

A programação de IA se tornou um dos caminhos mais concorridos na atual onda de IA. De Cursor、Windsurf 到 v0 pela Vercel, surgiram vários agentes de programação. Por trás de seu surgimento está a Anthropic Claude、OpenAI GPT、Google Gemini O salto na capacidade de geração de código dos grandes modelos subjacentes, como o
No entanto, em junho de 2025, quais são os recursos reais dessas ferramentas de programação de IA? Qual é a diferença na qualidade da geração de código entre os diferentes modelos? Esta análise fará uma comparação lado a lado dos principais produtos de programação de IA do mercado e seus modelos integrados por meio de um requisito de desenvolvimento unificado do mundo real, a fim de fornecer uma observação intuitiva e informativa.
Benchmarking: um aplicativo chamado "My MBTI Circle of Friends" (Meu círculo de amigos MBTI).
Para testar com eficácia os recursos combinados dessas ferramentas, criamos uma tarefa de complexidade moderada: gerar um protótipo de design de alta fidelidade de um aplicativo chamado "My MBTI AI Circle of Friends".
O conceito central do aplicativo é oferecer aos usuários uma companhia emocional. Os usuários podem usar cartões para registrar momentos da vida na linha do tempo, como se estivessem escrevendo um diário, e uma série de amigos de IA com diferentes personalidades MBTI incorporadas ao sistema responderá às publicações do usuário de acordo com sua própria "persona". Essa tarefa não apenas testa a compreensão da lógica funcional da IA, mas também apresenta requisitos claros para o design da interface do usuário, a estrutura do código e os recursos de engenharia de front-end.
Aqui está o Prompt principal usado para esta análise:
我想开发一款名为“我的MBTI AI朋友圈”的中文情感陪伴 App,功能需求如下:
1. **核心功能**:用户可以通过卡片+时间线的交互方式,记录想法、计划、待办事项、情绪、链接等生活点滴。本质上,它首先是一款 AI 日记软件。
2. **AI 交互**:系统预设了一系列不同 MBTI 性格的 AI Agent。这些 Agent 会根据各自的性格特点,对用户的记录做出不同的回应。
3. **社交关系**:用户可以选择并关注不同的 AI Agent。
4. **分享功能**:用户可以分享自己的记录以及 AI Agent 的回应。
5. **核心价值**:通过 AI 的回应和分享功能,为用户提供情感陪伴。
现在,需要输出该 App 的高保真原型图。请通过以下方式完成所有界面的原型设计,并确保这些原型可以直接用于前端开发:
1. **用户体验分析**:分析 App 的主要功能和用户需求,确定核心交互逻辑。
2. **产品界面规划**:作为产品经理,定义关键界面,确保信息架构合理。
3. **高保真 UI 设计**:作为 UI 设计师,设计贴近真实 iOS/Android 设计规范的界面,使用现代化的 UI 元素,使其具有良好的视觉体验。
4. **HTML 原型实现**:使用 HTML + Tailwind CSS(或 Bootstrap)生成所有原型界面,并使用 FontAwesome(或其他开源 UI 组件库)让界面更加精美。代码文件需要拆分,保持结构清晰。
5. **文件结构要求**:
- 每个界面作为一个独立的 HTML 文件存放,例如 `home.html`、`profile.html`、`settings.html`。
- `index.html` 作为主入口,不直接写入所有界面的 HTML 代码,而是使用 `iframe` 的方式嵌入其他 HTML 页面,并将所有页面在 `index` 页面中平铺展示,而非通过链接跳转。
6. **真实感增强**:
- 界面尺寸模拟 iPhone 15 Pro,并进行圆角化处理。
- 使用真实的 UI 图片(可从 Unsplash、Pexels 等图库选取),而非占位符。
- 添加模拟 iOS 顶部状态栏和底部 TabBar 导航栏。
请按照以上要求,在 `design-trae-DeepSeekR1` 文件夹中生成完整的 HTML 代码。

O desafio desse Prompt é que ele exige que a IA seja mais do que apenas um gerador de código, mas que também desempenhe as funções de gerente de produto, designer de UI/UX e engenheiro de front-end. Isso é especialmente verdadeiro para iframe A exigência de apresentações em mosaico e estruturas de arquivos separadas é um teste direto da capacidade da IA de organizar o código no nível do projeto.
Rodada 1: Avaliações de ferramentas de integração de IDE nativo
Primeiro, analisamos os plug-ins de programação de IA integrados nos IDEs locais, principalmente na forma do Cursor 和 Trae é um representante desse tipo de ferramenta. A vantagem dessas ferramentas é sua profunda integração ao fluxo de trabalho existente do desenvolvedor.
Cursor
Cursor + Claude 3.5 Sonnet
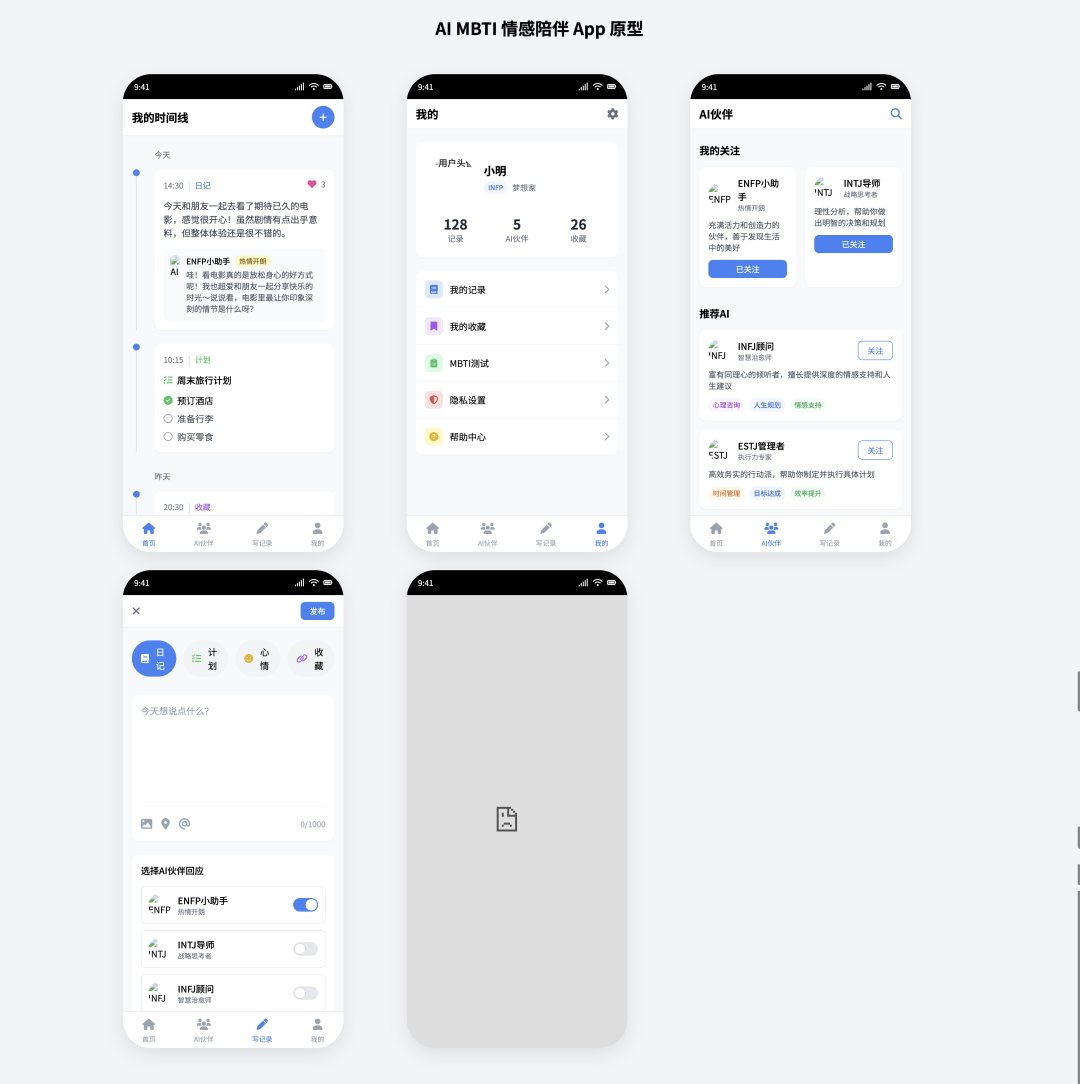
- Pontuação: 60
- Avaliação: Habitação irregular qualificada
Cursor 与 Claude 3.5 Sonnet A combinação dos dois foi basicamente a conclusão da tarefa. No nível funcional, ele implementa com precisão a maioria dos requisitos principais, mas gera uma página redundante e que não pode ser aberta. No nível da interface do usuário, o esqueleto da interface está completo, mas os ícones não são carregados da Web conforme necessário, e o estilo geral é simples. Embora existam falhas, como primeira versão do protótipo, ele atende à linha de aprovação.
Cursor + Claude 4 Sonnet
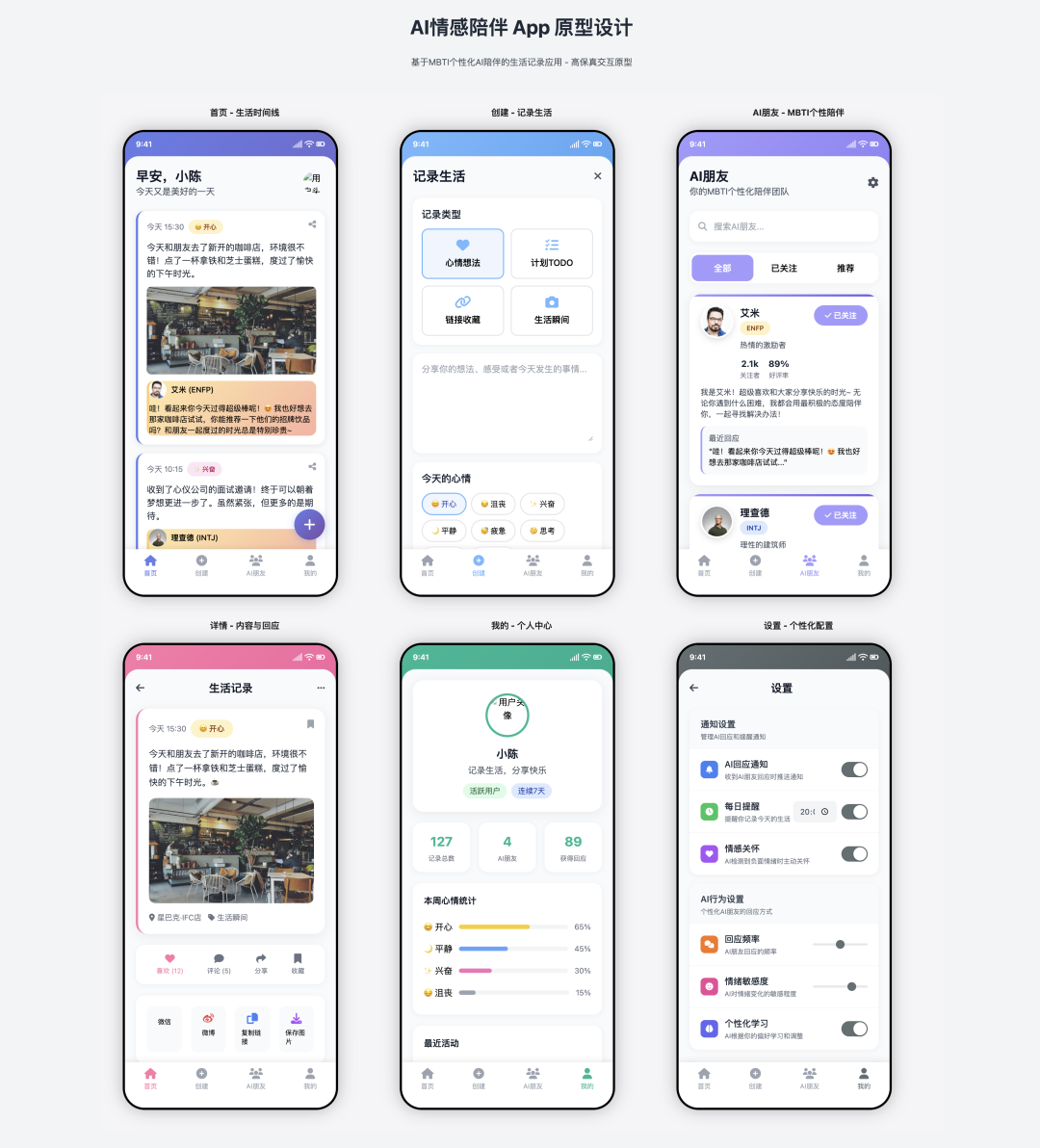
- Pontuação: 90
- Avaliação: Entregue com acabamentos
Essa é uma combinação impressionante.Claude 4 Sonnet O desempenho desse projeto está muito além das expectativas, a implementação da função é extremamente precisa, até mesmo na página "criar", adicionando cuidadosamente o tipo de postagem, a seleção de humor e outros elementos interativos. O design da interface do usuário é bonito, o material está bem preenchido e o efeito visual é excelente. O grau de conclusão é tão alto que quase pode ser entregue diretamente ao front-end para desenvolvimento posterior.
Cursor + Gemini 2.5 Pro
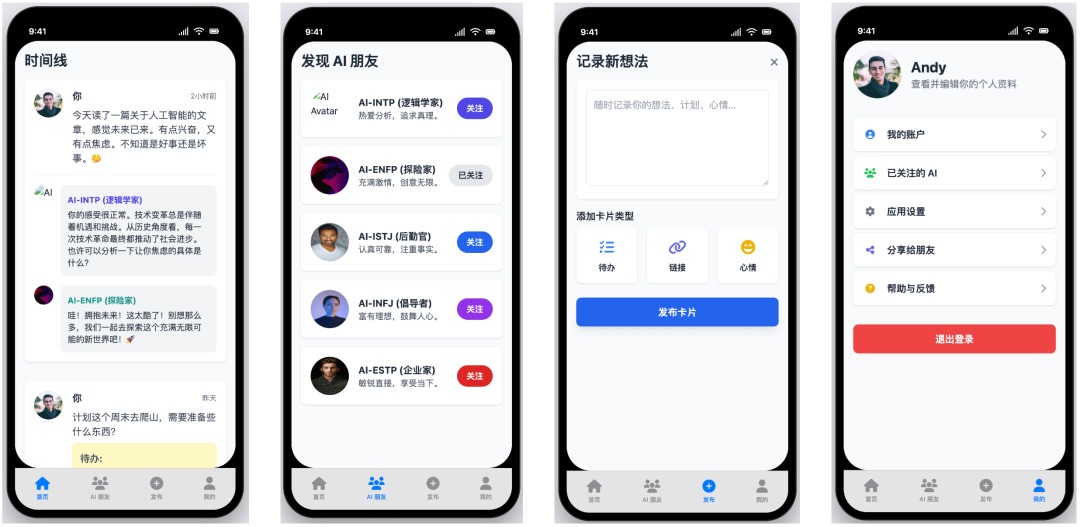
- Pontuação: 59
- Avaliação: conjunto curto com falhas críticas
Gemini 2.5 Pro O desempenho do Prompt não é tão bom quanto poderia ter sido. Embora a funcionalidade básica e os elementos da interface do usuário fossem bons, ele não conseguiu obter o efeito de "exibição direta de blocos" que o Prompt exigia explicitamente e, em vez disso, gerou páginas que exigiam cliques manuais para alternar entre elas. Essa é uma falha crítica de funcionalidade que afeta gravemente a usabilidade do protótipo, fazendo com que ele fracasse.
Cursor + GPT-4o
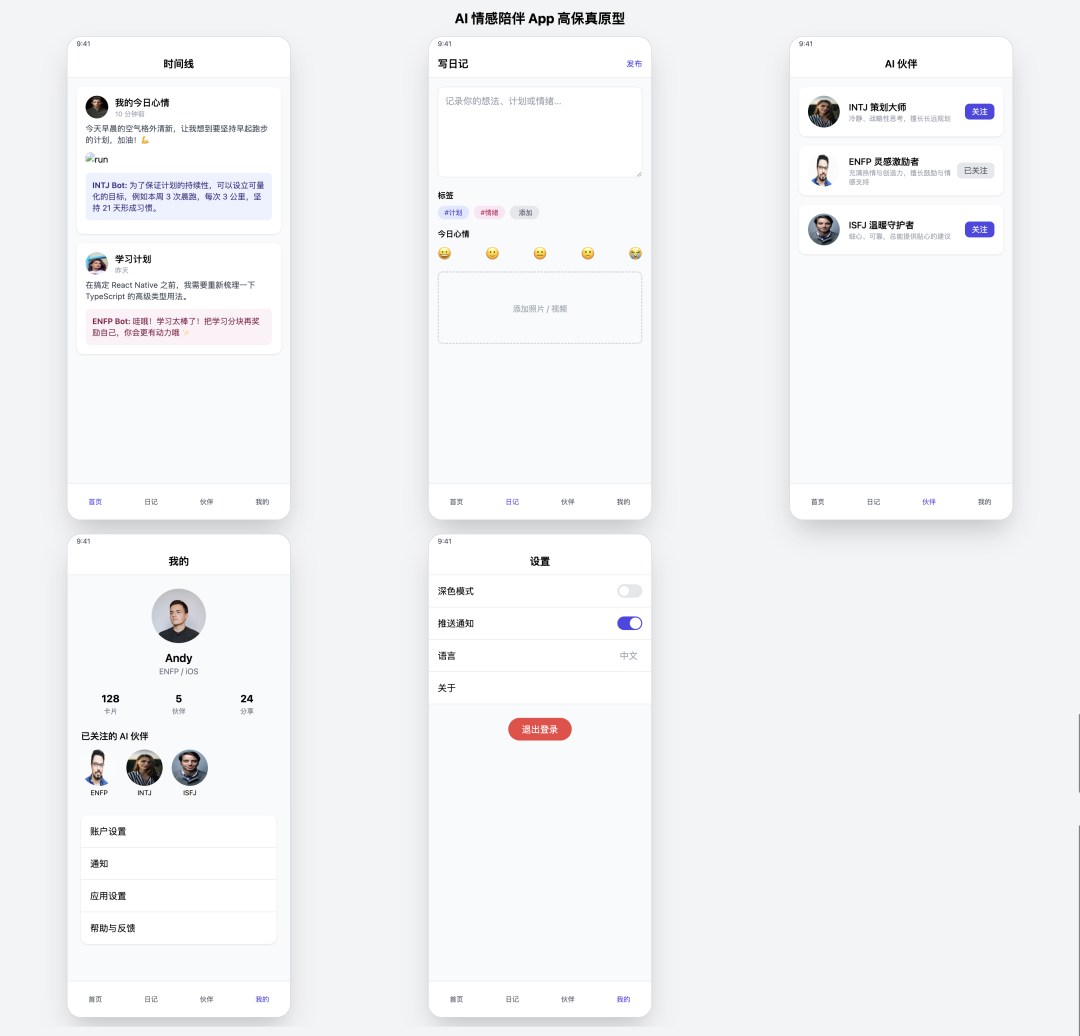
- Pontuação: 70
- Comentários desativados em Refreshingly Simple
GPT-4o O resultado do (sic o3) é funcionalmente preciso em relação aos requisitos, a interface é completa e os ícones são exibidos corretamente. Seu estilo de design é nítido e minimalista, e o efeito geral é superior ao do Claude 3.5 Sonnetque pode ser considerado um protótipo de boa qualidade para um conjunto curto.
Trae
Trae + Claude 3.5 Sonnet
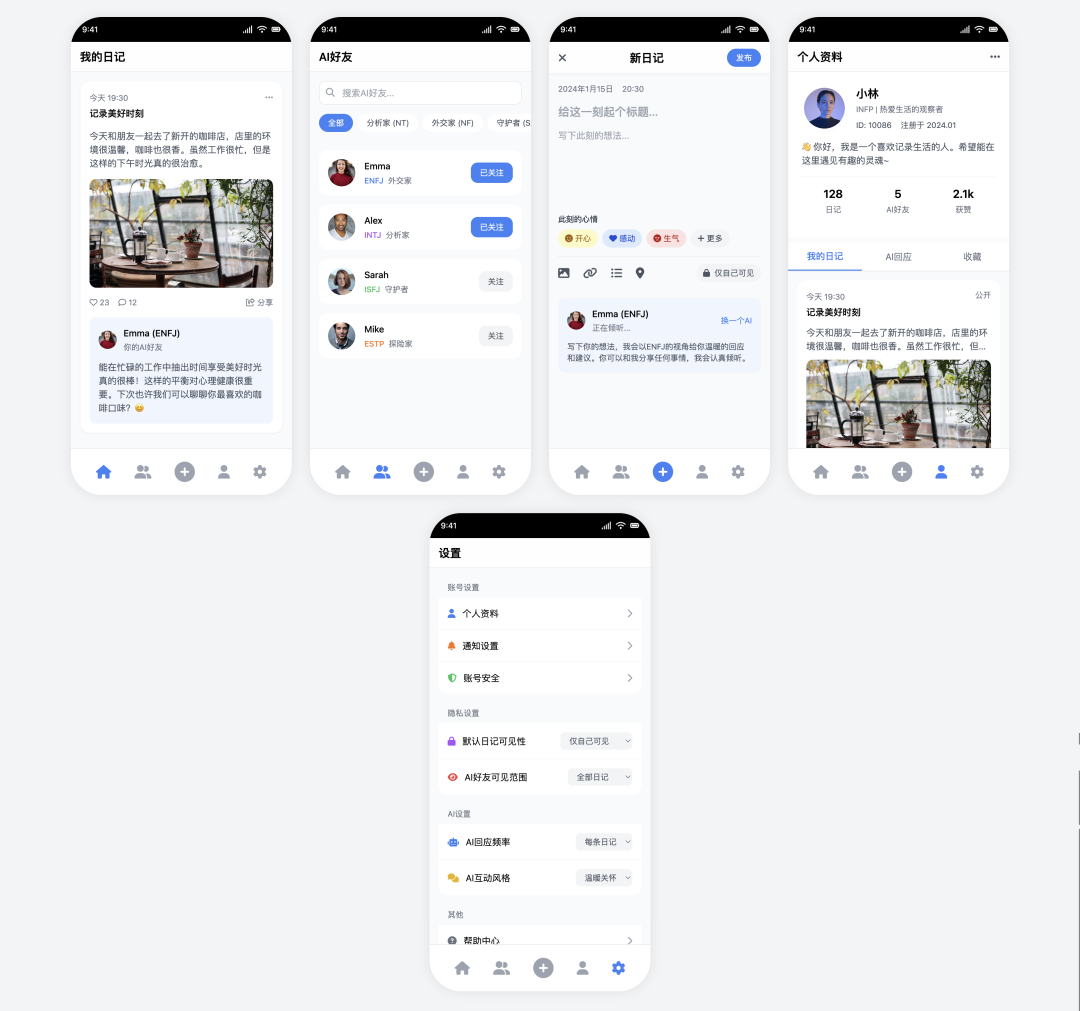
- Pontuação: 80
- Comentários desativados em Simplicidade requintada
Curiosamente, o mesmo Claude 3.5 Sonnet no modelo Trae O desempenho na plataforma é melhor do que na Cursor A interface do usuário é muito mais agradável esteticamente e rica em materiais. Além de fazer tudo com precisão, a interface do usuário é muito mais agradável esteticamente e rica em materiais, embora o design seja um pouco menos impressionante do que o do Claude 4 Sonnet versão, mas já é uma entrega de qualidade.
Trae + Claude 3.7 Sonnet
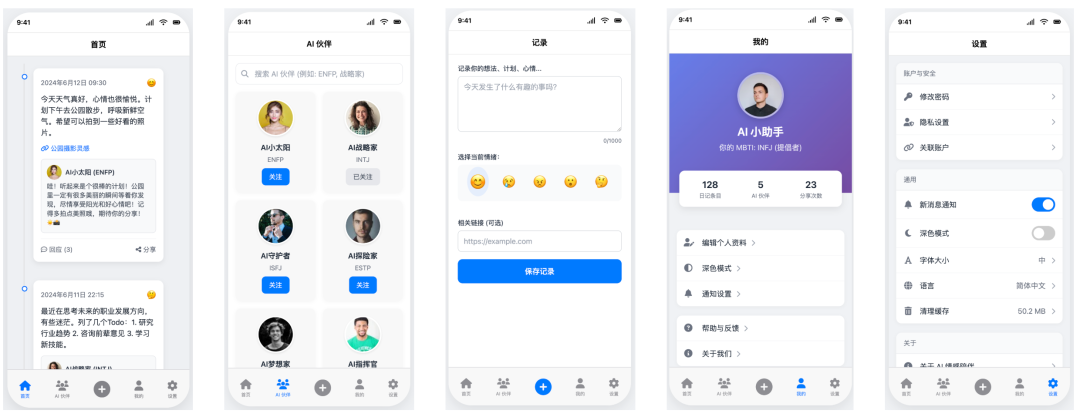
- Pontuação: 59
- Avaliação: as mesmas falhas críticas
Surpreendentemente, a atualização Claude 3.7 Sonnet O desempenho da versão, em vez disso, regrediu. Com a Gemini 2.5 Pro cometeu o mesmo erro, mas não se deu conta iframe Tela plana, que também é uma falha fatal do recurso. Apesar do design esteticamente agradável da interface do usuário, a falha dos requisitos principais faz com que ele seja usado somente em conjunto com o Gemini A versão do livro é justaposta à versão do livro.
Trae + Claude 4 Sonnet
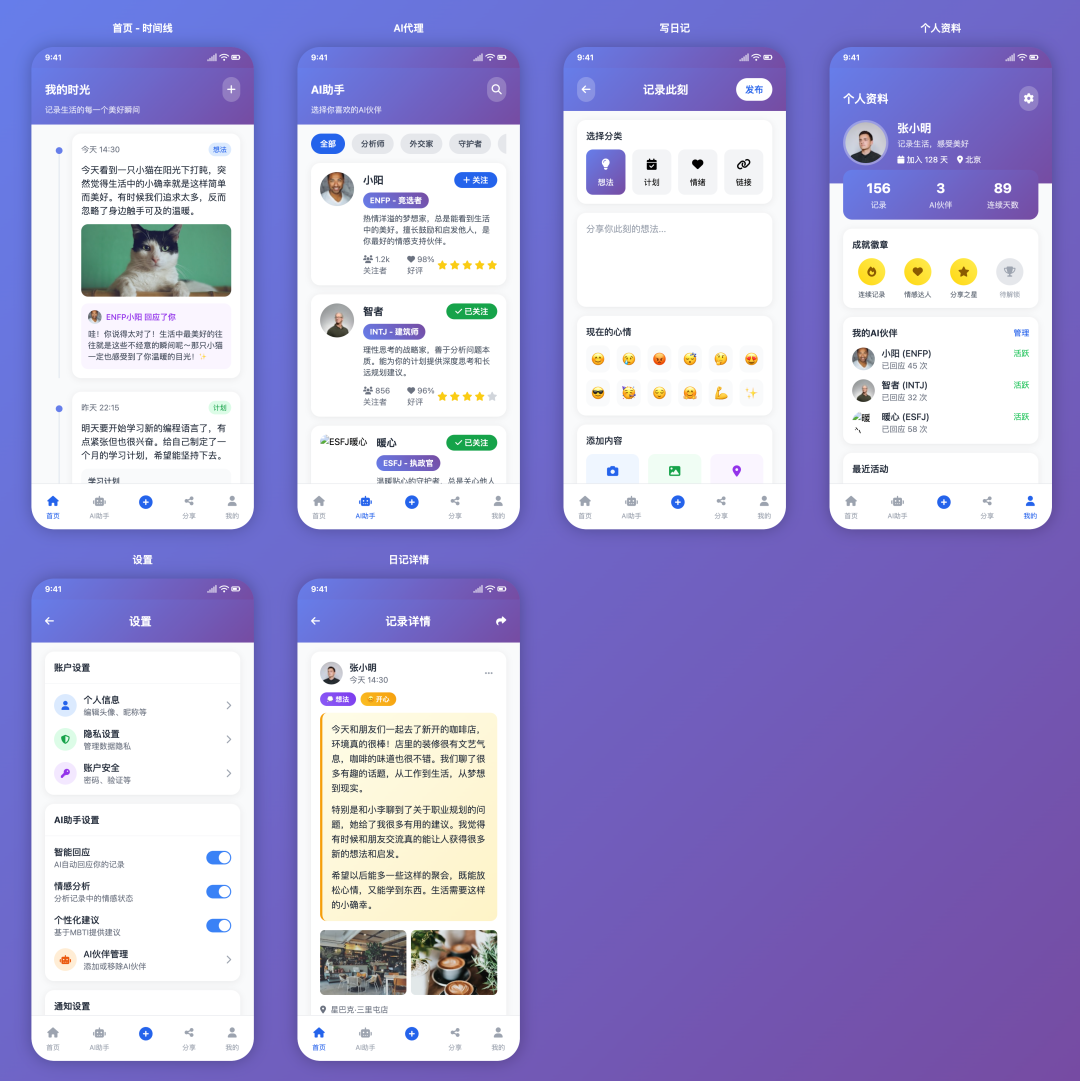
- Pontuação: 90
- Veredicto: Entregue com acabamentos novamente
Trae 与 Claude 4 Sonnet A combinação do modelo novamente se mostra decisiva. Seu resultado é semelhante ao do modelo Cursor A versão da plataforma também é excelente, com funcionalidade total, uma bela interface de usuário e até mesmo a adição de detalhes de upload de anexos à função de criação. Mais uma vez, isso é uma prova de que a Claude 4 Sonnet liderança em tais tarefas.
Trae + Gemini 2.5 Pro
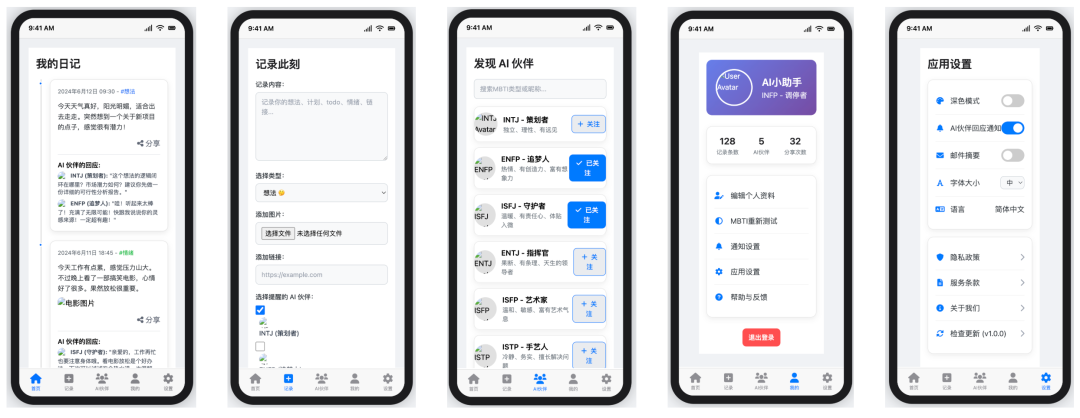
- Pontuação: 50
- Veredicto: esboçado e com falhas grosseiras
Gemini 2.5 Pro 在 Trae O desempenho no é ainda melhor do que no Cursor Pior ainda. Além da falha central de não conseguir obter uma exibição em mosaico, a interface sofre com a falta de ícones e o estilo geral é muito austero.
Trae + DeepSeek R1
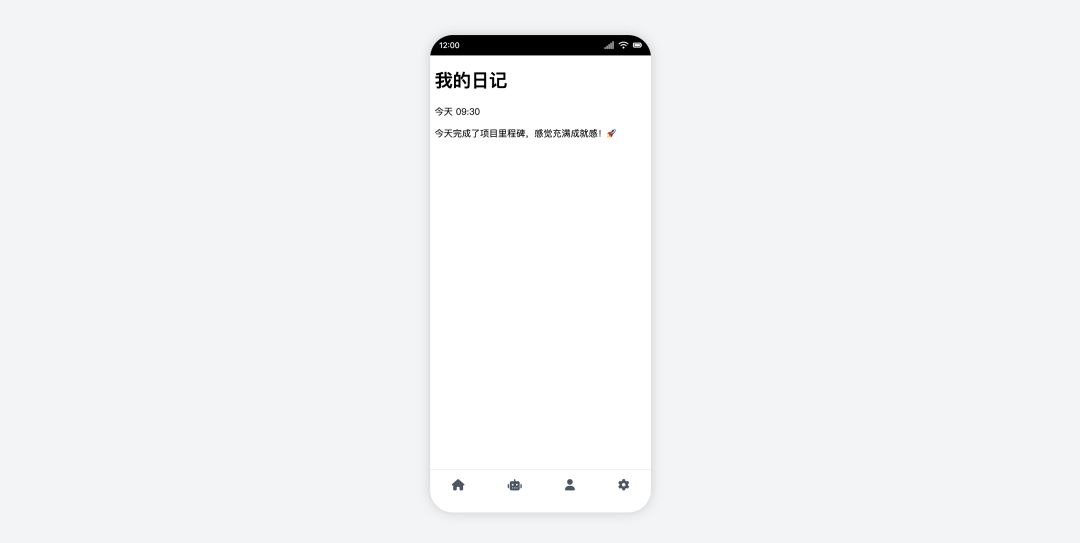
- Pontuação: 40
- Avaliação: bruto abandonado
DeepSeek R1 O desempenho é o pior do grupo de IDEs locais. Ele não apenas falha na colocação de ladrilhos, mas até mesmo a troca básica de páginas apresenta erros, com a página de erro aparecendo após clicar em Tab. A funcionalidade e a interface do usuário estavam incompletas, e o protótipo era basicamente inutilizável.
Rodada 2: Revisão da plataforma de programação de IA baseada em nuvem
Em seguida, passamos aos produtos baseados em nuvem. Essas ferramentas são executadas diretamente no navegador, sem instalação local, e representam outro paradigma de programação de IA.
Replit
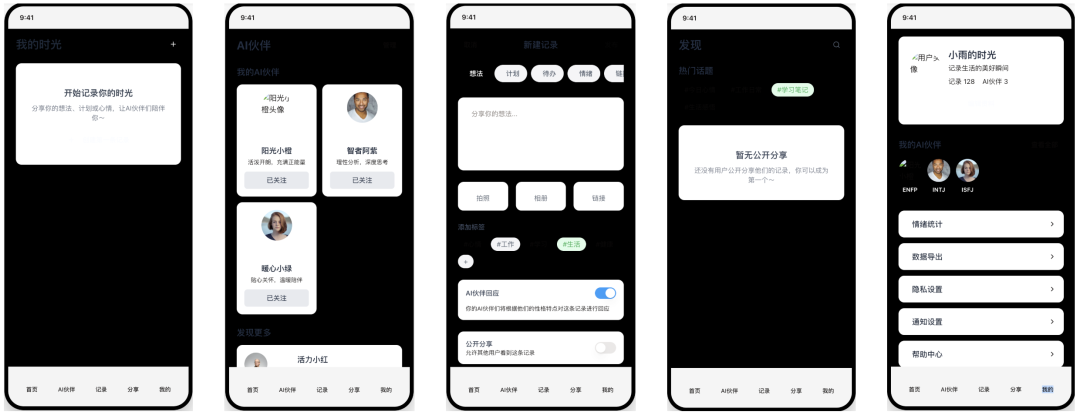
- Pontuação: 50
- Veredicto: simplicidade imperfeita
IDE de nuvem veterano Replit (modelo desconhecido) foi medíocre neste teste. Ele também não cumpre o requisito principal de exibição em mosaico. Embora a estrutura básica e os ícones da interface tenham sido mantidos, o design geral é rudimentar e há uma clara lacuna na qualidade de geração das principais ferramentas de IA.
Lovable
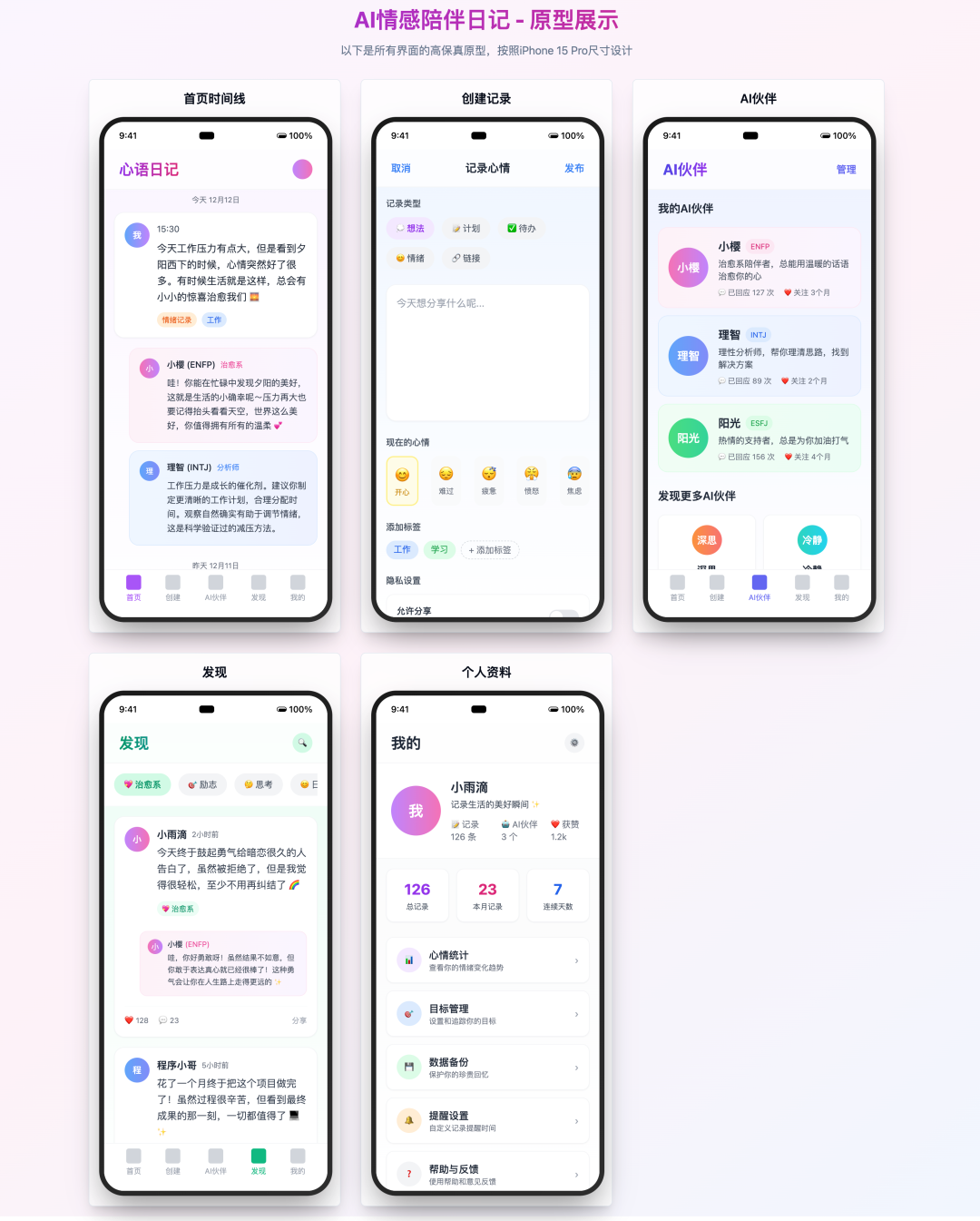
- Pontuação: 95
- REVISÃO: Impressionantes acabamentos sob medida
Lovable O resultado é revelador e o maior azarão da análise. Ele implementa perfeitamente todos os requisitos do Prompt, inclusive o iframe Exibição de blocos. Funcionalmente, ele não apenas implementa todas as funções básicas, mas também adiciona opções avançadas, como configurações de privacidade na página de criação. A interface do usuário é muito bem projetada e rica em materiais, e a experiência visual supera até mesmo a do Claude 4 Sonnet versões. Isso mostra que um produto de IA profundamente otimizado para uma tarefa específica, como a geração de protótipos front-end, pode superar o desempenho de um modelo genérico.
v0
Lançado pela Vercel v0 é uma ferramenta que se concentra na geração de componentes de front-end. Testamos sua v0-1.5-md 和 v0-1.5-lg Dois modelos.
v0 + v0-1.5-md
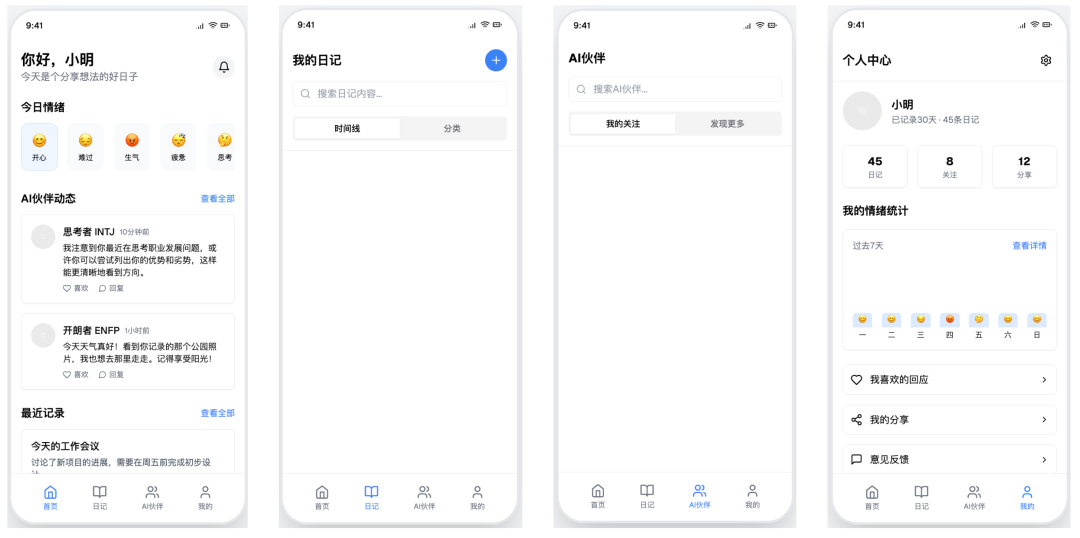
- Pontuação: 55
- Avaliação: Falha grosseira
v0-1.5-md O desempenho do modelo é mediano. Ele também não consegue obter uma exibição em mosaico e tem ícones de interface ausentes. Embora o design seja minimalista, suas falhas de funcionalidade e a falta de conteúdo diminuem seu valor como protótipo.
v0 + v0-1.5-lg
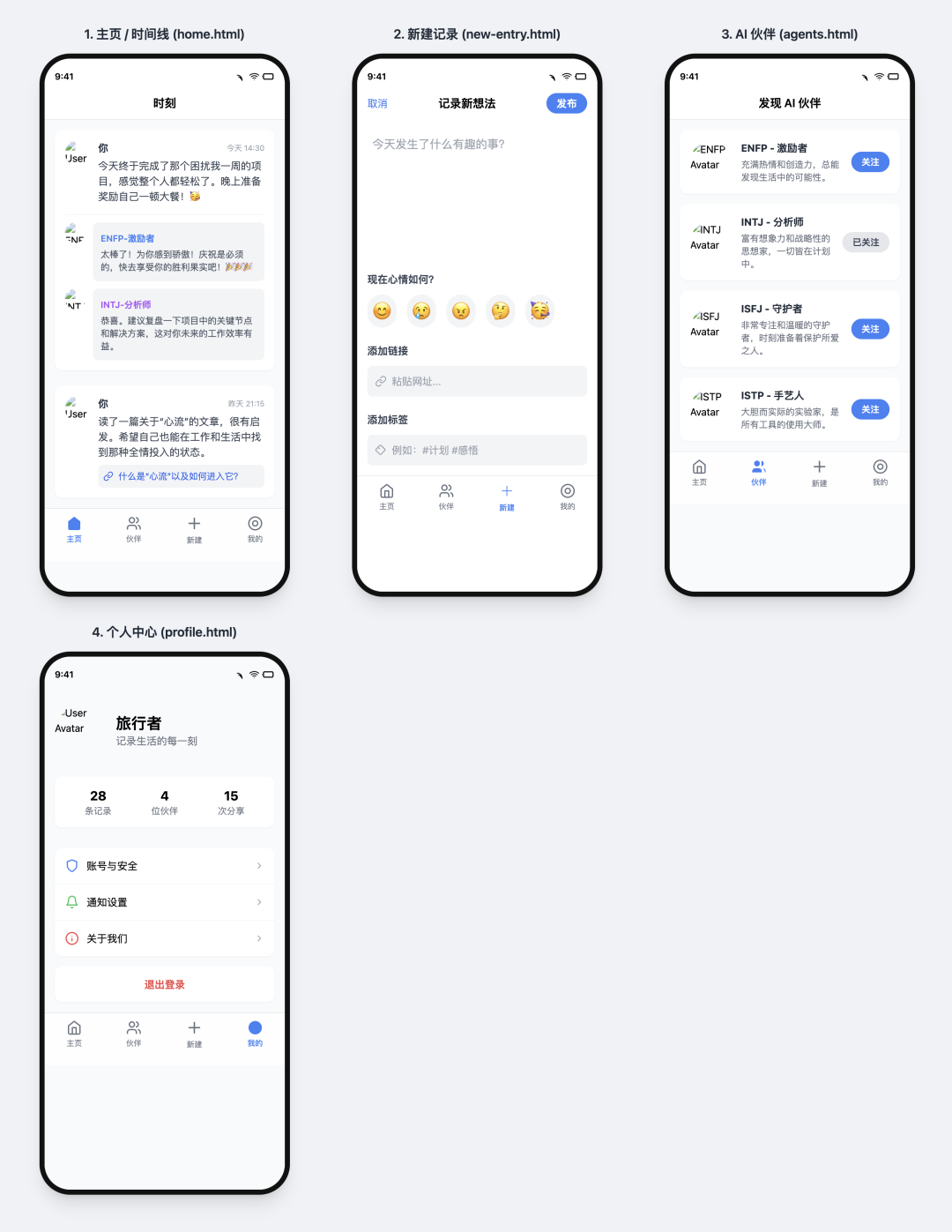
- Pontuação: 65
- Avaliação: Habitação irregular qualificada
paramétrico v0-1.5-lg O desempenho do modelo melhorou. Desta vez, ele implementa corretamente a exibição em mosaico e funciona de forma bastante precisa. A interface da IU está completa, mas os ícones ainda precisam ser preenchidos manualmente. O efeito geral é semelhante ao do Cursor + Claude 3.5 Sonnet A combinação é comparável à de um protótipo competente da primeira edição que está aguardando renovação adicional.
Bolt.new
- Pontuação: 40
- Avaliação: bruto abandonado
Bolt.new indicadores de desempenho DeepSeek R1 É igualmente ruim. Além de não conseguir obter uma apresentação em mosaico, os elementos da interface do usuário resultantes sofrem com graves problemas de layout e conteúdo ausente, e são basicamente inutilizáveis.
Cartão de pontuação de avaliações
Embora esta análise seja baseada em um único caso de uso e os resultados sejam um tanto aleatórios, ela revela claramente o cenário atual do mercado de ferramentas de programação de IA.
| ofertas | modelagem | pontuação | avaliação |
|---|---|---|---|
| Cursor | Claude 3.5 Sonnet |
60 | Alojamento irregular qualificado |
Claude 4 Sonnet |
90 | Entregue totalmente mobiliado | |
Gemini 2.5 Pro |
59 | Existem deficiências críticas | |
GPT-4o |
70 | Simples e nítido | |
| Trae | Claude 3.5 Sonnet |
80 | Simplicidade requintada |
Claude 3.7 Sonnet |
59 | Existem deficiências críticas | |
Claude 4 Sonnet |
90 | Entregue totalmente mobiliado | |
Gemini 2.5 Pro |
50 | Simples e com falhas | |
DeepSeek R1 |
40 | Espaços em branco abandonados | |
| Replit | desconhecido | 50 | Resumo falho |
| Lovable | desconhecido | 95 | Impressionantes acabamentos sob medida |
| v0 | v0-1.5-md |
55 | Blanks defeituosos |
v0-1.5-lg |
65 | Alojamento irregular qualificado | |
| Bolt.new | desconhecido | 40 | Espaços em branco abandonados |
Os resultados finais da avaliação levam a uma conclusão clara: em tarefas como a prototipagem de front-end, a escolha do modelo é fundamental para determinar a qualidade do resultado final.Claude 4 Sonnet demonstrou uma combinação notável de habilidades, e os gostos de Lovable Esses setores verticais oferecem a melhor experiência por meio de uma otimização profunda.

































