



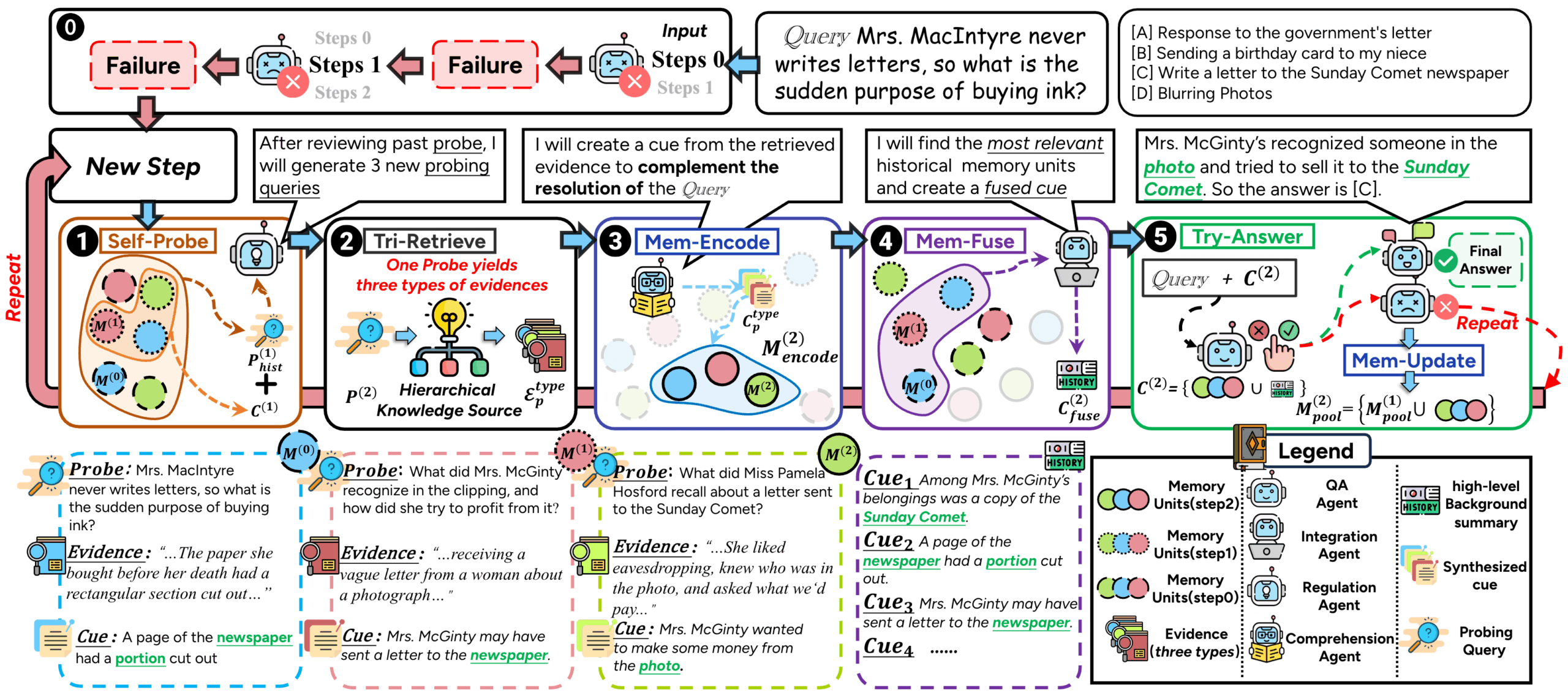
O ComoRAG é um sistema RAG (Retrieval Augmented Generation) projetado para lidar com documentos longos e compreensão de narrativas com vários documentos. Os métodos tradicionais de RAG geralmente enfrentam dificuldades ao lidar com histórias longas ou romances, devido aos enredos complexos e à evolução das relações entre os personagens. Isso se deve ao fato de que a maioria deles usa uma abordagem de recuperação única e sem estado, o que dificulta a captura de associações contextuais de longa distância. O ComoRAG é inspirado no processo cognitivo humano, que acredita que o raciocínio narrativo não é um processo único, mas um processo dinâmico e em evolução que exige a integração de evidências recém-adquiridas com o conhecimento existente. Ao encontrar dificuldades de raciocínio, o ComoRAG inicia um ciclo de raciocínio iterativo. Ele gera perguntas de sondagem para explorar novas pistas e integra as informações recém-recuperadas em um pool de memória global, criando gradualmente um contexto coerente para a pergunta inicial. Esse ciclo de "raciocínio→probing→retrieving→integrating→solving" o torna particularmente bom para lidar com problemas complexos que exigem compreensão global.
Lista de funções
- estrutura de memória cognitivaO sistema de raciocínio é uma ferramenta de raciocínio dinâmica e com estado: imitando a maneira como o cérebro humano processa as informações, ele processa problemas complexos por meio de loops de raciocínio iterativos para obter um processo de raciocínio dinâmico e com estado.
- Suporte a vários modelosIntegração e suporte para uma ampla variedade de modelos de linguagem grande (LLMs) e modelos incorporados, permitindo que os usuários se conectem à API OpenAI ou implementem servidores vLLM locais e modelos incorporados.
- Pesquisa aprimorada do GraphUso de estruturas gráficas para recuperação e raciocínio para melhor capturar e entender relacionamentos complexos entre entidades.
- Processamento flexível de dadosFornecer ferramentas de fragmentação de documentos, suporte por token, palavra, frase e outras formas de segmentação.
- Design modularO sistema foi projetado para ser modular e extensível, facilitando o desenvolvimento secundário e a expansão funcional.
- Avaliação automatizadaO Q&A é fornecido com scripts de avaliação que suportam vários indicadores, como F1, EM (correspondência exata) etc., facilitando a avaliação quantitativa da eficácia do Q&A.
Usando a Ajuda
O ComoRAG é uma poderosa estrutura generativa aprimorada por recuperação que se concentra na compreensão e no raciocínio para o processamento de textos narrativos longos. Ele melhora significativamente o desempenho do modelo em tarefas como questionamento de textos longos e extração de informações por meio de um loop iterativo cognitivo exclusivo.
Configuração e instalação do ambiente
Antes de começar a usá-lo, você precisa configurar o ambiente de tempo de execução.
- Versão PythonUso recomendado
Python 3.10ou superior. - Instalação de dependênciasApós clonar o código do projeto, instale todos os pacotes de dependência necessários no diretório raiz do projeto com o seguinte comando. O ambiente de GPU é recomendado para melhorar o desempenho.
pip install -r requirements.txt - variável de ambienteSe você planeja usar a API do OpenAI, é necessário definir as variáveis de ambiente apropriadas
OPENAI_API_KEY. Se estiver usando um modelo local, será necessário configurar o caminho para o modelo.
Preparação de dados
O ComoRAG requer arquivos de dados em um formato específico para ser executado. Você precisará preparar arquivos de corpus e arquivos de perguntas e respostas.
- Arquivo de corpus (corpus.jsonl)Arquivo de documentos: Esse arquivo contém todos os documentos que precisam ser recuperados. O arquivo é
jsonlcada linha é um objeto JSON que representa um documento.idIdentificador exclusivo do documento: um identificador exclusivo do documento.doc_idIdentificador do grupo ou livro ao qual o documento pertence: Um identificador do grupo ou livro ao qual o documento pertence.titleTítulo do documento.contentsConteúdo original do documento: O conteúdo original do documento.
Exemplo:
{"id": 0, "doc_id": 1, "title": "第一章", "contents": "很久很久以前..."} - Arquivo de perguntas e respostas (qas.jsonl)Arquivo de perguntas: Esse arquivo contém as perguntas que precisam ser respondidas pelo modelo. Novamente, cada linha é um objeto JSON.
idIdentificador exclusivo do problema: Um identificador exclusivo do problema.question:: Perguntas específicas.golden_answers:: Lista de respostas padrão para perguntas.
Exemplo:
{"id": "1", "question": "故事的主角是谁?", "golden_answers": ["灰姑娘"]}
Agrupamento de documentos
Como os documentos longos não podem ser processados diretamente pelo modelo, eles precisam ser cortados em partes menores primeiro. O projeto fornece o chunk_doc_corpus.py script para fazer isso.
Você pode dividir o corpus usando o seguinte comando:
python script/chunk_doc_corpus.py \
--input_path dataset/cinderella/corpus.jsonl \
--output_path dataset/cinderella/corpus_chunked.jsonl \
--chunk_by token \
--chunk_size 512 \
--tokenizer_name_or_path /path/to/your/tokenizer
--input_pathCaminho para o arquivo do corpus original.--output_pathCaminho do arquivo: o caminho onde o arquivo será salvo após a fragmentação.--chunk_by:: Base de fragmentação, que pode sertoken、word或sentence。--chunk_sizeTamanho de cada bloco: O tamanho de cada bloco.--tokenizer_name_or_pathToken: Especifica o caminho para o participante usado para computar o token.
Dois modos de operação
O ComoRAG oferece duas formas principais de execução: usando a API OpenAI ou usando um servidor vLLM implantado localmente.
Modo 1: usando a API da OpenAI
Essa é a maneira mais fácil e rápida de começar.
- Modificar a configuração: Aberto
main_openai.pyencontre o arquivoBaseConfigParcialmente modificado.config = BaseConfig( llm_base_url='https://api.openai.com/v1', # 通常无需修改 llm_name='gpt-4o-mini', # 指定使用的OpenAI模型 dataset='cinderella', # 数据集名称 embedding_model_name='/path/to/your/embedding/model', # 指定嵌入模型的路径 embedding_batch_size=32, need_cluster=True, # 启用语义/情景增强 output_dir='result/cinderella', # 结果输出目录 ... ) - programa de corrida: Quando a configuração estiver concluída, execute o script diretamente.
python main_openai.py
Modo 2: usando um servidor vLLM local
Você pode escolher esse modo se tiver recursos computacionais suficientes (por exemplo, GPUs) e quiser executar o modelo localmente para garantir a privacidade dos dados e reduzir os custos.
- Iniciando o servidor vLLM: Primeiro, você precisa iniciar um servidor vLLM que seja compatível com a API OpenAI.
python -m vllm.entrypoints.openai.api_server \ --model /path/to/your/model \ --served-model-name your-model-name \ --tensor-parallel-size 1 \ --max-model-len 32768--modelCaminho para seu modelo local de idioma grande.--served-model-nameAtribua um nome ao seu serviço modelo.--tensor-parallel-sizeNúmero de GPUs usadas.
- Verificação do status do servidor: Você pode usar
curl http://localhost:8000/v1/modelspara verificar se o servidor foi iniciado com êxito. - Modificar a configuração: Aberto
main_vllm.pymodifique a configuração nele contida.# vLLM服务器配置 vllm_base_url = 'http://localhost:8000/v1' served_model_name = '/path/to/your/model' # 与vLLM启动时指定的模型路径一致 config = BaseConfig( llm_base_url=vllm_base_url, llm_name=served_model_name, llm_api_key="EMPTY", # 本地服务器不需要真实的API Key dataset='cinderella', embedding_model_name='/path/to/your/embedding/model', # 本地嵌入模型路径 ... ) - programa de corridaQuando a configuração estiver concluída, execute o script.
python main_vllm.py
Resultados da avaliação
Quando o programa termina de ser executado, os resultados gerados são salvos na pasta result/ diretório. Você pode usar o diretório eval_qa.py scripts para avaliar automaticamente o desempenho do modelo.
python script/eval_qa.py /path/to/result/<dataset>/<subset>
O script calcula métricas como EM (Exact Match Rate) e F1 Score e gera o results.json etc.
cenário do aplicativo
- Análises de histórias longas/roteiros
Para escritores, roteiristas ou pesquisadores literários, o ComoRAG pode servir como uma poderosa ferramenta analítica. Os usuários podem importar um romance ou roteiro inteiro e, em seguida, fazer perguntas complexas sobre o desenvolvimento do enredo, a evolução das relações entre os personagens ou temas específicos, e o sistema é capaz de fornecer insights integrando informações de todo o texto. - Perguntas e respostas da Base de Conhecimento Empresarial
O ComoRAG lida com esses documentos longos, complexos e interconectados e cria um sistema inteligente de perguntas e respostas. Os funcionários podem fazer perguntas diretamente em linguagem natural, como "Quais são as principais diferenças e riscos entre a implementação técnica da opção A e da opção B no projeto Q3?". O sistema é capaz de integrar vários relatórios para fornecer respostas precisas. - Estudo de instrumentos jurídicos e arquivos de casos
Os advogados e a equipe jurídica precisam ler um grande número de documentos jurídicos extensos e arquivos históricos. O ComoRAG os ajuda a classificar rapidamente a linha do tempo do caso, analisar a correlação entre diferentes evidências e responder a perguntas complexas que exigem a síntese de vários documentos para chegar a uma conclusão, o que melhora muito a eficiência da análise do caso. - Pesquisa científica e revisão da literatura
Os pesquisadores precisam ler e entender um grande número de artigos acadêmicos ao realizar uma revisão da literatura. O ComoRAG pode ajudar os pesquisadores a fazer perguntas sobre vários artigos em um campo, extrair informações importantes e construir um gráfico de conhecimento para ajudá-los a compreender rapidamente a dinâmica global e os principais desafios de seu campo de pesquisa.
QA
- Quais são as principais diferenças entre o ComoRAG e os métodos tradicionais de RAG?
A principal diferença é que o ComoRAG introduz um processo dinâmico de raciocínio iterativo inspirado na ciência cognitiva. Enquanto os RAGs tradicionais geralmente são pesquisas únicas e sem estado, o ComoRAG gera ativamente novas perguntas exploratórias quando encontra perguntas difíceis de responder e realiza várias rodadas de pesquisas e consolidação de informações para formar um "pool de memória" em constante expansão para auxiliar no raciocínio final. - Quais são os requisitos para usar um servidor vLLM local?
O uso de um servidor local vLLM geralmente requer uma GPU NVIDIA de bom desempenho e memória de vídeo suficiente, dependendo do tamanho do modelo que você está carregando. Além disso, o kit de ferramentas CUDA precisa ser instalado. Essa abordagem, embora complicada de configurar inicialmente, oferece maior segurança de dados e inferência mais rápida. - Posso substituir meu próprio modelo incorporado?
Sim. A arquitetura do ComoRAG é modular, e você pode convenientementeembedding_modelCatalogue para adicionar suporte a novos modelos incorporados. Apenas certifique-se de que seu modelo possa converter texto em vetores e adaptar as interfaces de carregamento e chamada de dados do sistema. - Essa estrutura oferece suporte ao tratamento de dados multimodais, como imagens ou áudio/vídeo?
A partir da descrição básica do projeto, o ComoRAG está atualmente concentrado no processamento de narrativas textuais longas, como documentos longos e perguntas e respostas de vários documentos. Embora seu design modular ofereça a possibilidade de ampliar os recursos multimodais no futuro, a funcionalidade principal da versão atual foi criada com base em dados textuais.
































