



O DeepSeek-OCR é uma ferramenta de reconhecimento óptico de caracteres (OCR) desenvolvida e de código aberto pelo DeepSeek-AI. Ela propõe uma nova abordagem chamada "Compressão Óptica Contextual", que repensa a função do codificador visual a partir da perspectiva do Modelo de Linguagem Grande (LLM). Em vez de simplesmente reconhecer o texto em uma imagem, a ferramenta renderiza um conteúdo textual longo, como uma página de documento, em uma imagem, que é então compactada em um conjunto menor de "tokens de visão". Em seguida, o decodificador do modelo de linguagem reconstrói o texto original a partir desses tokens de visão. Essa abordagem pode reduzir o número de tokens de entrada de 7 a 20 vezes, de modo que modelos grandes podem usar menos recursos computacionais para lidar com documentos muito longos, melhorando a eficiência e a velocidade do processamento. O projeto segue a licença de código aberto do MIT.
Lista de funções
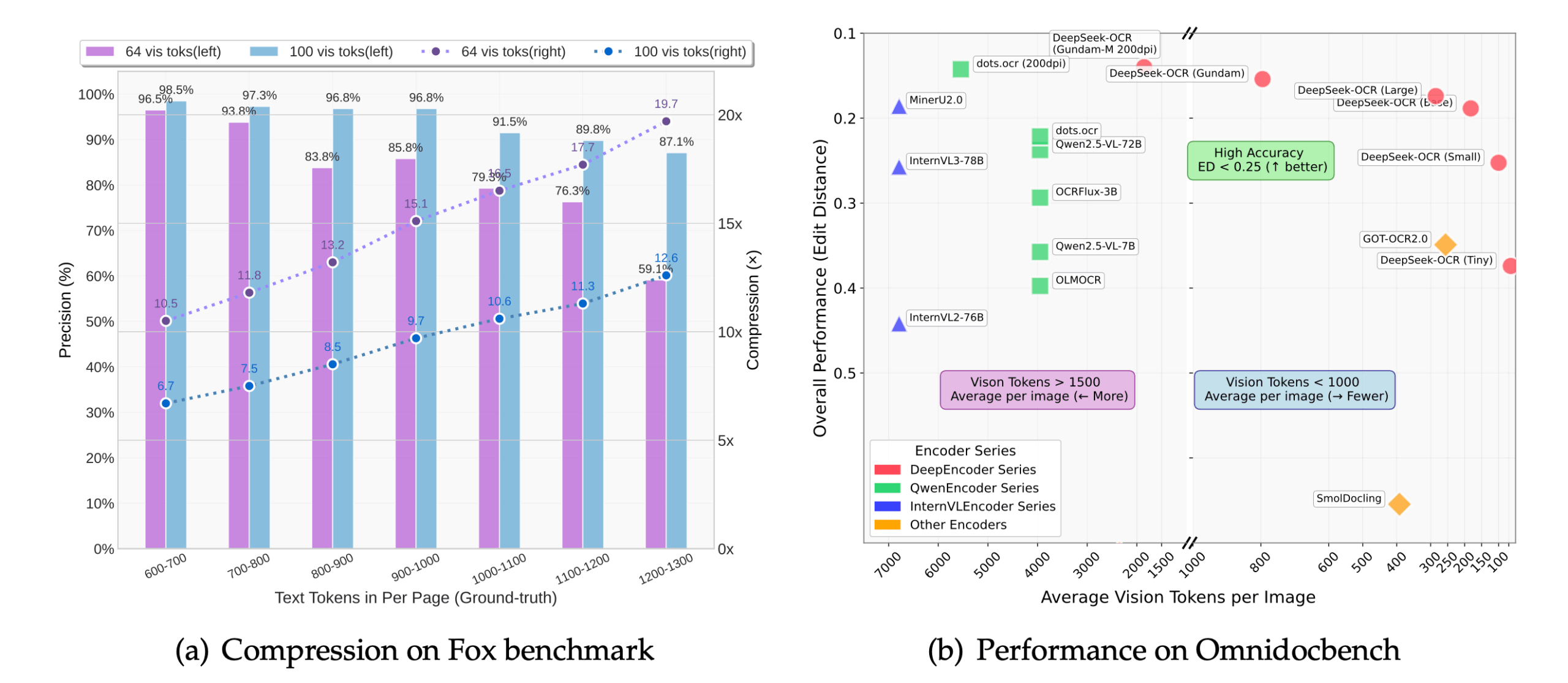
- Compressão óptica contextualRedução drástica da quantidade de dados processados pelo modelo por meio da compactação de imagens em tokens visuais, reduzindo o uso da memória e melhorando a velocidade de inferência.
- Reconhecimento altamente precisoO sistema de reconhecimento de texto é um dos mais avançados do mundo: com uma compactação de 10x, ele ainda pode atingir uma precisão de reconhecimento de cerca de 97%, o que preserva o layout, a tipografia e a relação espacial do documento.
- Saída estruturadaMarkdown: capacidade de converter documentos, especialmente páginas com layouts complexos (por exemplo, tabelas, listas, cabeçalhos), diretamente no formato Markdown, preservando a estrutura do texto original.
- Suporte a várias tarefasModificação da palavra de prompt de entrada (Prompt): Ao modificar a palavra de prompt de entrada (Prompt), o modelo pode executar diferentes tarefas, por exemplo:
- Converta o documento inteiro em Markdown.
- Reconhecimento genérico de imagens por OCR.
- Analisa os gráficos no documento.
- Descreva detalhadamente o conteúdo da imagem.
- Vários modos de resoluçãoResolução fixa: Suporta uma ampla gama de resoluções fixas de 512 x 512 a 1280 x 1280, bem como um modo de resolução dinâmica para processar documentos de resolução ultra-alta.
- Raciocínio de alto desempenhoIntegrado com a estrutura vLLM e Transformers, ele pode atingir uma velocidade de cerca de 2.500 tokens/segundo ao processar arquivos PDF em GPUs A100-40G.
- reconhecimento de escrita manualReconhece o conteúdo manuscrito melhor do que muitas ferramentas tradicionais de OCR com boa iluminação e resolução.
Usando a Ajuda
A instalação e o uso do DeepSeek-OCR são voltados principalmente para desenvolvedores e exigem uma certa base de programação. A seguir, o procedimento detalhado de operação, que é dividido principalmente em três partes: configuração do ambiente, instalação e raciocínio de código.
Etapa 1: Preparação ambiental
Os ambientes oficiais recomendados são CUDA 11.8 e PyTorch 2.6.0. Antes de começar, você precisa instalar o Git e o Conda.
- Clonagem do depósito do projeto
Primeiro, clone a base de código oficial do DeepSeek-OCR do GitHub em seu computador local. Abra um terminal (ferramenta de linha de comando) e digite o seguinte comando:git clone https://github.com/deepseek-ai/DeepSeek-OCR.gitQuando executado, ele cria um arquivo no diretório atual chamado
DeepSeek-OCRda pasta. - Criar e ativar o ambiente Conda
Para evitar conflitos de dependência com outros projetos Python em seu computador, é recomendável criar um ambiente virtual Conda separado.# 创建一个名为deepseek-ocr的Python 3.12.9环境 conda create -n deepseek-ocr python=3.12.9 -y # 激活这个新创建的环境 conda activate deepseek-ocrApós a ativação bem-sucedida, o prompt do terminal será precedido por
(deepseek-ocr)Palavras.
Etapa 2: Instalar dependências
Em um ambiente Conda ativado, as bibliotecas Python necessárias para a execução do modelo precisam ser instaladas.
- Instalando o PyTorch
Instale a versão do PyTorch adaptada ao CUDA 11.8 de acordo com os requisitos oficiais.pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118 - Instalar outras dependências principais
O projeto conta com a biblioteca vLLM para inferência de alto desempenho e também requer a instalação da bibliotecarequirements.txtOutros pacotes listados no arquivo.# 进入项目文件夹 cd DeepSeek-OCR # 安装vLLM(注意:官方提供了编译好的whl文件链接,也可以自行编译) # 示例是下载官方提供的whl文件进行安装 pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl # 安装requirements.txt中的所有依赖 pip install -r requirements.txt - Instalar o Flash Attention (opcional, mas recomendado)
Para obter a velocidade ideal, é recomendável instalar a biblioteca Flash Attention.pip install flash-attn==2.7.3 --no-build-isolationAtenção: Você também pode deixar essa biblioteca desinstalada se sua GPU não for compatível ou se a instalação falhar. Posteriormente, no código, você precisará remover a biblioteca
_attn_implementation='flash_attention_2'Com esse parâmetro, o modelo será executado, mas será mais lento.
Etapa 3: Executar o código de inferência
O DeepSeek-OCR oferece duas abordagens principais de inferência: com base noTransformersA inferência única da biblioteca e uma biblioteca baseada emvLLMde inferência em lote de alto desempenho.
Abordagem 1: inferência rápida usando transformadores (adequada para testes de imagem única)
Essa abordagem é simples de codificar e ideal para testar rapidamente os efeitos do modelo.
- Crie um arquivo Python, por exemplo
test_ocr.py。 - Copie o código a seguir em um arquivo. Esse código carregará o modelo e executará o reconhecimento de OCR em uma imagem especificada.
import torch from transformers import AutoModel, AutoTokenizer import os # 指定使用的GPU,'0'代表第一张卡 os.environ["CUDA_VISIBLE_DEVICES"] = '0' # 模型名称 model_name = 'deepseek-ai/DeepSeek-OCR' # 加载分词器和模型 tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True) # 加载模型,使用flash_attention_2加速,并设置为半精度(bfloat16)以节省显存 model = AutoModel.from_pretrained( model_name, trust_remote_code=True, _attn_implementation='flash_attention_2', use_safetensors=True ).eval().cuda().to(torch.bfloat16) # 定义输入的图片路径和输出路径 image_file = 'your_image.jpg' # <-- 将这里替换成你的图片路径 output_path = 'your/output/dir' # <-- 将这里替换成你的输出文件夹路径 # 定义提示词,引导模型执行特定任务 # 这个提示词告诉模型将文档转换为Markdown格式 prompt = "<image>\n<|grounding|>Convert the document to markdown. " # 执行推理 res = model.infer( tokenizer, prompt=prompt, image_file=image_file, output_path=output_path, base_size=1024, image_size=640, crop_mode=True, save_results=True, test_compress=True ) print(res) - código de execução
Posicione uma imagem a ser reconhecida (por exemployour_image.jpg) no mesmo diretório que o script e, em seguida, execute-o:python test_ocr.pyNo final da execução do programa, o texto reconhecido será impresso no terminal, enquanto o resultado será salvo no caminho de saída que você especificar.
Segunda maneira: usar o vLLM para raciocínio em lote (adequado para processar um grande número de imagens ou PDF)
O modo vLLM é mais eficiente e adequado para ambientes de produção.
- Modificação do arquivo de configuração
entrar emDeepSeek-OCR-master/DeepSeek-OCR-vllmabra o diretórioconfig.pyaltere o caminho de entrada nele (INPUT_PATH) e o caminho de saída (OUTPUT_PATH) e outras configurações. - script executável
Scripts para diferentes tarefas são fornecidos nesse diretório:- Manipula dados de imagens em fluxo contínuo:
python run_dpsk_ocr_image.py - Processar arquivos PDF:
python run_dpsk_ocr_pdf.py - Executar testes de benchmark:
python run_dpsk_ocr_eval_batch.py
- Manipula dados de imagens em fluxo contínuo:
cenário do aplicativo
- Digitalização de documentos
Depois de digitalizar livros em papel, contratos, relatórios etc. em imagens, use o DeepSeek-OCR para convertê-los rapidamente em texto eletrônico editável e pesquisável, com excelente retenção das legendas, listas e estruturas de tabelas originais. - Extração de informações
Extraia automaticamente informações importantes, como valor, data, nome do projeto, etc., de imagens de faturas, recibos, formulários, etc., permitindo a entrada automatizada de dados e reduzindo as operações manuais. - Educação e pesquisa
Os pesquisadores podem usar essa ferramenta para identificar e converter rapidamente o conteúdo textual em documentos, livros antigos, arquivos e outros materiais documentais para posterior análise de dados e recuperação de conteúdo. - Aplicativos de acessibilidade
Ao reconhecer o texto em imagens e gerar descrições detalhadas, ele pode ajudar usuários com deficiência visual a entender o conteúdo das imagens, por exemplo, para ler menus, placas de trânsito ou instruções de produtos.
QA
- O DeepSeek-OCR é gratuito?
Sim, o DeepSeek-OCR é um projeto de código aberto que segue a licença MIT e é gratuito para os usuários usarem, modificarem e distribuírem. - Quais idiomas são compatíveis?
O modelo demonstra principalmente seu poder no processamento de documentos em inglês e chinês. Como ele se baseia em um modelo de idioma grande, teoricamente tem potencial para processamento em vários idiomas, mas o efeito exato precisa ser avaliado com base em testes reais. - Qual é o princípio do processamento de arquivos PDF?
O próprio DeepSeek-OCR lida com imagens. Quando um arquivo PDF é inserido, o programa primeiro renderiza (converte) cada página do PDF em uma imagem, depois faz o OCR dessas imagens página por página e, por fim, mescla os resultados de todas as páginas em uma única saída. - Posso usá-lo sem uma GPU NVIDIA?
A documentação oficial e os tutoriais são baseados em ambientes NVIDIA GPU e CUDA. Embora o modelo possa, teoricamente, ser executado em uma CPU, ele será muito lento e não será adequado para aplicações práticas. Portanto, é altamente recomendável usá-lo em um dispositivo equipado com uma GPU NVIDIA. - Quais são os benefícios da "compressão óptica contextual"?
O principal benefício é a eficiência. Quando os modelos tradicionais processam textos longos, o espaço computacional e de memória aumenta drasticamente com o tamanho do texto. Ao compactar imagens de texto em um pequeno número de tokens visuais, o DeepSeek-OCR pode processar o mesmo conteúdo, ou até mais longo, com menos recursos, possibilitando o processamento de documentos de grande escala em hardware limitado.































