

O roteiro mais distópico do setor de tecnologia está sendo executado. Um gigante da segurança de dezenas de bilhões de dólares, que começou bloqueando bots automatizados, assumiu a responsabilidade de criar a ferramenta de rastreamento automatizado mais simples e talvez até mais poderosa do mundo atualmente.
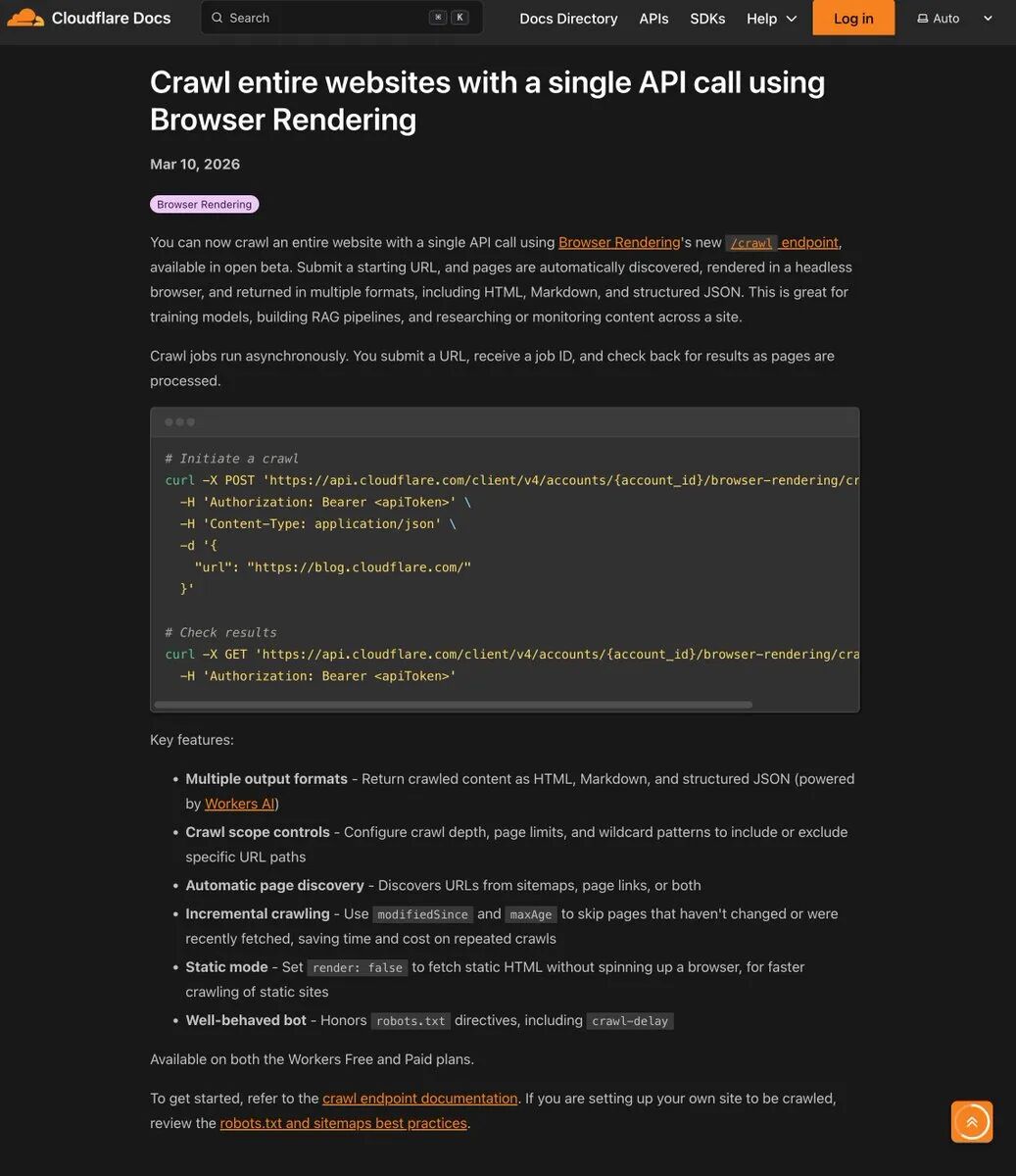
Em março de 2026, a Cloudflare lançou um novo recurso Beta para renderização de navegador:/crawl API.
Não há nenhuma estrutura complexa para configurar, nenhum CAPTCHA para lidar, nenhum cluster de navegador sem cabeça Puppeteer ou Playwright para manter em um servidor com vazamentos de memória. Tudo o que você precisa fazer é enviar uma solicitação HTTP POST com um URL inicial, e o restante da descoberta de páginas, renderização de JavaScript e paginação é feito pela rede de borda global da empresa. No final do dia, ele lhe enviará honestamente um HTML, Markdown ou JSON estruturado limpo.

Ironicamente, inúmeros desenvolvedores têm pago pelos serviços da Cloudflare para se defenderem dos rastreadores nos últimos anos. Agora, essas mesmas pessoas estão consultando a documentação e aprendendo a usar a API da Cloudflare para rastrear os sites de outras pessoas.
Hidden Ambitions: um império de renderização com 9 pontos finais
Enquanto todos os olhos estavam fixos no /crawl Quando se trata do choque, muitas pessoas ignoram a infraestrutura por trás dele./crawl Não é um brinquedo de hacker isolado, é a peça final do quebra-cabeça em toda a matriz da API REST do Cloudflare Browser Rendering.
Observe atentamente a lista completa de endpoints atuais e você verá que eles realmente desmantelaram completamente o que o navegador pode fazer:
| ponto de partida ou ponto de chegada (em histórias etc.) | Descrição funcional |
|---|---|
/content |
Obter uma página única de HTML totalmente renderizada |
/screenshot |
Captura de tela visual da página da Web |
/pdf |
Página para PDF |
/markdown |
Extração de markdown para IA |
/snapshot |
Contém um instantâneo híbrido de conteúdo e recursos visuais |
/scrape |
Rastreamento estruturado baseado em nós DOM |
/json |
Saída direta de dados estruturados extraídos em combinação com o Workers AI |
/links |
Topo Crawl Essential Extração de links de página inteira |
/crawl |
Rastreamento automatizado de todo o site (nova adição) |
No passado, você tinha que usar o antigo Scrapy para criar páginas estáticas ou criar um conjunto pesado de serviços Node.js para executar navegadores reais. Agora, a Cloudflare transforma esse processo em duas etapas minimalistas:
- iniciar uma tarefaEnvie o URL inicial para
/crawlA ID do trabalho de uma execução assíncrona está imediatamente disponível. - pesquisa de opiniãoID do trabalho: pegue o ID do trabalho e verifique o progresso. Os trabalhos podem ser executados em seu centro de dados por até 7 dias e os resultados são mantidos por 14 dias.
Os parâmetros incorporados ao sistema proporcionam um grau de controle extremamente alto. Você pode usar o limit Para definir um limite máximo de rastreamento de 100.000 páginas, use a opção depth Limite a profundidade do link ou use a opção includePatterns etc., os curingas só capturam conteúdo em um caminho específico. Ainda mais mortal é a função render Parâmetros. Se você só precisa rastrear estações de documentos puramente estáticos, coloque o parâmetro render configurado como falseele ignorará a renderização do navegador e a captura simultânea direta de alta velocidade; se for um aplicativo de página única (SPA), ative a função render Você pode extrair o conteúdo depois de executar o JavaScript.
Golpes de queda com limiar zero
Esse golpe descendente no nível da infraestrutura exerce imediatamente uma atração gravitacional sobre o ecossistema de negócios existente.
Os desenvolvedores de aplicativos RAG (Retrieval Augmented Generation) são a primeira onda de beneficiários. Os modelos grandes precisam de texto limpo, e as tags HTML são um ruído para eles. Onde os desenvolvedores costumavam ter que escrever todos os tipos de extratores regulares e scripts de limpeza, agora eles recebem Markdown de volta em uma única solicitação. Engenheiros de dados de IA, desenvolvedores independentes e até mesmo pequenas equipes de startups não precisam mais contratar uma pessoa dedicada para manter um pipeline de rastreamento.
Mas para as empresas que se especializam em SaaS de rastreadores, isso é como tirar o calor do fogo. Veja o Firecrawl, por exemplo, cujo modelo de negócios principal é encapsular rastreadores em APIs utilizáveis, e agora estamos colocando isso na mesa com a Cloudflare:
| dimensão (matemática) | Cloudflare /crawl | Firecrawl |
|---|---|---|
| orientação primordial | APIs em nível de infraestrutura | SaaS para cenários verticais |
| modelo de faturamento | Faturamento baseado em navegador | Faturamento por número de páginas rastreadas |
| rede de nós | Grande pool global de nós de borda | Exportações de servidores relativamente restritas |
| usabilidade | Requer uma conta Cloudflare com o Workers. | Registro e uso infalíveis |
| Extração estruturada | IA de trabalhadores de integração nativa /json ponto de partida ou ponto de chegada (em histórias etc.) |
Extração de modelos grandes incorporada para uma melhor experiência imediata |
O Firecrawl ainda lidera em termos de embalagem do produto e facilidade de uso para usuários sem formação técnica. Mas a Cloudflare tem um fosso intransponível: custo de computação e tamanho do nó.
Durante o teste beta, desde que você não ative a renderização de JavaScript (render: false), a interface é totalmente gratuita. Mesmo com a renderização ativada, a versão gratuita oferece 10 minutos de tempo de navegação por dia; a versão paga (que começa em apenas US$ 5 por mês) oferece 10 horas por mês e cobra apenas US$ 0,09 por hora para cada hora além disso. O faturamento por hora inverte completamente a lógica tradicional do faturamento por solicitação e, para necessidades pesadas de rastreamento, o custo é quase insignificante.
escudo e lança
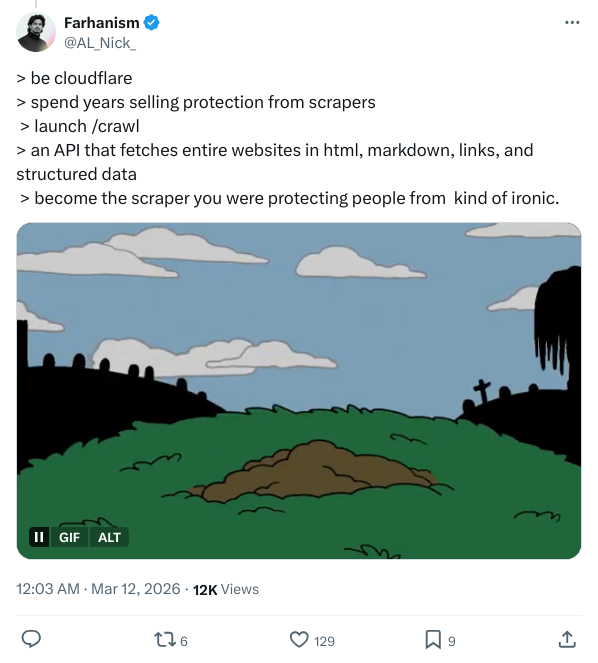
De volta à ironia original. O frenesi na rede social não foi sem motivo. x Um tweet do usuário @AL_Nick_ atingiu a lógica da empresa de fazer as coisas com precisão:
be cloudflare
spend years selling protection from scrapers
launch /crawl
become the scraper you were protecting people from
A imagem que acompanha é a frase clássica do Batman: “Ou você se aposenta com honra como herói, ou vive para se tornar um vilão”.”
Diante de todas as críticas na rede, os funcionários da Cloudflare apresentaram uma defesa muito inteligente na seção de comentários: eles acreditam que a causa principal dos rastreadores violentos que inundam a Internet atualmente é que “o custo de desenvolvimento de um rastreador educado é muito alto”. Portanto, eles fornecem uma API oficial que adere ao robots.txt por padrão, controla a frequência da concorrência para não sobrecarregar o servidor de destino e usa um User-Agent canônico.
Esse é um argumento lógico, mas não esconde seu conhecimento comercial. A realidade está na mesa: as empresas que pagam pelo WAF avançado da Cloudflare têm defesas que podem impedir a própria Cloudflare de enviar /crawl Solicitação?
Um desenvolvedor da comunidade chinesa, @chuhaiqu, acertou em cheio quando disse: “Antigamente: cobrava-se dinheiro para ajudar a bloquear rastreadores. Agora: você é pago para ajudá-lo a rastrear outros.”
Esse é, na verdade, o privilégio máximo de uma empresa baseada em plataforma. Ao mercantilizar os recursos de rastreamento, a Cloudflare aprofunda ainda mais a dependência dos desenvolvedores em seu ecossistema de computação para trabalhadores. Eles não se importam se você está rastreando outros ou impedindo que outros o rastreiem. Desde que os dados estejam fluindo e o tráfego esteja passando por seus nós de borda, o medidor está cumprindo a palavra.
Prática: implemente sua bomba de dados em cinco minutos
Deixando de lado a ética comercial, do ponto de vista de um desenvolvedor, essa ferramenta é realmente boa demais para ser verdade. Tudo o que você precisa é de uma conta da Cloudflare com Workers ativados e um token de API com direitos de renderização do navegador.
Com menos de 30 linhas de código, você pode realizar uma tarefa completa de rastreamento de dados em nível de site:
async function crawlSite(url, apiToken, accountId) {
// 1. 发起 POST 请求,创建爬取任务
const startRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl`,
{
method: 'POST',
headers: {
'Authorization': `Bearer ${apiToken}`,
'Content-Type': 'application/json'
},
// 请求输出 Markdown,对于静态内容关闭渲染以加速
body: JSON.stringify({ url, formats:['markdown'], render: false })
}
);
const { result: jobId } = await startRes.json();
// 2. 轮询 GET 请求,等待庞大的任务集群完成作业
while (true) {
const checkRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}?limit=1`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
const data = await checkRes.json();
if (data.result.status !== 'running') break;
// 礼貌的等待时间
await new Promise(r => setTimeout(r, 3000));
}
// 3. 任务结束,提取洗净后的数据
const finalRes = await fetch(
`https://api.cloudflare.com/client/v4/accounts/${accountId}/browser-rendering/crawl/${jobId}`,
{ headers: { 'Authorization': `Bearer ${apiToken}` } }
);
return (await finalRes.json()).result.records;
}
Eles até mesmo acompanharam o lançamento do MCP Server, o que significa que você pode usar o Cursor ou Claude IDEs de IA como esse chamam o sistema diretamente por meio de linguagem natural. Se você precisar de dados, a IA chamará automaticamente essa API minimalista para obtê-los de volta.
As antigas barreiras estão desmoronando e o custo marginal do acesso aos dados está convergindo infinitamente para perto de zero. Essa é uma notícia absolutamente ruim para os defensores do conteúdo aberto na Internet.





































