Going Small: Como fazer um modelo de 0,6 B parecer um modelo de 235 B por meio da destilação de modelos
Os modelos de linguagem grandes (LLMs) são excelentes, mas seu alto custo computacional e a baixa velocidade de inferência são as principais barreiras para a aplicação prática. Uma solução eficaz é a destilação de modelos: primeiro, gere dados anotados de alta qualidade usando um modelo de professor avançado (modelo de parâmetros grandes) e, em seguida, use esses dados para "ensinar" um modelo de aluno menor e mais econômico (modelo de parâmetros pequenos). Os dados são então usados para "ensinar" um "modelo de aluno" menor e mais econômico (modelo de parâmetro pequeno). Dessa forma, o modelo pequeno pode atingir um desempenho próximo ao do modelo grande em uma determinada tarefa.
Neste artigo, daremos o exemplo da extração de informações logísticas (destinatário, endereço, número de telefone) do texto e demonstraremos detalhadamente como criar um arquivo parametrizado de 0,6B Qwen3-0.6B a precisão na tarefa de extração de informações melhora de 14% para 98%, o que é comparável aos resultados do modelo maior.
A comparação dos resultados antes e depois da otimização é muito visual:

Processos centrais do programa
Todo o processo é dividido em três etapas principais:
- Preparação de dadosModelo de treinamento: Um modelo grande de 235B é usado como modelo de professor para processar um lote de descrições de endereços virtuais e gerar dados JSON estruturados como um conjunto de treinamento de alta qualidade. Nos negócios reais, dados de cenas reais devem ser usados para obter os melhores resultados.
- Modelagem do ajuste finoUsando os dados gerados na etapa anterior, o
Qwen3-0.6BO modelo é ajustado. Esse processo usará oms-swiftque reduz operações complexas de ajuste fino a comandos de linha única. - Verificação da eficáciaAvalie o desempenho do modelo antes e depois do ajuste fino em um conjunto de testes independentes para quantificar os ganhos de desempenho e garantir a estabilidade e a precisão do modelo em ambientes de produção.
I. Preparando o ambiente de computação
O ajuste fino de modelos grandes precisa ser equipado com GPU ambiente de computação e instalar corretamente o GPU Dirigir,CUDA 和 cuDNN. A configuração manual dessas dependências não é apenas tediosa, mas também propensa a erros. Para simplificar a implementação, é recomendável criar o arquivo GPU Quando você seleciona uma instância de servidor em nuvem com GPU imagem do motorista para iniciar rapidamente a tarefa de ajuste fino.
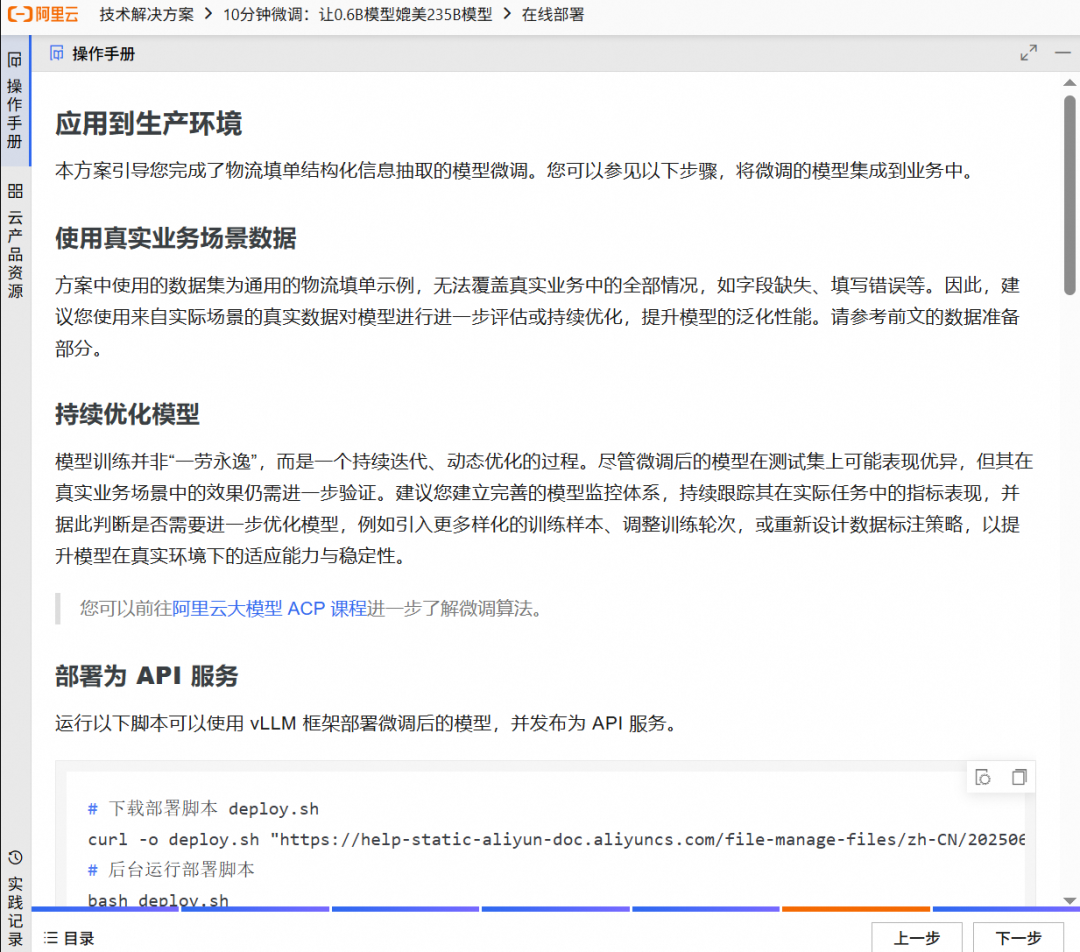
Esse programa pode ser experimentado por meio de recursos de avaliação gratuitos. Os recursos e dados criados durante o período de avaliação serão eliminados ao final do período de avaliação. Se você precisar usá-lo por um longo período, consulte as diretrizes de criação manual na documentação oficial.
- Crie recursos de acordo com o guia da página, o lado direito mostrará o progresso da criação em tempo real.
- Depois de criado, faça login por meio do recurso de conexão remota no
GPUServidores em nuvem.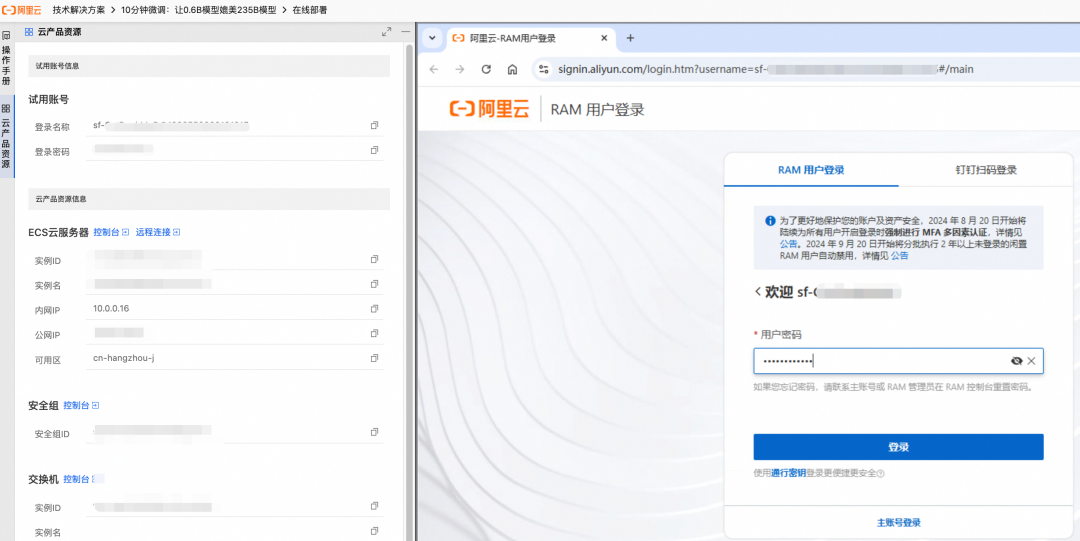
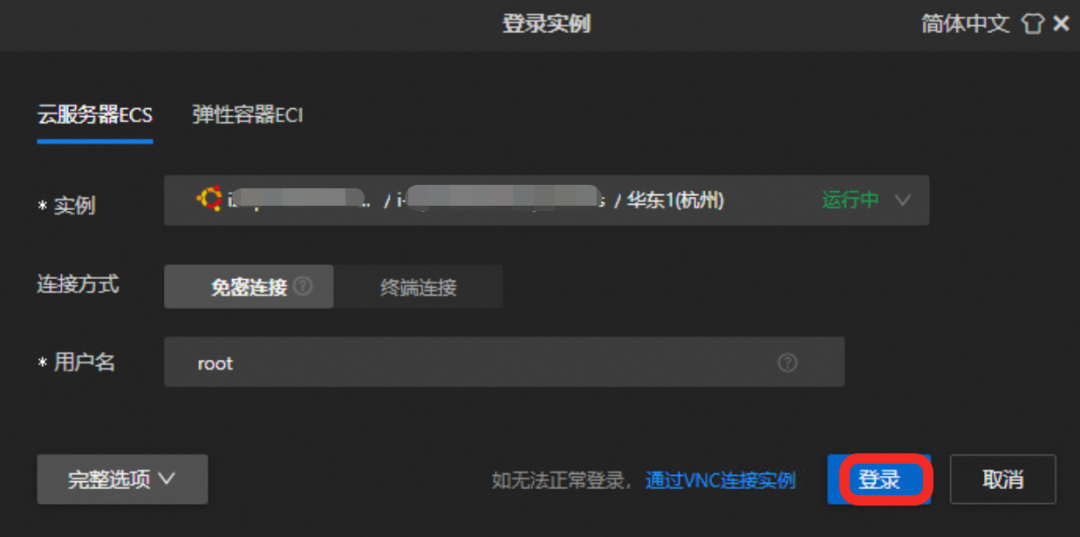
Clique no botão "Remote Connect" (Conexão remota) e faça login com as credenciais fornecidas.
II. Download e ajuste fino do modelo
Disponível na comunidade Magic Match (ModelScope) ms-swift que pode simplificar drasticamente o complexo processo de ajuste fino do modelo.
1. instalação de dependências
Esse programa se baseia em dois componentes principais:
ms-swiftEstrutura de treinamento de alto desempenho fornecida pela comunidade Magic Hitch que integra download de modelos, ajuste fino e fusão de pesos.vllmDescrição: uma estrutura para implantação e raciocínio sobre serviços que oferece suporte ao raciocínio de alto desempenho, facilita a validação dos efeitos do modelo e geraAPIPara chamadas comerciais.
Execute o seguinte comando no terminal para instalar as dependências (leva cerca de 5 minutos):
pip3 install vllm==0.9.0.1 ms-swift==3.5.0
2. ajuste fino do modelo de implementação
Execute o script a seguir para automatizar todo o processo de download do modelo, preparação de dados, ajuste fino do modelo e mesclagem de pesos.
# 进入 /root 目录
cd /root && \
# 下载微调脚本 sft.sh
curl -f -o sft.sh "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250623/cggwpz/sft.sh" && \
# 执行微调脚本
bash sft.sh
O processo de ajuste fino leva cerca de 10 minutos.sft.sh Os principais comandos do script são os seguintes:
swift sft \
--model Qwen/Qwen3-0.6B \
--train_type lora \
--dataset 'train.jsonl' \
--torch_dtype bfloat16 \
--num_train_epochs 10 \
--per_device_train_batch_size 20 \
--per_device_eval_batch_size 20 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--save_steps 1 \
--save_total_limit 2 \
--logging_steps 2 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4
Alguns dos principais parâmetros são descritos aqui:
--train_type loraAjuste fino: especifique o uso do método LoRA (Low-Rank Adaptation) para o ajuste fino. Esse é um método de ajuste fino eficiente em termos de parâmetros que treina apenas um pequeno número de pesos adicionados em comparação com o ajuste fino completo, reduzindo consideravelmente os requisitos de recursos computacionais.--lora_rank:: A classificação da matriz LoRA. Quanto maior a classificação, melhor o modelo se ajusta a tarefas complexas, mas uma classificação muito grande pode levar a um ajuste excessivo.--lora_alpha: o fator de escala do LoRA, comlearning_rateDa mesma forma, para ajustar a magnitude das atualizações de peso.--num_train_epochsRodadas de treinamento. Determina a profundidade com que o modelo aprende os dados.
Durante o processo de treinamento, o terminal imprime a alteração na perda (perda) do modelo nos conjuntos de treinamento e validação em tempo real.

Quando o seguinte resultado for exibido, isso indica que o ajuste fino do modelo e a fusão de pesos foram concluídos com êxito:
✓ swift export 命令执行成功
检查合并结果...
✓ 合并目录创建成功: output/v0-xxx-xxx/checkpoint-50-merged
✓ LoRA权重合并完成!
合并后的模型路径: output/v0-xxx-xxx/checkpoint-50-merged
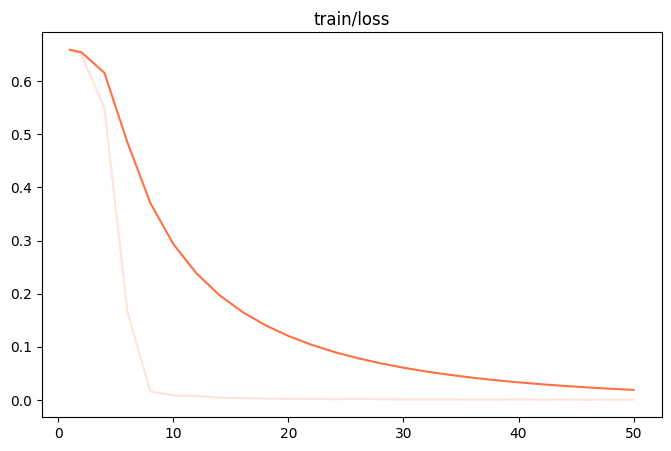
Quando o ajuste fino estiver concluído, o output/v0-xxx-xxx/images para encontrar o diretório train_loss.png 和 eval_loss.png Dois gráficos que visualizam o estado de treinamento do modelo.
| train_loss (perda do conjunto de treinamento) | eval_loss (perda do conjunto de validação) |
|---|---|
 |
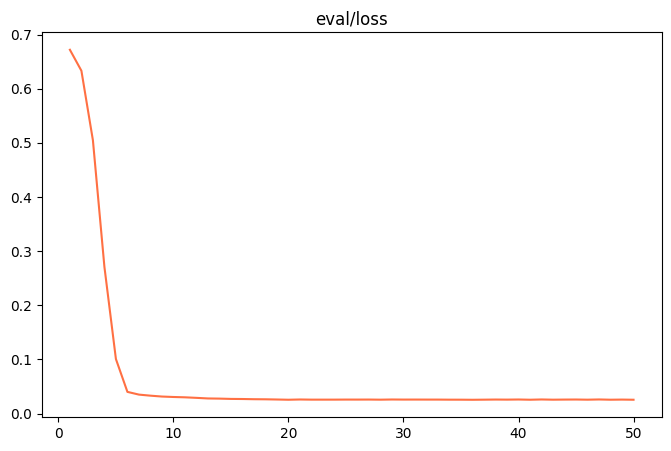 |
- ajuste inadequadoSe
train_loss和eval_lossNo final do treinamento, ainda há uma tendência de queda significativa, tente adicionarnum_train_epochs或lora_rank。 - sobreajusteSe
train_lossDeclínio contínuo, maseval_lossEm vez disso, ele começa a aumentar, indicando que o modelo aprendeu demais os dados de treinamento e deve ser reduzidonum_train_epochs或lora_rank。 - bom ajusteQuando ambas as curvas se estabilizam, isso indica que o treinamento do modelo atingiu um estado ideal.
III Validação dos efeitos do modelo
Uma revisão sistemática é uma parte essencial do processo antes da implantação em um ambiente de produção.
1. preparação dos dados de teste
Os dados de teste devem estar no mesmo formato que os dados de treinamento e devem ser completamente novos e nunca vistos pelo modelo para avaliar sua capacidade de generalização.
cd /root && \
# 下载测试数据 test.jsonl
curl -o test.jsonl "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250610/mhxmdw/test_with_system.jsonl"
Uma amostra de dados de teste é mostrada abaixo:
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "电话:23204753945:大理市大理市人民路25号 大理古城国际酒店 3号楼:收件者:段丽娟"}, {"role": "assistant", "content": "{\"province\": \"云南省\", \"city\": \"大理市\", ...}"}]}
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "天津市河西区珠江道21号金泰大厦3层 , 接收人慕容修远 , MOBILE:22323185576"}, {"role": "assistant", "content": "{\"province\": \"天津市\", \"city\": \"天津市\", ...}"}]}
2. desenho de indicadores de avaliação
Os critérios de avaliação precisam estar estreitamente alinhados com os objetivos comerciais. Neste exemplo, não só é importante determinar se o resultado é um produto legítimo, mas também se ele é um produto de qualidade. JSONTerei que compará-los um a um. JSON Cada par de chave-valor no
3. avaliação da eficácia do modelo inicial
Em primeiro lugar, na versão sem ajuste fino Qwen3-0.6B modelo foi testado. Mesmo com um Prompt bem projetado e detalhado, sua precisão nas 400 amostras testadas é de apenas 14%。
所有预测完成! 结果已保存到 predicted_labels_without_sft.jsonl
样本数: 400 条
响应正确: 56 条
响应错误: 344 条
评估脚本运行完成
4. validação de modelos ajustados
Em seguida, o modelo ajustado foi avaliado usando o mesmo conjunto de testes. Uma mudança significativa é que agora é possível obter um excelente desempenho com uma palavra-chave muito concisa, pois o conhecimento específico da tarefa é "incorporado" aos parâmetros do modelo, eliminando a necessidade de instruções complexas.
A versão curta da palavra-chave:
你是一个专业的信息抽取助手,专门负责从中文文本中提取收件人的JSON信息,包含的Key有province(省份)、city(城市名称)、district(区县名称)、specific_location(街道、门牌号、小区、楼栋等详细信息)、name(收件人姓名)、phone(联系电话)
Após a execução do script de avaliação, os resultados mostram que a precisão do modelo ajustado atinge o valor de 98%Em um ano de crise, foi dado um salto qualitativo.
所有预测完成! 结果已保存到 predicted_labels.jsonl
样本数: 400 条
响应正确: 392 条
响应错误: 8 条
评估脚本运行完成
Esse resultado prova que a destilação modelo e a LoRA O ajuste fino é uma solução altamente econômica que possibilita a aplicação de modelos pequenos a domínios específicos, eliminando os obstáculos de custo e eficiência para que a tecnologia de IA seja dimensionada.