



O ARC-Hunyuan-Video-7B é um modelo multimodal de código aberto desenvolvido pelo ARC Lab da Tencent que se concentra na compreensão do conteúdo de vídeos curtos gerados pelo usuário. Ele oferece uma análise estruturada e aprofundada, integrando informações visuais, de áudio e textuais dos vídeos. O modelo pode lidar com elementos visuais complexos, informações de áudio de alta densidade e vídeos curtos de ritmo acelerado, e é adequado para cenários como pesquisa de vídeo, recomendação de conteúdo e resumo de vídeo. O modelo é dimensionado com 7 bilhões de parâmetros e é treinado em vários estágios, incluindo pré-treinamento, ajuste fino de instruções e aprendizado por reforço, para garantir inferência eficiente e resultados de alta qualidade. Os usuários podem acessar o código e os pesos do modelo via GitHub para facilitar a implantação em ambientes de produção.
Lista de funções
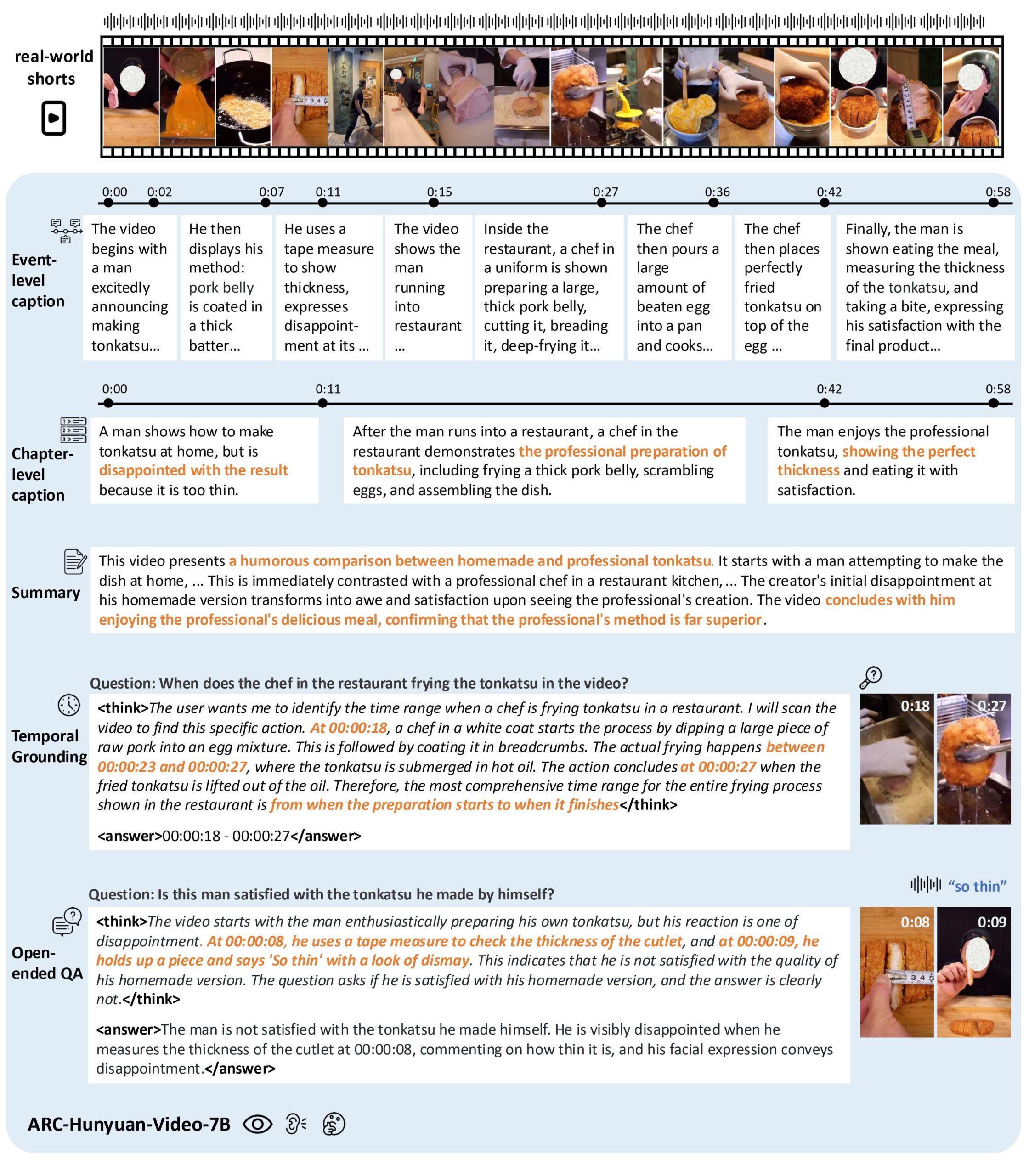
- Compreensão de conteúdo de vídeo: análise de imagens, áudio e texto de vídeos curtos para extrair informações essenciais e expressões emocionais.
- Anotação de carimbo de data/hora: suporte à descrição de vídeo com carimbo de data/hora de várias granularidades, anotação precisa da hora do evento.
- Questionário sobre o vídeo: Responda a perguntas abertas sobre o conteúdo do vídeo e entenda os cenários complexos do vídeo.
- Localização de tempo: Localize eventos ou clipes específicos em um vídeo, com suporte para pesquisa e edição de vídeo.
- Resumo do vídeo: gere um resumo conciso do conteúdo do vídeo, destacando as principais informações.
- Suporte a vários idiomas: suporte para análise de conteúdo de vídeo em chinês e inglês, especialmente otimizado para o processamento de vídeo chinês.
- Raciocínio eficiente: suporte vLLM Raciocínio acelerado de vídeo de 1 minuto em 10 segundos.
Usando a Ajuda
Processo de instalação
Para usar o ARC-Hunyuan-Video-7B, os usuários precisam clonar o repositório do GitHub e configurar o ambiente. Veja a seguir as etapas detalhadas:
- armazém de clones:
git lfs install git clone https://github.com/TencentARC/ARC-Hunyuan-Video-7B cd ARC-Hunyuan-Video-7B - Instalação de dependências:
Certifique-se de que o Python 3.8+ e o PyTorch 2.1.0+ (com suporte a CUDA 12.1) estejam instalados em seu sistema. Execute o seguinte comando para instalar as bibliotecas necessárias:pip install -r requirements.txt - Download dos pesos do modelo:
Os pesos do modelo estão hospedados no Hugging Face. Os usuários podem baixá-los com o seguinte comando:from huggingface_hub import hf_hub_download hf_hub_download(repo_id="TencentARC/ARC-Hunyuan-Video-7B", filename="model_weights.bin", repo_type="model")Ou faça o download manual diretamente do Hugging Face e coloque-o na pasta
experiments/pretrained_models/Catálogo. - Instale o vLLM (opcional):
Para acelerar o raciocínio, é recomendável instalar o vLLM:pip install vllm - Ambiente de verificação:
Execute o script de teste fornecido pelo repositório para verificar se o ambiente está configurado corretamente:python test_setup.py
Uso
O ARC-Hunyuan-Video-7B suporta operação local e chamada de API on-line. Veja a seguir o fluxo de operação da função principal:
1. compreensão do conteúdo do vídeo
Os usuários podem inserir um arquivo de vídeo curto (por exemplo, no formato MP4), e o modelo analisará o conteúdo visual, de áudio e textual do vídeo e produzirá uma descrição estruturada. Por exemplo, se um vídeo engraçado do TikTok for inserido, o modelo poderá extrair as ações, os diálogos e a música de fundo do vídeo e gerar uma descrição detalhada do evento.
procedimento:
- Prepare o arquivo de vídeo colocando
data/input/Catálogo. - Execute o script de raciocínio:
python inference.py --video_path data/input/sample.mp4 --task content_understanding - A saída é salva no arquivo
output/Um catálogo, no formato JSON, que contém uma descrição detalhada do conteúdo do vídeo.
2. rotulagem de carimbo de data/hora
O modelo suporta a geração de descrições com registro de data e hora para vídeos, adequadas para aplicativos que exigem localização precisa de eventos, como videoclipes ou pesquisas.
procedimento:
- Use o seguinte comando para executar a anotação de registro de data e hora:
python inference.py --video_path data/input/sample.mp4 --task timestamp_captioning - Exemplo de saída:
[ {"start_time": "00:01", "end_time": "00:03", "description": "人物A进入画面,微笑挥手"}, {"start_time": "00:04", "end_time": "00:06", "description": "背景音乐响起,人物A开始跳舞"} ]
3. teste de vídeo
Os usuários podem fazer perguntas abertas sobre o vídeo, e o modelo combina informações visuais e de áudio para respondê-las. Por exemplo, "O que os personagens estão fazendo no vídeo?" ou "Que emoção o vídeo expressa?"
procedimento:
- Criação de um arquivo de problema
questions.jsonO formato é o seguinte:[ {"video": "sample.mp4", "question": "视频中的主要活动是什么?"} ] - Execute o script do questionário:
python inference.py --question_file questions.json --task video_qa - A saída está no formato JSON e contém a resposta à pergunta.
4. orientação de tempo
A função de localizador de tempo permite localizar clipes de eventos específicos em um vídeo. Por exemplo, localizar um clipe de "pessoas dançando".
procedimento:
- Execute o script de posicionamento:
python inference.py --video_path data/input/sample.mp4 --task temporal_grounding --query "人物跳舞" - Os resultados de saída em um período de tempo, como
00:04-00:06。
5. resumo do vídeo
O modelo gera um resumo conciso do conteúdo do vídeo, destacando a mensagem principal.
procedimento:
- Execute o script de resumo:
python inference.py --video_path data/input/sample.mp4 --task summarization - Exemplo de saída:
视频展示了一位人物在公园跳舞,背景音乐欢快,传递了轻松愉快的情绪。
6. uso da API on-line
O Tencent ARC fornece uma API on-line que pode ser acessada por meio do Hugging Face ou de demonstrações oficiais. Visite a página de demonstração, carregue um vídeo ou insira uma pergunta, e o modelo retornará os resultados em tempo real.
procedimento:
- Visite a página de demonstração do ARC-Hunyuan-Video-7B da Hugging Face.
- Problemas para carregar arquivos de vídeo ou digitar.
- Visualize os resultados de saída e ofereça suporte ao download de dados de análise no formato JSON.
advertência
- resolução de vídeoA demonstração on-line usa resolução compactada, o que pode afetar o desempenho. Recomenda-se executá-la localmente para obter melhores resultados.
- Requisitos de hardwareGPUs NVIDIA H20 ou superior são recomendadas para garantir a velocidade de inferência.
- Suporte a idiomasO modelo é melhor otimizado para vídeos chineses e tem um desempenho ligeiramente pior para vídeos em inglês.
cenário do aplicativo
- Pesquisa de vídeo
Os usuários podem pesquisar eventos ou conteúdos específicos em um vídeo por palavras-chave, como "tutoriais de culinária" ou "clipes engraçados" em uma plataforma de vídeo. - Recomendação de conteúdo
O modelo analisa a mensagem principal e o sentimento do vídeo para ajudar a plataforma a recomendar conteúdo que corresponda aos interesses do usuário, como a recomendação de vídeos curtos com música animada. - clipe de vídeo
Os criadores podem usar os recursos de marcação de carimbo de data/hora e posicionamento de tempo para extrair rapidamente os principais clipes dos vídeos e criar clipes de destaque. - Educação e treinamento
Em vídeos instrucionais, o modelo pode gerar resumos ou responder às perguntas dos alunos para ajudar a entender rapidamente o conteúdo do curso. - Análise de mídia social
As marcas podem analisar o conteúdo gerado pelo usuário no TikTok ou no WeChat para entender as respostas emocionais e as preferências de seu público.
QA
- Quais formatos de vídeo são compatíveis com o modelo?
Formatos comuns, como MP4, AVI e MOV, são suportados, e recomenda-se que a duração do vídeo seja limitada a 1 a 5 minutos para otimizar o desempenho. - Como otimizar a velocidade de raciocínio?
Use o vLLM para acelerar a inferência e certifique-se de que a GPU seja compatível com CUDA 12.1. A redução da resolução do vídeo também reduz a quantidade de cálculos. - Ele é compatível com vídeos longos?
O modelo é otimizado principalmente para vídeos curtos (menos de 5 minutos). Vídeos mais longos precisam ser processados em segmentos, e é recomendável dividir o vídeo usando um script de pré-processamento. - O modelo oferece suporte ao processamento em tempo real?
Sim, quando implantado com o vLLM, a inferência de vídeo de 1 minuto leva apenas 10 segundos, o que o torna adequado para aplicativos em tempo real.






























