



O DeepSieve é uma estrutura RAG (Retrieval Augmented Generation) de código aberto hospedada no GitHub que se concentra no processamento de consultas complexas e dados de várias fontes. Desenvolvido por MinghoKwok, o DeepSieve oferece suporte ao processamento de dados estruturados (por exemplo, tabelas SQL, registros JSON) e dados não estruturados (por exemplo, Wikipedia), e é adequado para cenários que exigem raciocínio em várias etapas. Ele enfatiza o design modular e os usuários podem ajustar a funcionalidade de acordo com suas necessidades, tornando-o adequado para pesquisadores e desenvolvedores lidarem com tarefas complexas de análise de dados. O projeto foi lançado como uma pré-impressão no arXiv em 29 de julho de 2025, e o corpus completo foi carregado no Arkiv.
Lista de funções
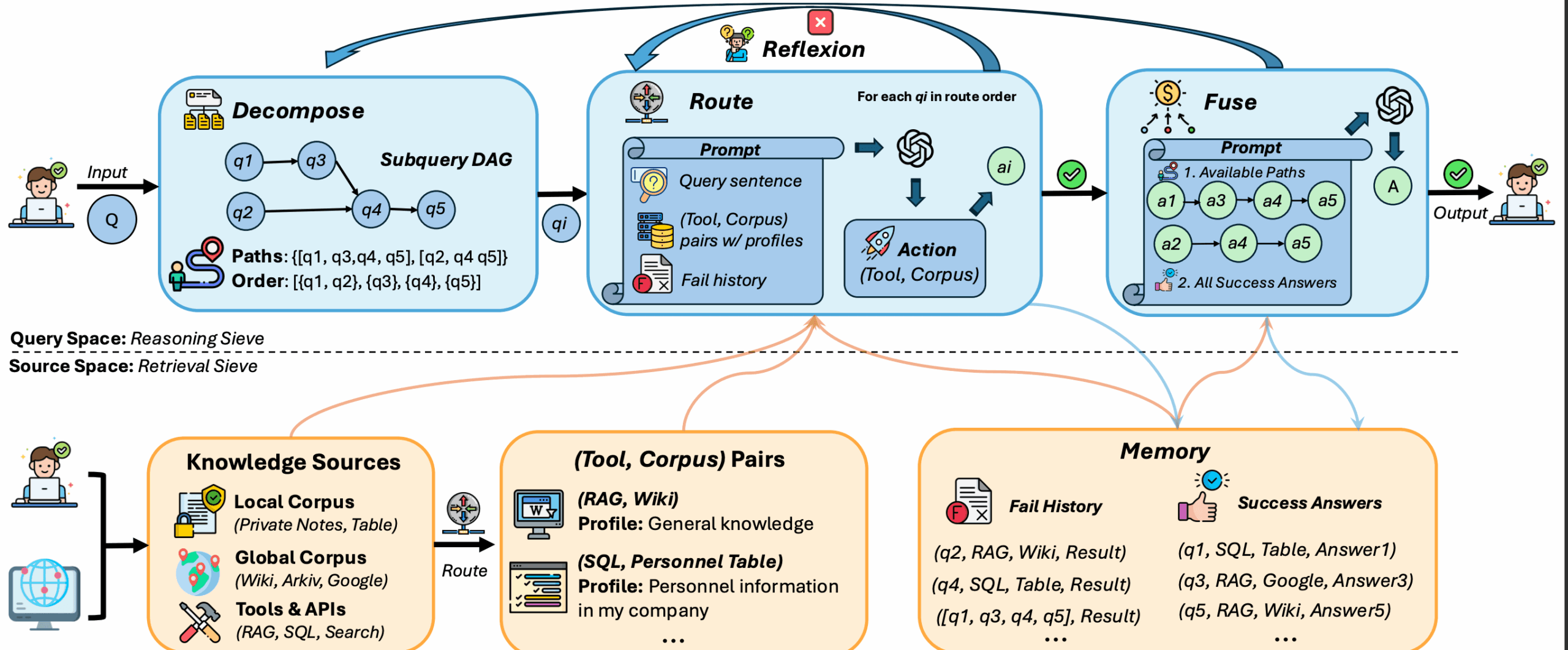
- Decomposição de consultas Dividir uma consulta complexa em vários subproblemas simples para um processamento preciso.
- Roteamento de subquestões Atribuição inteligente de subperguntas a ferramentas ou fontes de dados apropriadas (por exemplo, bancos de dados locais ou bases de conhecimento globais).
- Mecanismos de reflexão Detecta automaticamente as pesquisas com falha e as tenta novamente, suportando até duas reflexões.
- Convergência de respostas Integrar as respostas das subperguntas para gerar a resposta completa final.
- Suporte a várias fontes de dados Manipulação de dados heterogêneos, como tabelas SQL, logs JSON, Wikipedia etc.
- Dois modos RAG Os modos de pesquisa são simples (Naive) e estrutura de gráfico (Graph) para atender a diferentes necessidades.
- Registro detalhado Salvar resultados intermediários, dicas de fusão e métricas de desempenho de cada consulta para facilitar a depuração e a otimização.
- Design modular Os usuários podem ativar ou desativar os módulos de função com chaves de linha de comando para maior flexibilidade.
Usando a Ajuda
Processo de instalação
O DeepSieve é um projeto de código aberto baseado em Python, você precisa clonar o repositório por meio do GitHub e configurar o ambiente. Aqui estão as etapas detalhadas:
- armazém de clones
Execute o seguinte comando em um terminal para clonar o repositório DeepSieve localmente:git clone https://github.com/MinghoKwok/DeepSieve.gitVá para o catálogo de projetos:
cd DeepSieve - Instalação de dependências
O projeto depende do Python 3.7+ e das bibliotecas relacionadas de aprendizado de máquina e processamento de dados. Instale as dependências:pip install -r requirements.txtno caso de
requirements.txtNão fornecido, recomenda-se a instalação manual da biblioteca principal:pip install numpy pandas scikit-learn openaiRecomenda-se o uso de um ambiente virtual para evitar conflitos de dependência:
python -m venv venv source venv/bin/activate # Linux/macOS venv\Scripts\activate # Windows - Configuração de variáveis de ambiente
O DeepSieve usa o Large Language Model (LLM) para processar consultas que exigem a configuração de chaves de API. Por exemplo, usando o DeepSeek Modelos:export OPENAI_API_KEY=your_api_key export OPENAI_MODEL=deepseek-chat export OPENAI_API_BASE=https://api.deepseek.com/v1Dependendo do modo de uso (Naive ou Graph), defina o RAG Tipo:
export RAG_TYPE=naive # 或 graph - Ambiente de verificação
Certifique-se de que todas as dependências estejam instaladas corretamente e que a chave da API seja válida. Se estiver usando uma fonte de dados personalizada, verifique se o caminho do arquivo de dados está configurado corretamente.
Executar o DeepSieve
O DeepSieve é executado a partir da linha de comando e oferece configuração flexível de parâmetros. O uso básico é o seguinte:
Modelo RAG ingênuo
O modo Naive é adequado para tarefas simples. Execute o seguinte comando:
export RAG_TYPE=naive
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
--datasetEspecifique o conjunto de dados (por exemplohotpot_qa)。--sample_sizeAjuste o número de amostras de tratamento.--decomposeAtivar decomposição de consulta: Ativar decomposição de consulta.--use_routingHabilita o roteamento de subquestões.--use_reflectionMecanismos de reflexão: ativação de mecanismos de reflexão.--max_reflexion_timesNúmero máximo de reflexões: Defina o número máximo de reflexões.
Modo Graph RAG
O modo Graph é adequado para consultas complexas e requer suporte à estrutura de gráficos:
export RAG_TYPE=graph
python runner/main_rag_only.py \
--dataset hotpot_qa \
--sample_size 100 \
--decompose \
--use_routing \
--use_reflection \
--max_reflexion_times 2
Desativar módulos
Os usuários podem desativar os recursos removendo os parâmetros da linha de comando. Exemplo:
- Não está usando a decomposição de consultas: remover
--decompose。 - Não está usando rotas: remover
--use_routing。 - Reflexões não utilizadas: remove
--use_reflection。
resultado de saída
Os seguintes arquivos são gerados para cada execução:
- Resultados para cada consulta:
outputs/{rag_type}_{dataset}/query_{i}_results.jsonl - Dica de fusão:
outputs/{rag_type}_{dataset}/query_{i}_fusion_prompt.txt - Indicadores gerais de desempenho:
overall_results.txt和overall_results.json
Funções principais
Decomposição de consultas
O DeepSieve divide consultas complexas em subproblemas. Por exemplo, a consulta "Receita e número de funcionários de uma empresa em 2023" é dividida em:
- Subpergunta 1: Encontre a receita da empresa em 2023.
- Subpergunta 2: Encontre o número de funcionários em uma empresa.
Procedimento operacional:
- Insira uma consulta em um script ou linha de comando.
- Execute o script e o DeepSieve dividirá automaticamente a consulta e exibirá os subproblemas (visíveis no registro).
Roteamento de subquestões
Cada subpergunta é atribuída à ferramenta ou fonte de dados apropriada. Exemplo:
- Dados estruturados(por exemplo, tabelas SQL) encaminhadas para ferramentas de consulta de banco de dados.
- Dados não estruturados (por exemplo, Wikipedia) encaminhados para ferramentas de recuperação de texto.
Não há necessidade de os usuários especificarem manualmente, o DeepSieve faz o roteamento automaticamente. Verificar arquivos de registroquery_{i}_results.jsonlOs detalhes da rota podem ser visualizados.
Mecanismos de reflexão
Se a recuperação de uma subquestão falhar, o DeepSieve tentará automaticamente até duas vezes. O processo de reflexão é registrado no log, e o usuário pode visualizar o motivo da falha e o resultado da nova tentativa.
Convergência de respostas
O DeepSieve consolida as respostas das subperguntas para gerar a resposta final. Por exemplo, as respostas à consulta sobre a empresa acima seriam mescladas em:
- "Em 2023, a empresa terá uma receita de US$ X e Y funcionários."
As dicas de fusão são salvas na pastaquery_{i}_fusion_prompt.txtque é fácil de ser verificado pelo usuário.
Precauções de uso
- Preparação de dados Dados de entrada: certifique-se de que os dados de entrada estejam no formato correto (por exemplo, CSV, JSON) para evitar erros de codificação.
- Chave da API Confirme se a chave da API do LLM é válida e se a conexão de rede é estável.
- Verificação de registros Visualização após a execução
outputs/analisando as métricas de desempenho e os registros de erros. - Suporte à comunidade Se você encontrar problemas, visite a página de problemas do GitHub ou o artigo do arXiv para obter mais informações.
cenário do aplicativo
- pesquisa acadêmica
Os pesquisadores processam dados de várias fontes (por exemplo, Wikipedia e bancos de dados experimentais) para responder rapidamente a perguntas complexas com o DeepSieve. Por exemplo, analisando conjuntos de dados biológicos e associações genéticas na literatura. - Análise de dados comerciais
Os analistas corporativos usam o DeepSieve para processar dados de vendas e registros de clientes para responder a perguntas multidimensionais, como "Quais produtos terão as maiores vendas e alta satisfação do cliente em 2023?" . - Cenários sensíveis à privacidade
O DeepSieve oferece suporte a fontes de dados privadas (por exemplo, bancos de dados internos) para processar consultas sem mesclar dados, o que é adequado para os setores financeiro e de saúde. - desenvolvimento de código aberto
Os desenvolvedores usam o design modular do DeepSieve para ampliar a funcionalidade ou integrar-se a sistemas existentes para processamento de dados personalizado.
QA
- Quais fontes de dados são compatíveis com o DeepSieve?
Suporte para tabelas SQL, registros JSON, Wikipedia etc. O escopo específico do suporte deve consultar a documentação do projeto ou o arquivo de configuração. - Como faço para depurar um erro de tempo de execução?
sondaoutputs/no diretório para ver os detalhes do erro. Verifique se a versão da biblioteca de dependência está correta e se a chave da API é válida. - Qual é a diferença entre o modo Graph e o modo Naive?
O modo Naive é adequado para consultas simples e é rápido; o modo Graph é adequado para raciocínio complexo em várias etapas com maior precisão, mas com custo computacional mais alto. - Como faço para contribuir com o código?
Faça um fork do repositório, altere o código e envie uma Pull Request.CONTRIBUTING.mdDocumentação que segue a especificação do código.


























