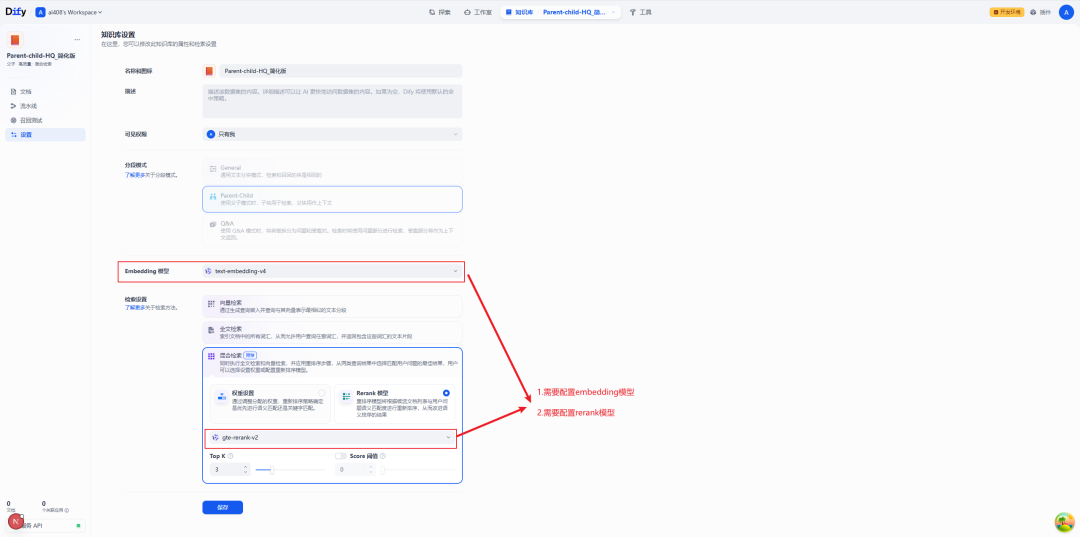
Comissionamento e operação
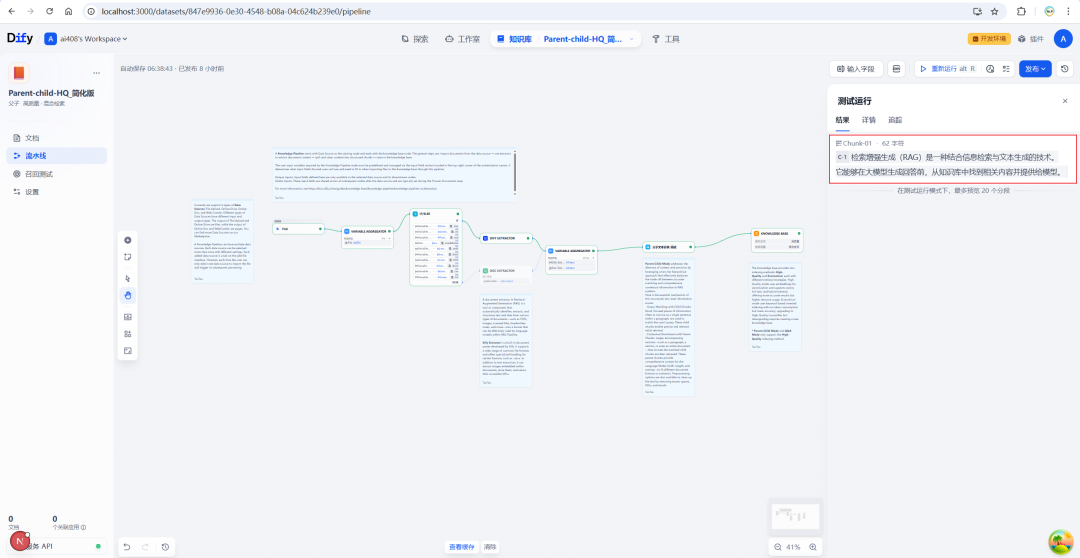
Depois de concluir todas as configurações, você pode testar o efeito de fragmentação por meio da função de depuração. Insira o texto de amostra e execute o pipeline para ver claramente como o texto original é organizado em estruturas pai-filho.
A execução final resulta em uma apresentação estruturada do bloco pai e da lista de blocos filhos que ele contém.
Mergulho profundo na arquitetura: lógica de implementação no nível do código
Para entender melhor como isso funciona, vamos nos aprofundar no parentchild_chunker O código-fonte do plug-in é analisado. O diagrama de tempo UML abaixo resume o fluxo completo do plug-in, desde a inicialização até o recebimento de dados, o processamento e o retorno dos resultados.
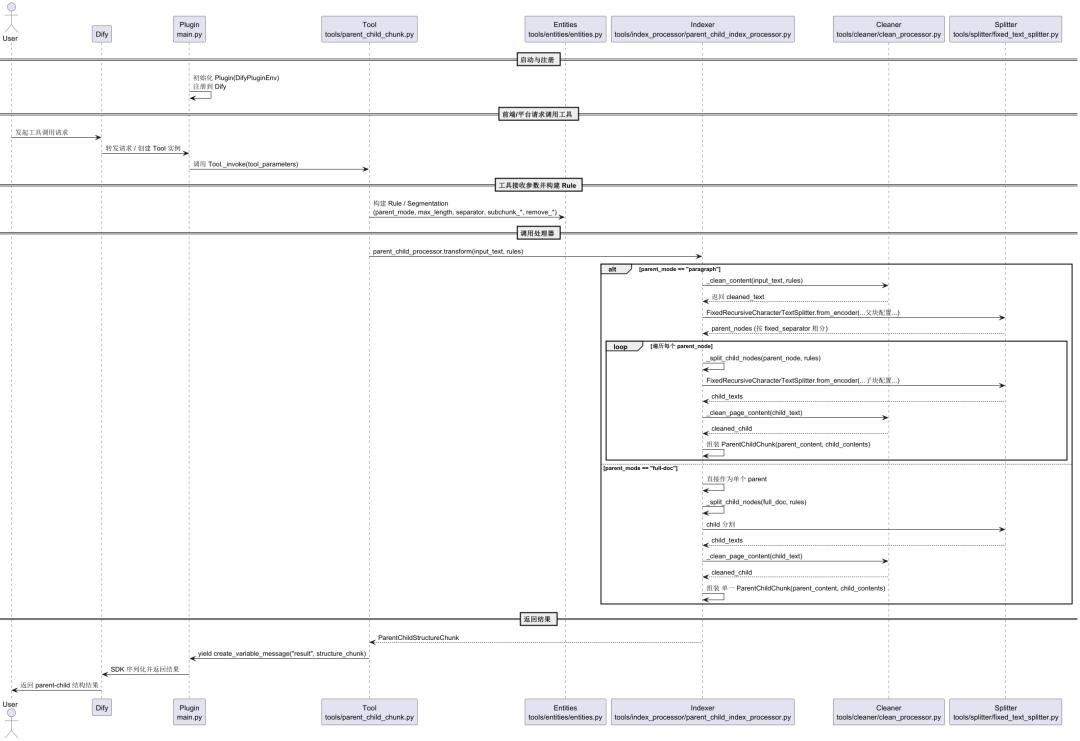
Todo o processo de processamento de dados pode ser resumido nas seguintes etapas principais:
1. lançamento do plug-in e invocação da ferramenta
Quando a plataforma Dify for lançada.main.py serve como ponto de entrada do plug-in e é responsável pela inicialização e pelo registro no Dify ParentChildChunkTool Os recursos da ferramenta Os formulários de front-end, os parâmetros de entrada e os formatos de saída da ferramenta são fornecidos pelo tools/parent_child_chunk.yaml Definição de arquivo.
Quando o usuário invoca a ferramenta, o Dify SDK instancia o tools/parent_child_chunk.py definido em ParentChildChunkTool e chamar sua classe _invoke que recebe os parâmetros passados pelo front-end (por exemplo, o método input_text、parent_mode etc.).
2. processamento de núcleo e limpeza de texto
_invoke A responsabilidade principal do método é chamar o tools/index_processor/parent_child_index_processor.py definido em ParentChildIndexProcessorÉ o pivô de toda a lógica de negócios. Esse é o pivô de toda a lógica de negócios.
Antes da fragmentação, o texto passará primeiro pelo processo de tools/cleaner/clean_processor.py acertou em cheio CleanProcessor Limpeza. Esse módulo é responsável por remover caracteres inválidos e mesclar seletivamente espaços redundantes ou remover URLs e endereços de e-mail de acordo com a configuração do usuário, garantindo a qualidade do texto que é processado posteriormente.
3. segmentação inteligente de texto
A segmentação de texto é o núcleo técnico da estratégia de fragmentação pai-filho e é realizada principalmente pelo tools/splitter/ Várias implementações de divisores no catálogo. Entre elas, aFixedRecursiveCharacterTextSplitter é a chave.
Duas classes principais precisam ser distinguidas aqui:
EnhanceRecursiveCharacterTextSplitterSeu principal aprimoramento é que ele oferece uma maneira de criar um novo sistema com base no número de caracteres (em vez do número de caracterestiktoken) calcula o comprimento do texto de forma a evitar a necessidade de depender de um tokenizador específico. A lógica de segmentação é consistente com os segmentadores de caracteres recursivos padrão.FixedRecursiveCharacterTextSplitterEsta classe adiciona uma etapa fundamental ao particionamento recursivo - oComece usando um sistema fixo e de alta prioridadefixed_separator(por exemplo, para parágrafos\n\n) para realizar a divisão inicial. Em seguida, a lógica recursiva interna é chamada novamente para subdividir apenas os blocos que excedem o limite de comprimento.
Essa estratégia de "divisão grosseira e, em seguida, refinamento" atende perfeitamente às necessidades da divisão pai-filho: primeiro por meio do \n\n Divida o bloco pai semanticamente completo (parágrafo) e, em seguida, use delimitadores mais finos dentro do bloco pai (por exemplo \n) Corte os sub-blocos.
4. construção e retorno da estrutura de dados
Após a limpeza e a divisãoParentChildIndexProcessor será baseado em paragraph 或 full-doc que reúne uma lista de conteúdos de blocos pai e seus conteúdos de blocos filho correspondentes no padrão ParentChildChunk objetos. Esses objetos são eventualmente encapsulados no ParentChildStructureChunk na estrutura.
As definições dessas estruturas de dados estão localizadas no tools/entities/entities.pyO uso do modelo Pydantic garante que os dados sejam normalizados e consistentes.
Finalmente.ParentChildChunkTool aprovar (um projeto de lei ou inspeção etc.) yield self.create_variable_message(...) Os dados estruturados processados são devolvidos ao SDK da Dify, concluindo a execução de todo o nó do pipeline.
Com esse fluxo de processamento bem projetado e um divisor de texto flexível, oParent-child-HQ Os modelos oferecem aos desenvolvedores uma ferramenta avançada e elegante que resolve efetivamente o problema de RAG O dilema persistente da compensação entre contexto e precisão nos aplicativos.




























