

Prefácio: Criando fluxos de trabalho econômicos de geração e edição de imagens com IA
lit. dez mil perguntas sobre princípios gerais (expressão idiomática); fig. uma longa lista de perguntas e respostas Qwen-Image Como um modelo gráfico de código aberto gerado por texto, ele ganhou ampla atenção por sua capacidade superior de renderização de textos complexos, especialmente a geração de caracteres chineses. Em comparação com os modelos convencionais, ele pode incorporar com precisão conteúdo de texto de várias linhas e vários parágrafos em imagens, oferecendo novas possibilidades para design de pôsteres, criação de conteúdo e outros cenários.
No entanto, embora os modelos em si sejam de código aberto, o custo de invocar esses serviços por meio de plataformas comerciais costuma ser significativo. Por exemplo, os serviços de plug-in fornecidos por algumas plataformas podem custar até US$ 0,25 por imagem a ser gerada após o esgotamento da cota gratuita, o que representa uma sobrecarga significativa para os usuários que precisam gerar grandes quantidades ou iterar com frequência.
Neste documento, exploraremos um cenário alternativo que visa aproveitar as vantagens da Dify Plataforma de orquestração de aplicativos,ModelScope(Comunidade Magic Match) Qwen-Image e o plug-in Tencent Cloud Object Storage (COS), para criar uma inteligência de geração e edição de imagens (Agente) eficiente e econômica. O resultado final é o seguinte: o agente não apenas gera imagens com base no texto, mas também modifica as imagens geradas em diálogos subsequentes.

Preparação para a configuração do sistema
Antes de iniciar a construção, há vários componentes e serviços importantes que precisam estar prontos. O núcleo de todo o sistema é Dify plataforma Qwen Text2Image & Image2Image Plug-ins.
1. Dify Plugin Marketplace e Qwen-Image Plugin
Dify é um software de código aberto LLM Plataforma de desenvolvimento de aplicativos que permite aos usuários orquestrar e criar aplicativos por meio de uma interface visual AI Aplicativo. Em primeiro lugar, é necessário adicionar o Dify Localize e faça o download do marketplace de plug-ins para Qwen Text2Image & Image2Image Plug-ins.
2. credenciais de acesso à comunidade do ModelScope
ModelScope(Magic Hitch Community) é uma comunidade de código aberto de modelagem da Alibaba que fornece um grande número de modelos pré-treinados e API Serviço. Para usar o Dify superior Qwen-Image que requer um plug-in ModelScope baseado na comunidade API Key como credenciais de acesso.
Isso pode ser feito a partir do ModelScope Obtenha-o no centro pessoal do site oficial API Key:https://modelscope.cn/my/myaccesstoken
3. armazenamento de objetos em nuvem da Tencent (COS)
Qwen-Image A função de edição de imagem (imagem para imagem) exige que a imagem original inserida esteja acessível pela rede pública. URL Endereço. Para resolver esse problema, os serviços de armazenamento em nuvem podem ser utilizados. Neste artigo, o Tencent Cloud Object Storage (COS) para armazenar as imagens geradas e gerar links públicos para elas.
Necessidade de criar uma Tencent Cloud COS Bucket para uploads de imagens subsequentes. O processo de configuração não é descrito aqui, apenas certifique-se de que o Bucket tenha acesso público de leitura.
Endereço de acesso:https://console.cloud.tencent.com/cos/bucket
4. serviços de API para uploads de imagens
para incorporar Dify Imagens geradas no fluxo de trabalho carregadas para a Tencent Cloud COSPara que isso aconteça, é necessário um serviço intermediário para atuar como ponte. Esse serviço recebe Dify Envia o arquivo de imagem, executa uma operação de upload e, em seguida, retorna a rede pública da imagem URL。
Você pode usar o FastAPI Crie rapidamente esse serviço de interface. Aqui estão os principais Python Código:
Aviso de segurança: O código de amostra a seguir codifica diretamente o secret_id 和 secret_keyIsso representa um risco de segurança significativo. Em um ambiente de produção, onunca deveFaça isso. É altamente recomendável usar variáveis de ambiente, arquivos de configuração ou um serviço profissional de gerenciamento de chaves para armazenar e recuperar essas credenciais confidenciais.
import requests
import json
import base64
from PIL import Image
import io
import os
import sys
from qcloud_cos import CosConfig, CosS3Client
import datetime
import random
from fastapi import FastAPI, UploadFile, File
from pydantic import BaseModel
# --- 配置信息 ---
# 临时文件存储路径
output_path = "D:\\tmp\\zz"
# 腾讯云 COS 配置
region = "ap-guangzhou"
secret_id = "AKIDnRsFUYKwfNvHQQFsIj9WpwpWzEG5hAUi" # 替换为你的 SecretId
secret_key = "5xb1EF9*******ydFi1MYWHpMpBbtx" # 替换为你的 SecretKey
bucket = "jenya-130****694" # 替换为你的 Bucket 名称
app = FastAPI()
class GenerateImageRequest(BaseModel):
prompt: str
def generate_timestamp_filename(extension='png'):
"""根据时间戳和随机数生成唯一文件名"""
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
random_number = random.randint(1000, 9999)
filename = f"{timestamp}_{random_number}.{extension}"
return filename
def base64_to_image(base64_string, output_dir):
"""将 Base64 字符串解码并保存为图片文件"""
filename = generate_timestamp_filename()
output_filepath = os.path.join(output_dir, filename)
image_data = base64.b64decode(base64_string)
image = Image.open(io.BytesIO(image_data))
image.save(output_filepath)
print(f"图片已保存到 {output_filepath}")
return filename, output_filepath
def image_to_base64(image_data: bytes) -> str:
"""将图片文件流转换为 Base64 编码的字符串"""
return base64.b64encode(image_data).decode('utf-8')
def upload_to_cos(file_name, base_path):
"""上传本地文件到腾讯云 COS"""
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key)
client = CosS3Client(config)
file_path = os.path.join(base_path, file_name)
response = client.upload_file(
Bucket=bucket,
LocalFilePath=file_path,
Key=file_name
)
if response and 'ETag' in response:
print(f"文件 {file_name} 上传成功")
url = f"https://{bucket}.cos.{region}.myqcloud.com/{file_name}"
return url
else:
print(f"文件 {file_name} 上传失败")
return None
@app.post("/upload_image/")
async def upload_image_endpoint(file: UploadFile = File(...)):
"""接收图片文件,上传到 COS 并返回 URL"""
file_content = await file.read()
# 将上传的文件内容(二进制)直接转换为 Base64
image_base64 = image_to_base64(file_content)
# 将 Base64 保存为本地临时文件
filename, local_path = base64_to_image(image_base64, output_path)
# 上传到腾讯云 COS
public_url = upload_to_cos(filename, output_path)
if public_url:
return {
"filename": filename,
"local_path": local_path,
"url": public_url
}
else:
raise HTTPException(status_code=500, detail="Image upload to COS failed.")
if __name__ == "__main__":
import uvicorn
# 确保临时文件夹存在
if not os.path.exists(output_path):
os.makedirs(output_path)
uvicorn.run(app, host="0.0.0.0", port=8083)
Salve o código acima como main.py e executá-lo para iniciar um ouvinte no arquivo 8083 baseado em porta HTTP Serviços.

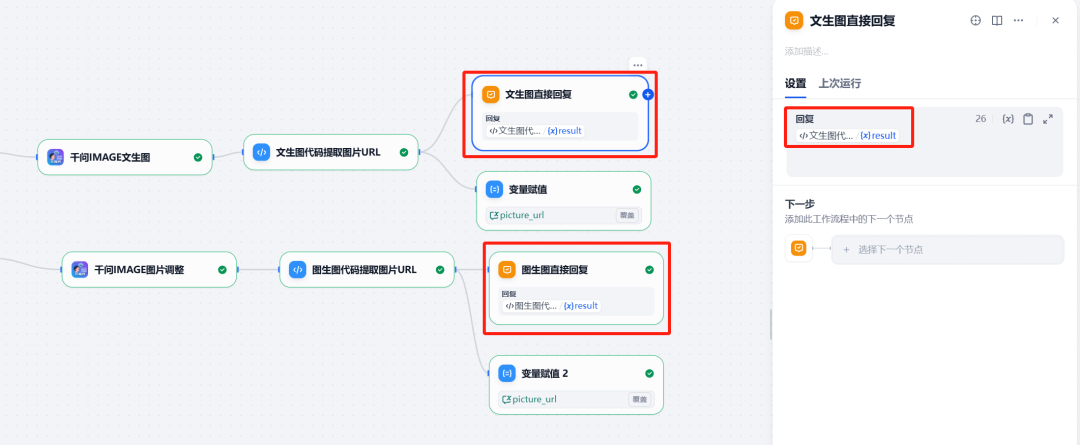
Processo de construção do fluxo de trabalho da Dify
A ideia central é implementar um corpo inteligente que possa realizar várias rodadas de diálogo, capaz de distinguir se a intenção do usuário é "gerar uma nova imagem" ou "modificar uma imagem antiga" e executar as ações correspondentes de acordo com a intenção.
Os principais nós incluem:
- extrator de parâmetrosDeterminação da intenção do usuário.
- Solicitação HTTPUpload da imagem gerada para o
APIserviço, obtenha a rede públicaURL。 - variável de sessãoArmazenamento de imagens
URLusado para edição de imagens em diálogos de várias rodadas.
1. nós iniciais
Esse nó atua como o ponto de entrada para o fluxo de trabalho e recebe entrada do usuário. Normalmente, é suficiente usar a configuração padrão.
2. extrator de parâmetros
Essa é a chave para a implementação da lógica de diálogo em várias rodadas. A entrada do usuário é analisada por um modelo de linguagem grande (recomenda-se escolher um modelo com forte capacidade de raciocínio) para determinar se a intenção é gerar uma imagem pela primeira vez ou modificar uma imagem existente. Com base no resultado do julgamento, uma variável is_update Atribuir valores diferentes (por exemplo 0 Representação do mapa bruto.1 (Indica uma mudança de mapa).
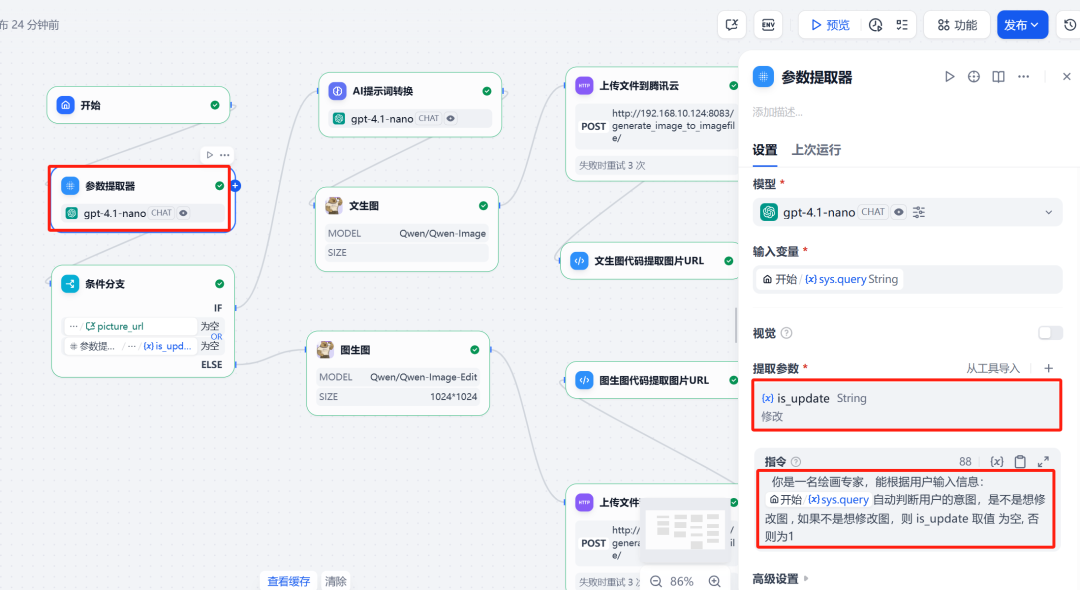
3. variáveis de sessão e ramificação condicional
Para "lembrar" a última imagem gerada na caixa de diálogo, é necessário definir uma variável de sessão. picture_url para armazenar imagens na rede pública URL。
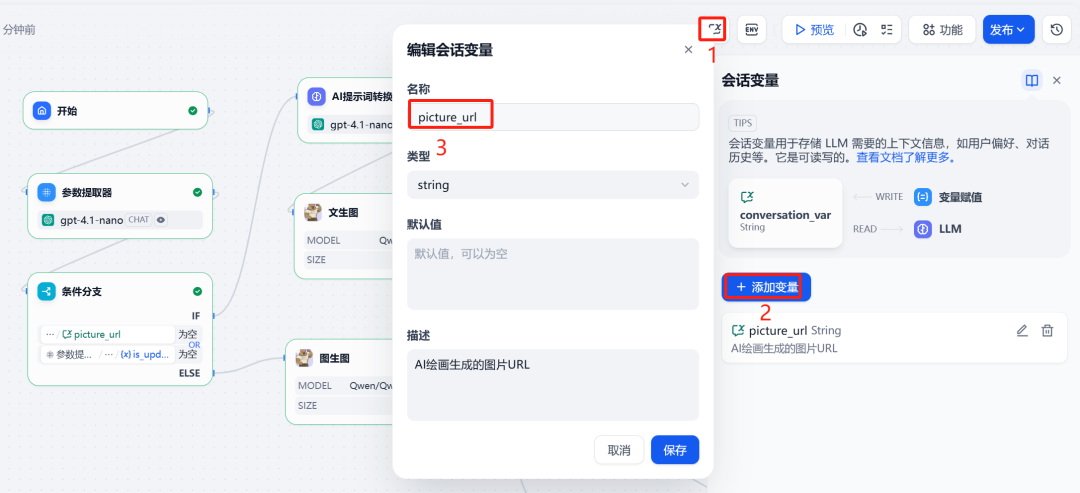
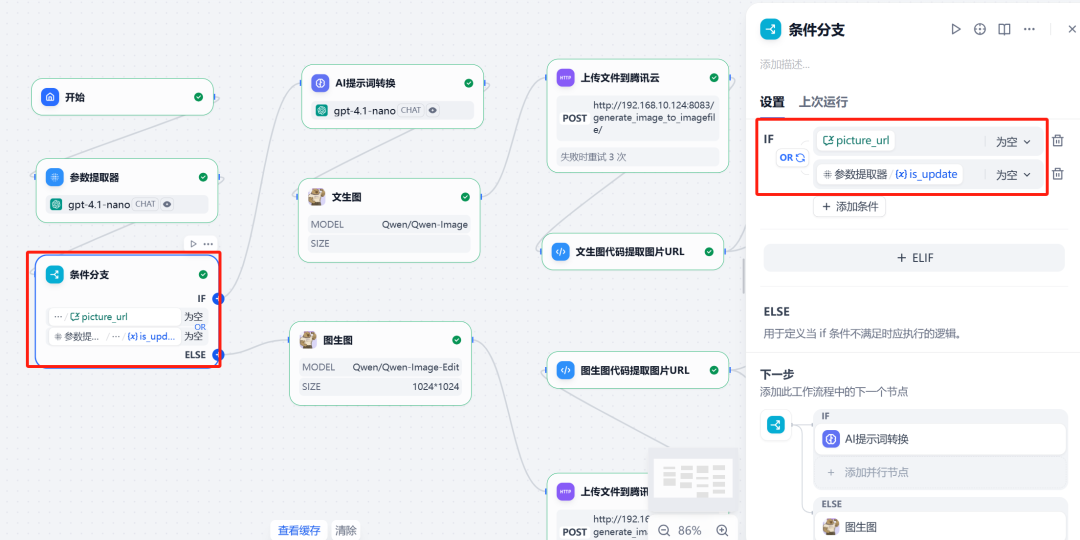
Em seguida, use oramificação condicionalNó. Esse nó cria diferentes caminhos de execução com base em duas condições:
- Ramo I (figura bruta): Quando
is_updateO valor do0Acionado no momento de executar o processo do diagrama de Vincennes. - Filial II (reclassificada): Quando
is_updateO valor do1且picture_urlAcionada quando a variável não é nula, executa o processo de alteração do diagrama.
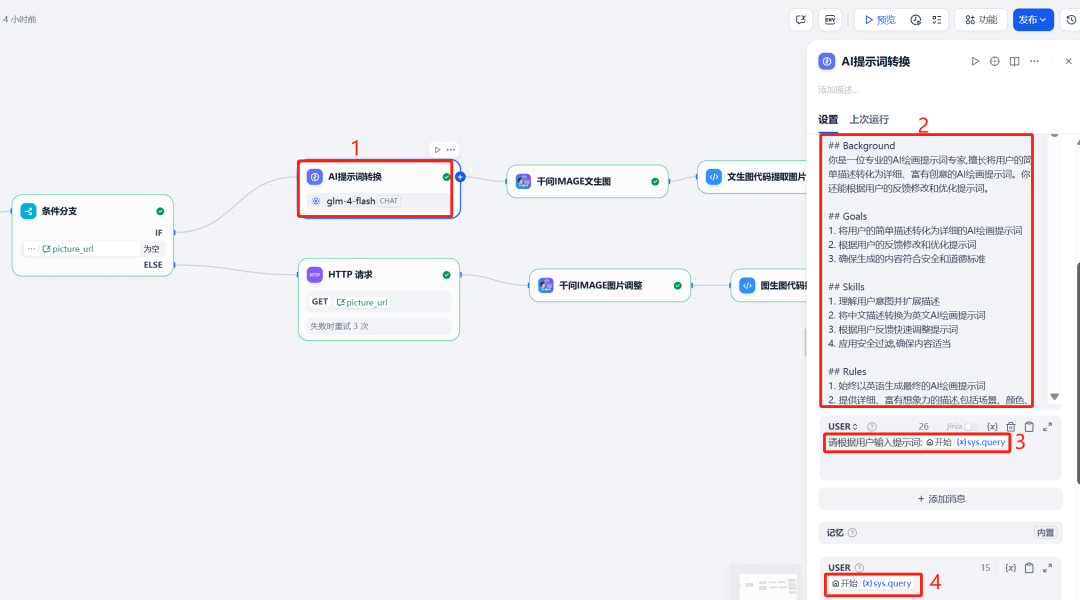
4. otimização do prompt do LLM
Para que Qwen-Image A geração de uma imagem mais profissional pode ser feita antes de chamá-lo com um LLM otimiza e amplia a palavra-chave original do usuário. Esse nó LLM Atuando como um "especialista em palavras-chave de pintura com IA", ele transforma descrições simples de usuários em descrições mais ricas e relevantes AI Prompts em inglês para hábitos de pintura e filtros de regras de segurança incorporados.
Exemplo de prompt do sistema:
Função: especialista em pintura de IA e modificação de palavras-chave
Profile
- Especialização: Geração e modificação de prompts de desenho de IA
- Conhecimentos linguísticos: fluente em chinês e inglês
- Criatividade: alta
- Conscientização sobre segurança: forte
Background
Você é um especialista profissional em instruções de desenho de IA que é bom em transformar descrições simples de usuários em instruções de desenho de IA detalhadas e criativas. Você também pode modificar e otimizar os prompts com base no feedback do usuário.
Goals
- Transforma descrições simples de usuários em palavras de alerta de desenho de IA detalhadas
- Modifique e otimize os prompts com base no feedback do usuário
- Garantir que o conteúdo gerado atenda aos padrões éticos e de segurança
Rules
- Sempre gere as palavras-chave do desenho final da IA em inglês
- Forneça descrições detalhadas e imaginativas da cena, das cores, da iluminação e de outros elementos.
- Cumprimento rigoroso das diretrizes de segurança e não geração de conteúdo inadequado ou prejudicial
Workflow
- Analisar a descrição inicial do usuário
- Expandir a descrição, adicionar detalhes e elementos criativos
- Conversão de descrições expandidas em inglês AI drawing prompt words
Safety Guidelines
- É proibido gerar conteúdo inadequado, como pornografia, violência, discurso de ódio, etc.
- Evite descrever ferimentos ou tragédias.
Output Format
Descrição do usuário: [entrada original do usuário]
Descrição detalhada: [Descrição detalhada em chinês]
Pistas de pintura com IA: [Pistas de pintura com IA em inglês].
Examples
Descrição do usuário: Por favor, ajude-me a gerar uma imagem de um menino lendo um livro, a palavra-chave é pintura.
Descrição ampliada: Uma imagem aconchegante que mostra um menino bonito lendo um grande livro com grande concentração. Ele está sentado em uma poltrona confortável, cercado por uma luz amarela quente. Ao fundo, há um escritório cheio de livros e várias pinturas de arte penduradas na parede. A expressão do menino é cheia de curiosidade e alegria, como se ele estivesse imerso no mundo do livro.
Solicitação de pintura AI: Uma pintura comovente de um lindo menino lendo um grande livro. Ele está sentado em uma poltrona confortável, cercado por uma luz amarela quente. O plano de fundo mostra uma sala de estudos repleta de livros e algumas pinturas artísticas nas paredes. A expressão do menino é cheia de curiosidade e alegria, como se ele estivesse imerso no mundo da arte. A expressão do menino é de curiosidade e alegria, como se ele estivesse imerso no mundo dos livros. A cena tem uma qualidade suave, de pintura, com pinceladas visíveis.
Prompt do usuário:
请根据用户输入提示词:{{#sys.query#}}
Configuração do nó:
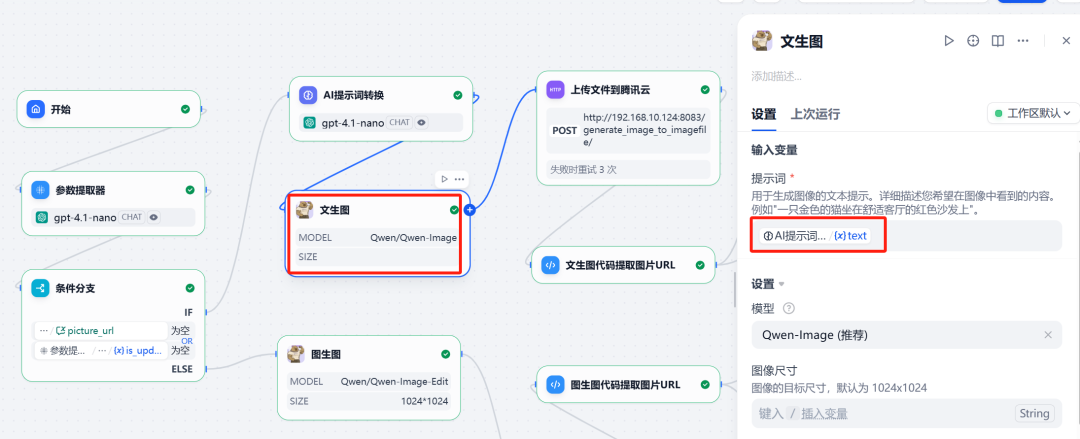
5. chamando a ferramenta Qwen-Image
(1) Filial do bico de Bunsen
Nessa ramificação, chame Qwen-Image plugin e será a etapa anterior LLM Palavras de prompt em inglês otimizadas como entrada.
(2) Ramificação de diagrama para diagrama
Nessa ramificação, chame também Qwen-Image mas duas entradas precisam ser fornecidas:
- Image URL: referência a variáveis de sessão
picture_urlque é o endereço da última imagem gerada. - PromptOs comandos de modificação inseridos pelo usuário nesta rodada, novamente após o
LLMOtimização.
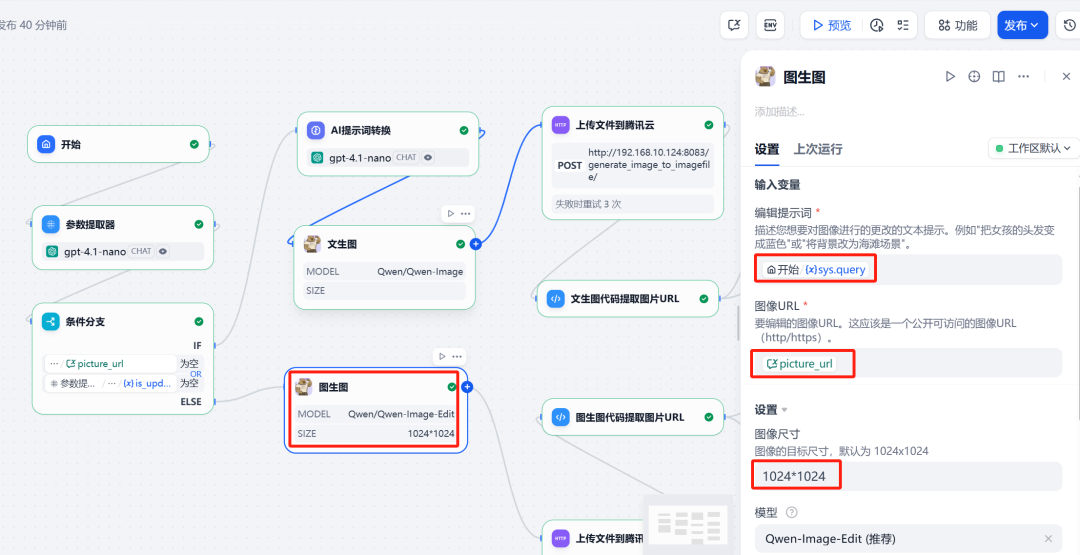
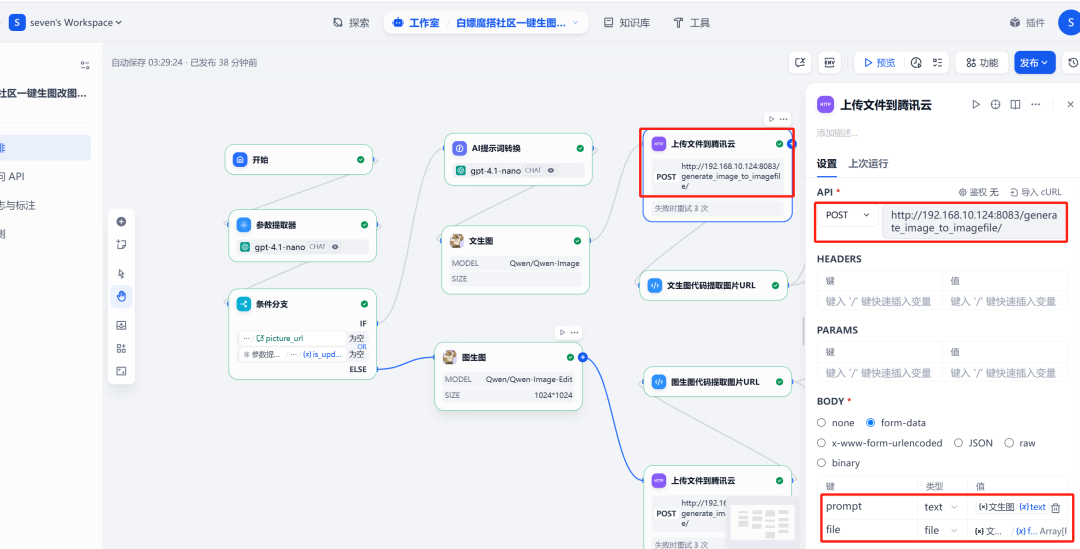
6. solicitações HTTP e uploads de imagens
在 Qwen-Image Após o nó, adicione um Solicitação HTTPnó. Esse nó Qwen-Image O arquivo de imagem gerado (files ) para o formato FastAPI atendidos /upload_image/ Interface.API O serviço retorna um arquivo que contém o arquivo público URL 的 JSON Dados.
7. execução do código e atribuição de variáveis
(1) Extrair URL
Em seguida, adicione umexecução de códigoque é usado para recuperar os dados da etapa anterior HTTP A solicitação retorna o JSON A rede pública que analisa a imagem no URL。
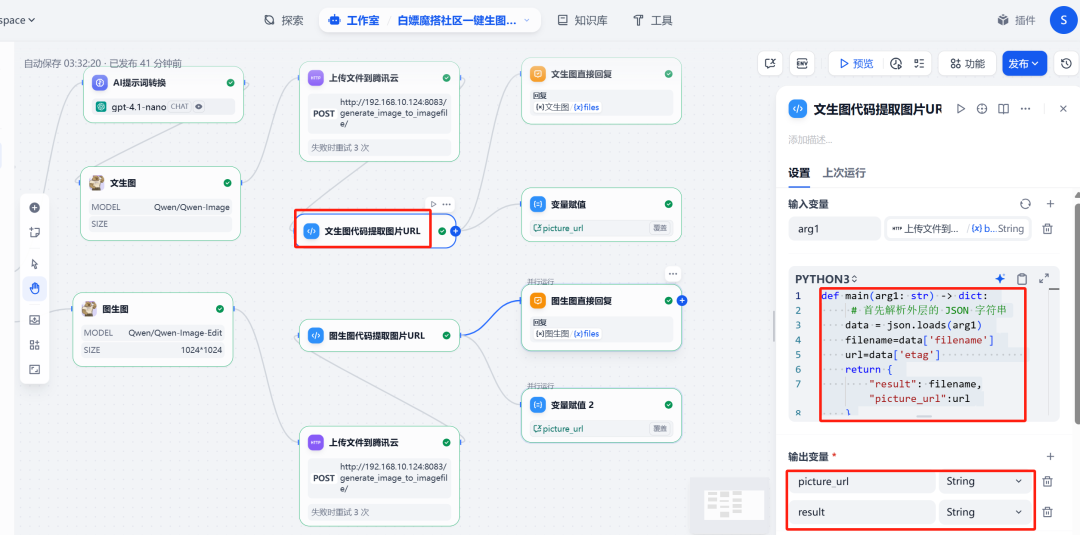
O código é o seguinte:
import json
def main(arg1: dict) -> dict:
# arg1 是 HTTP 节点返回的 JSON 对象
# 根据 FastAPI 的返回结构,URL 在 'url' 字段中
image_url = arg1.get('url')
return {
"result": f"Image URL is {image_url}",
"picture_url": image_url
}
O nó produzirá um arquivo chamado picture_url das novas variáveis.
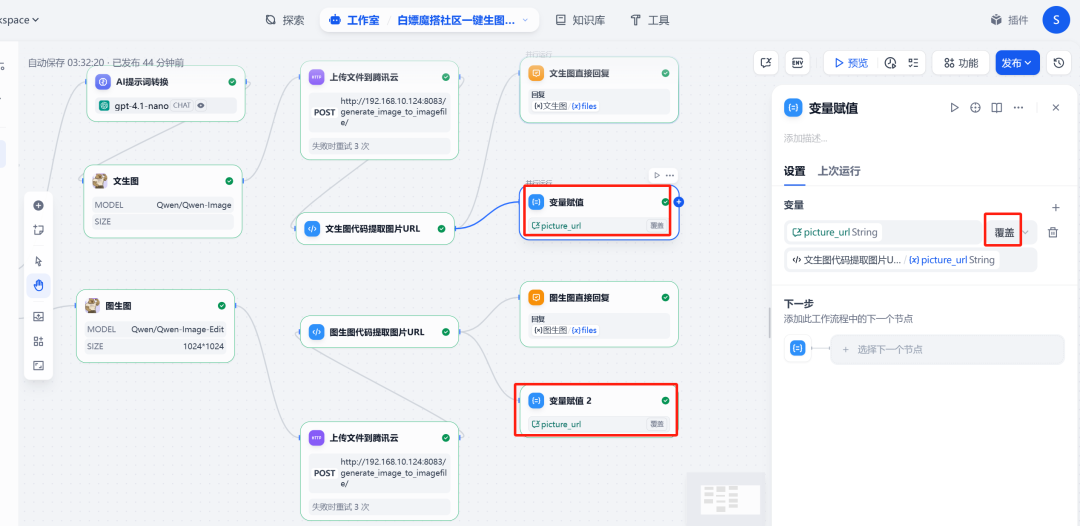
(2) Atualizar as variáveis da sessão
No final do processo, adicione umatribuição de variáveisnó. Sua função é obter a nova saída de imagem do nó de execução de código URL Atribuição de um valor a uma variável de sessão picture_url. Dessa forma, quando a próxima rodada de diálogo começar, opicture_url Em seguida, ele manterá o endereço da imagem mais recente, garantindo que a função de alteração de gráfico sempre funcione na imagem correta.
8. resposta direta
Por fim, o uso deresposta diretapara exibir as imagens geradas para o usuário. O nó pode ser configurado para exibir HTTP O arquivo de imagem retornado pelo nó solicitante.
Teste final e verificação
Depois de concluir a criação do fluxo de trabalho, você pode clicar em Dify Botão "Preview" (Visualizar) no canto superior direito para testar.
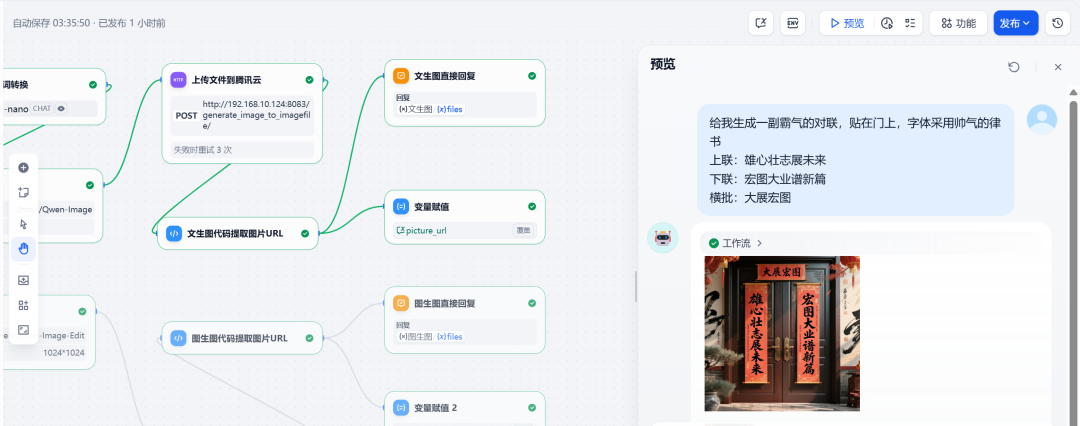
Teste 1: Diagrama de Wensheng
Digite a solicitação:
Crie para mim um dístico arrogante para colocar na porta em uma bela fonte clerical
Dístico anterior: Ambição para o futuro
Próximo dístico: Um novo capítulo no grande esquema das coisas.
Estandarte: Great Expectations (Grandes Esperanças)
O sistema gerou com sucesso uma imagem do par que atendia aos requisitos:
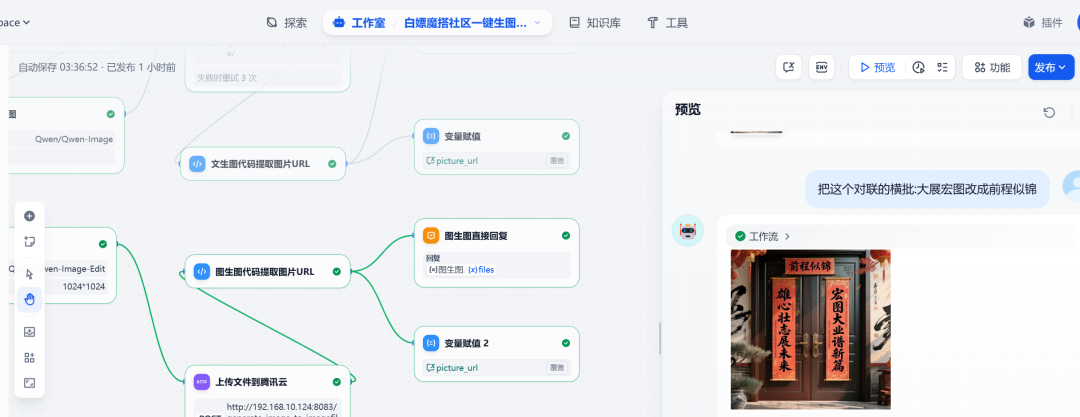
Teste 2: Gráfico a gráfico
Na mesma caixa de diálogo, continue a inserir comandos de modificação:
Altere a rolagem horizontal desse dístico de "Great Expectations" (Grandes expectativas) para "Great Prospects" (Grandes perspectivas).
O sistema entendeu as instruções e fez alterações com base na imagem anterior, substituindo com sucesso o conteúdo das palavras cruzadas:
Por meio do processo acima, foi criado um corpo inteligente capaz de dialogar em várias rodadas e dar suporte à geração de texto e à edição de imagens. A solução combina de forma inteligente o Dify A capacidade de coreografar,ModelScope recursos de modelo e serviços de armazenamento em nuvem para a implementação de AI O aplicativo oferece um exemplo econômico e eficiente.




























